


Authors:
Luca Rossetto (University of Basel)
Fabian Berns (University of Münster)
Klaus Schoeffmann (University of Klagenfurt)
George Awad (NIST; Dakota Consulting)
Christian Beecks (University of Münster)
Editors: Martha Larson and Bart Thomee
DownloadIn order to download the video dataset as well as its provided analysis data, please follow the instructions described here: https://github.com/klschoef/V3C1Analysis/blob/master/README.md |
Introduction
Standardized datasets are of vital importance in multimedia research, as they form the basis for reproducible experiments and evaluations. In the area of video retrieval, widely used datasets such as the IACC [5], which has formed the basis for the TRECVID Ad-Hoc Video Search Task and other retrieval-related challenges, have started to show their age. For example, IACC is no longer representative of video content as it is found in the wild [7]. This is illustrated by the figures below, showing the distribution of video age and duration across various datasets in comparison with a sample drawn from Vimeo and Youtube.
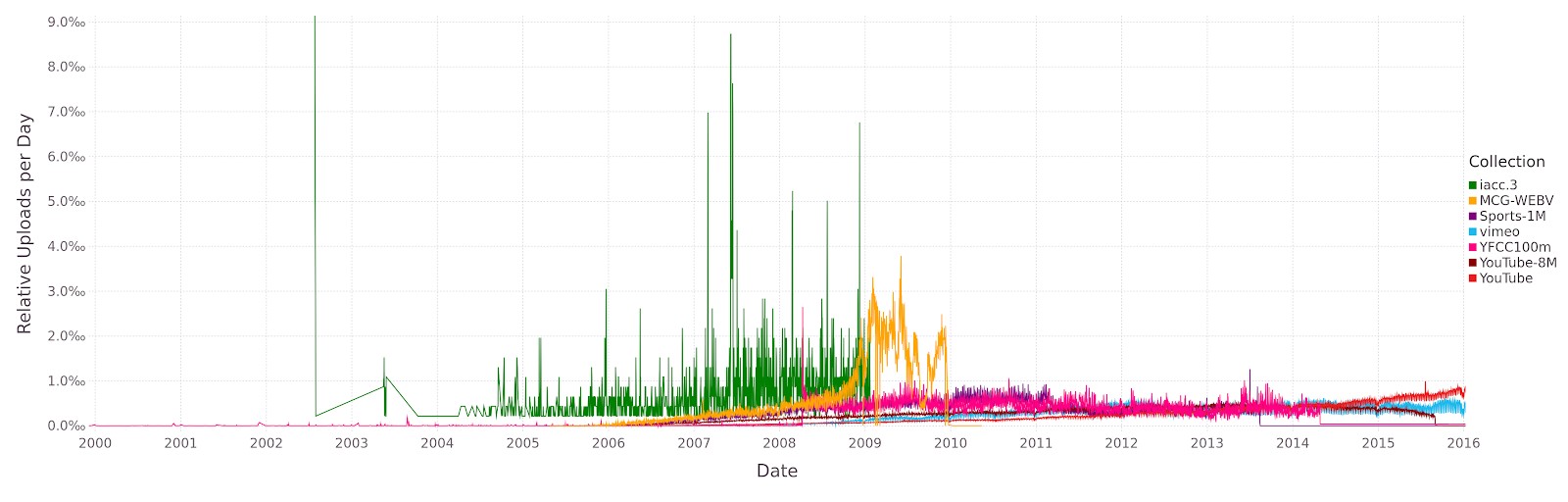
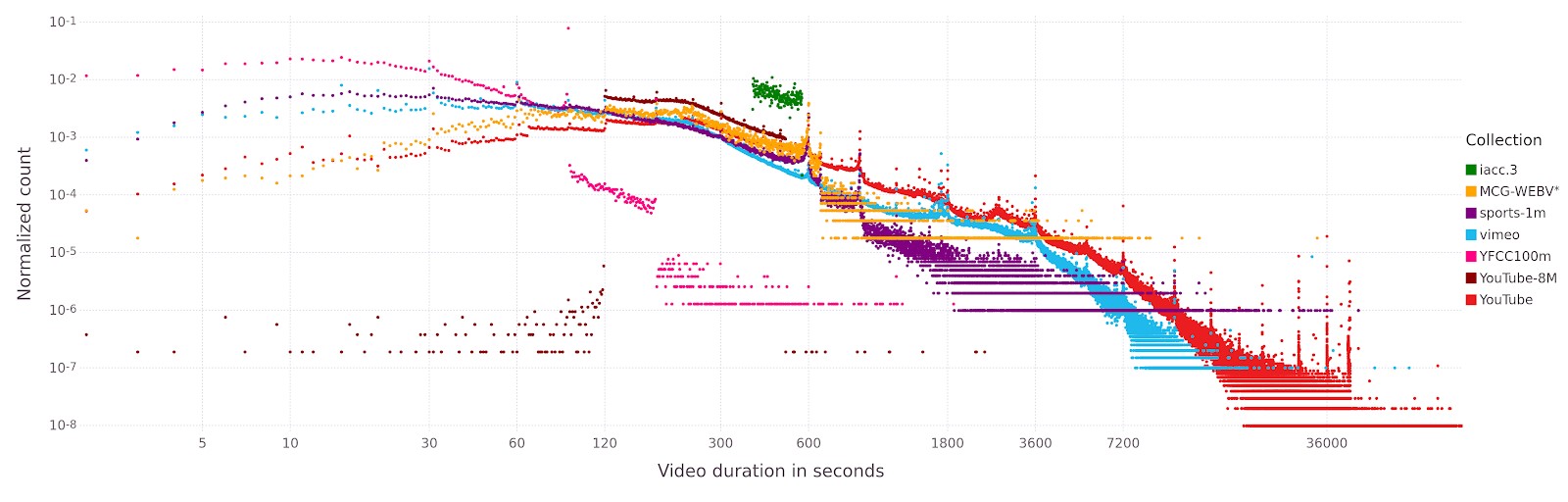
Its recently released spiritual successor, the Vimeo Creative Commons Collection (V3C) [3], aims to remedy this discrepancy by offering a collection of freely reusable content sourced from the video hosting platform Vimeo (https://vimeo.com). The figures below show the age and duration distributions of the Vimeo sample from [7] in comparison with the properties of the V3C.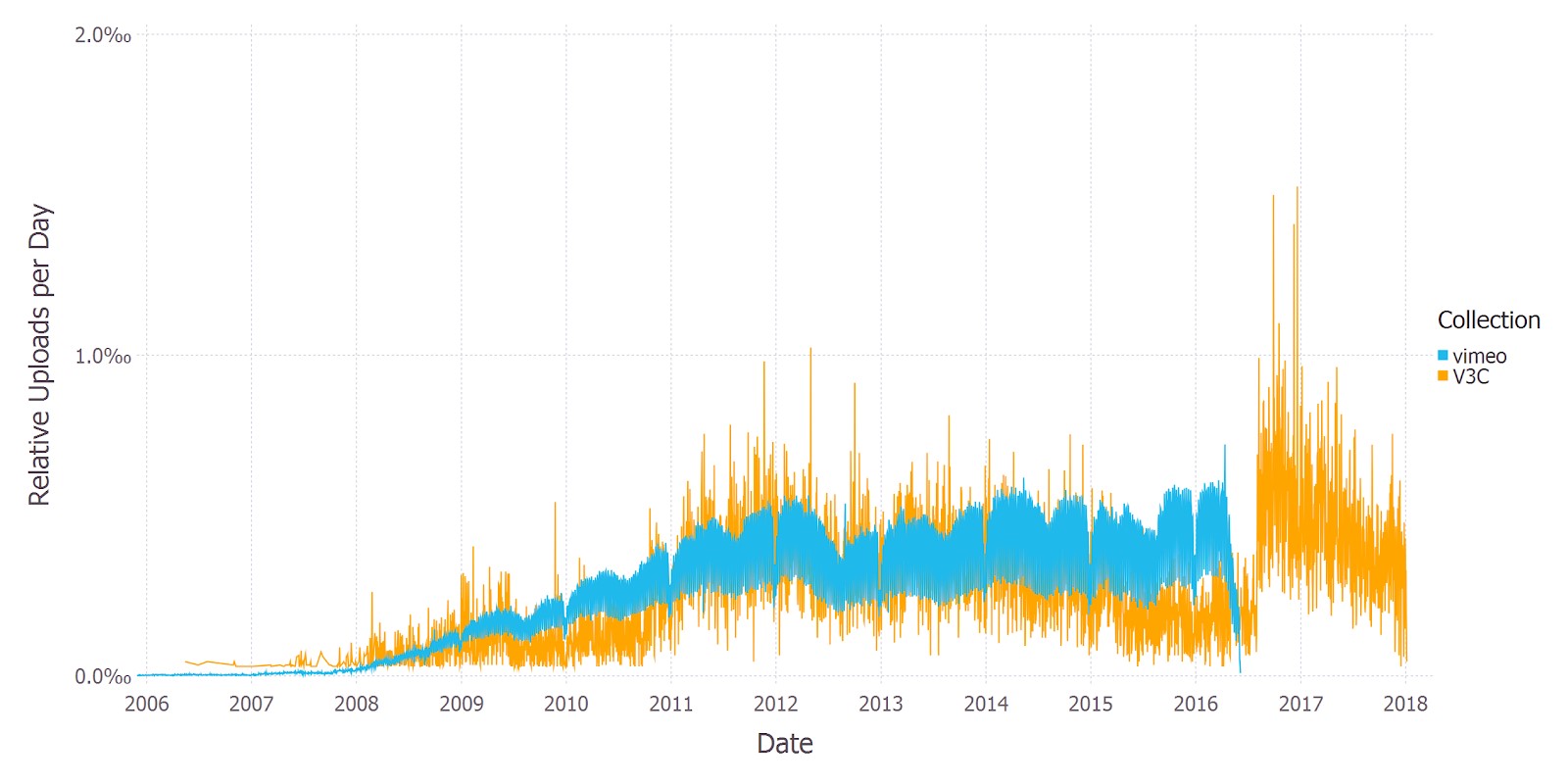

The V3C is comprised of three shards, consisting of 1000h, 1200h and 1500h of video content respectively. It consists not only of the original videos themselves, but also comes with video shot-boundary annotations, as well as representative key-frames and thumbnail images for every such video shot. In addition, all the technical and semantic video metadata that was available on Vimeo is provided as well. The V3C has already been used in the 2019 edition of the Video Browser Showdown [2] and will also be used for the TRECVID AVS Tasks (https://www-nlpir.nist.gov/projects/tv2019/) starting 2019 with a plan for future usage in the coming several years. This video provides an overview of the type of content found within the dataset
Dataset & Collections
The three shards of V3C (V3C1, V3C2, and V3C3) contain Creative Commons videos sourced from video hosting platform Vimeo. For this reason, the elements of the dataset may be freely used and publicly shared. The following table presents the composition of the dataset and the characteristics of its shards, as well as the information on the dataset as a whole.
| Partition | V3C1 | V3C2 | V3C3 | Total |
| File Size (videos) | 1.3TB | 1.6TB | 1.8TB | 4.8TB |
| File Size (total) | 2.4TB | 3.0TB | 3.3TB | 8.7TB |
| Number of Videos | 7’475 | 9’760 | 11’215 | 28’450 |
| Combined
Video Duration |
1’000 hours,
23 minutes, 50 seconds |
1’300 hours,
52 minutes, 48 seconds |
1’500 hours,
8 minutes, 57 seconds |
3801 hours,
25 minutes, 35 seconds |
| Mean Video Duration | 8 minutes,
2 seconds |
7 minutes,
59 seconds |
8 minutes,
1 seconds |
8 minutes,
1 seconds |
| Number of Segments | 1’082’659 | 1’425’454 | 1’635’580 | 4’143’693 |
Similarly to IACC, V3C contains a master shot reference, which segments every video into non-overlapping shots based on the visual content of the videos. For every single shot, a representative keyframe is included, as well as the thumbnail version of that keyframe. Furthermore, for each video, identified by a unique ID, a metadata file is available that contains both technical as well as semantic information, such as the categories. Vimeo categorizes every video into categories and subcategories. Some of the categories were determined to be non-relevant for visual based multimedia retrieval and analytical tasks, and were dropped during the sourcing process of V3C. For simplicity reasons, subcategories were generalized into their parent categories and are, for this reason, not included. The remaining Vimeo categories are:
- Arts & Design
- Cameras & Techniques
- Comedy
- Fashion
- Food
- Instructionals
- Music
- Narrative
- Reporting & Journals
Ground Truth and Analysis Data
As described above, the ground truth of the dataset consists of (deliberately over-segmented) shot boundaries as well as keyframes. Additionally, for the first shard of the V3C, the V3C1, we have already performed several analyses of the video content and metadata in order to provide an overview of the dataset [1].
In particular, we have analyzed specific content characteristics of the dataset, such as:
- Bitrate distribution of the videos
- Resolution distribution of the videos
- Duration of shots
- Dominant color of the keyframes
- Similarity of the keyframes in terms of color layout, edge histogram, and deep features (weights extracted from the last fully-connected layer of GoogLeNet).
- Confidence range distribution of the best class for shots detected by NasNet (using the best result out of the 1000 ImageNet classes)
- Number of different classes for a video detected by NasNet (using the best result out of the 1000 ImageNet classes)
- Number of shots/keyframes for a specific content class
- Number of shots/keyframes for a specific number of detected faces
This additional analysis data is available via GitHub, so that other researchers can take advantage of it. For example, one could use a specific subset of the dataset (only shots with blue keyframes, only videos with a specific bitrate or resolution, etc.) for performing further evaluations (e.g., for multimedia streaming, video coding, but also for image and video retrieval, of course). Additionally, due the public dataset and the analysis data, one could easily create an image and video retrieval system and use it either for participation in competitions like the Video Browser Showdown [2], or for submitting other evaluation runs (TRECVID Ad-hoc Video Search Task).
Conclusion
In the broad field of multimedia retrieval and analytics, one of the key components of research is having useful and appropriate datasets in place to evaluate multimedia systems’ performance and benchmark their quality. The usage of standard and open datasets enables researchers to reproduce analytical experiments based on these datasets and thus validate their results. In this context, the V3C dataset proves to be very diverse in several useful aspects (upload time, visual concepts, resolutions, colors, etc.). Also it has no dominating characteristics and provides a low self-similarity (i.e., few near duplicates) [3].
Further, the richness of V3C in terms of content diversity and content attributes enables benchmarking multimedia systems in close-to-reality test environments. In contrast to other video datasets (cf. YouTube-8M [4] and IACC [5]), V3C also provides a vast number of different video encodings and bitrates per second, so that it enables research focusing on video retrieval and analytical tasks regarding those attributes. The large number of different video resolutions (and to a lesser extent frame-rates) makes this dataset interesting for video transport and storage applications such as the development of novel encoding schemes, streaming mechanisms or error-correction techniques. Finally, in contrast to many current datasets, V3C also provides support for creating queries for evaluation competitions, such as VBS and TRECVID [6].
References
[1] Fabian Berns, Luca Rossetto, Klaus Schoeffmann, Christian Beecks, and George Awad. 2019. V3C1 Dataset: An Evaluation of Content Characteristics. In Proceedings of the 2019 on International Conference on Multimedia Retrieval (ICMR ’19). ACM, New York, NY, USA, 334-338.
[2] Jakub Lokoč, Gregor Kovalčík, Bernd Münzer, Klaus Schöffmann, Werner Bailer, Ralph Gasser, Stefanos Vrochidis, Phuong Anh Nguyen, Sitapa Rujikietgumjorn, and Kai Uwe Barthel. 2019. Interactive Search or Sequential Browsing? A Detailed Analysis of the Video Browser Showdown 2018. ACM Trans. Multimedia Comput. Commun. Appl. 15, 1, Article 29 (February 2019), 18 pages.
[3] Rossetto, L., Schuldt, H., Awad, G., & Butt, A. A. (2019). V3C–A Research Video Collection. In International Conference on Multimedia Modeling (pp. 349-360). Springer, Cham.
[4] Abu-El-Haija, S., Kothari, N., Lee, J., Natsev, P., Toderici, G., Varadarajan, B., & Vijayanarasimhan, S. (2016). Youtube-8m: A large-scale video classification benchmark. arXiv preprint arXiv:1609.08675.
[5] Paul Over, George Awad, Alan F. Smeaton, Colum Foley, and James Lanagan. 2009. Creating a web-scale video collection for research. In Proceedings of the 1st workshop on Web-scale multimedia corpus (WSMC ’09). ACM, New York, NY, USA, 25-32.
[6] Smeaton, A. F., Over, P., and Kraaij, W. 2006. Evaluation campaigns and TRECVid. In Proceedings of the 8th ACM International Workshop on Multimedia Information Retrieval (Santa Barbara, California, USA, October 26 – 27, 2006). MIR ’06. ACM Press, New York, NY, 321-330.
[7] Luca Rossetto & Heiko Schuldt (2017). Web video in numbers-an analysis of web-video metadata. arXiv preprint arXiv:1707.01340.