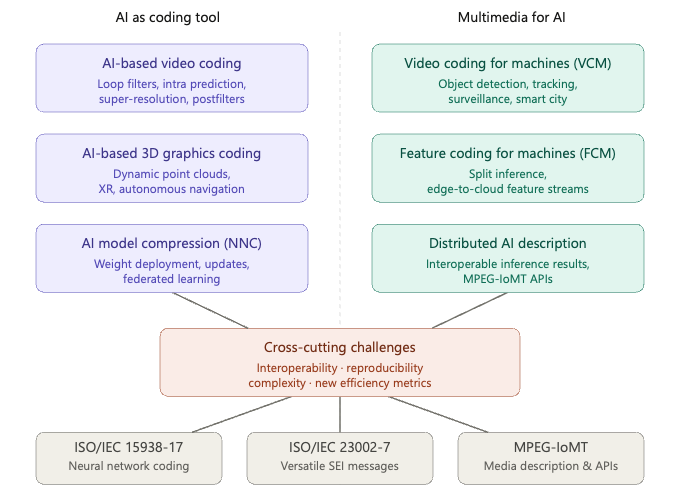
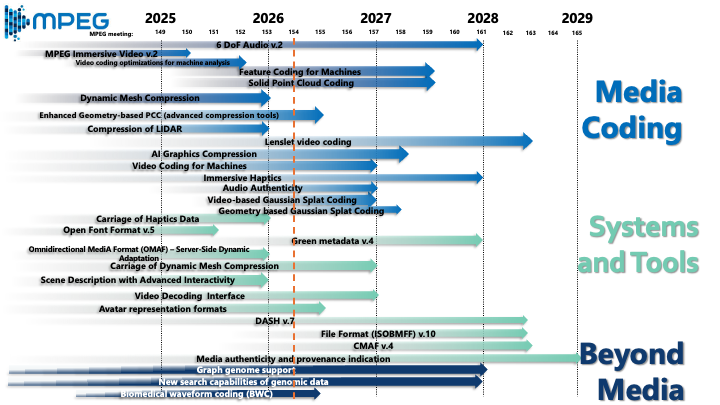
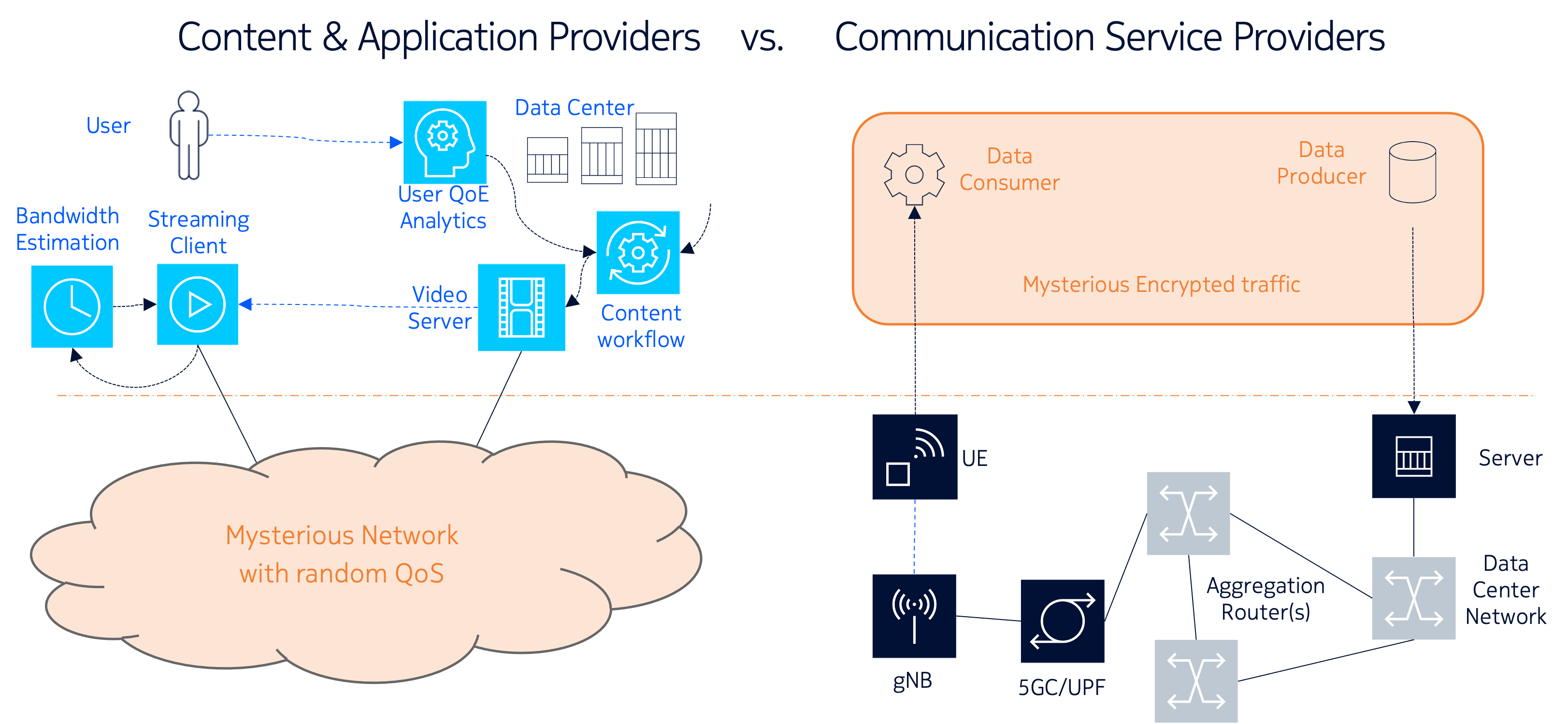
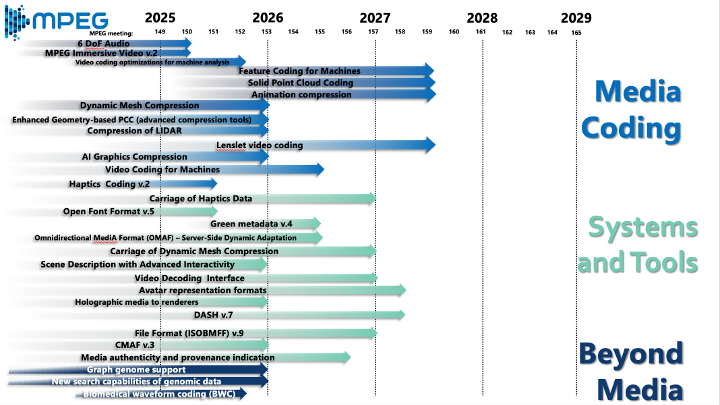
In this Dataset Column, we continue the tradition of previous installments by reviewing notable developments in open datasets and benchmarking competitions in multimedia from 2023 to 2025. The selected events reflect the breadth of topics, challenges, and datasets currently shaping the multimedia research community. They include special sessions, grand challenges, competition tracks, and evaluation campaigns involving multimedia data. This Dataset Column extends a series of overviews previously published in ACM SIGMM Records:
This fifth column focuses on the last three editions of the ACM International Conference on Multimedia (ACM MM), one of the flagship conferences in the field, which has long served as a major venue including presentations of multimedia benchmarks, open datasets, and community-driven evaluation campaigns.
- MM ’23: The 31st ACM International Conference on Multimedia (Ottawa, Canada, 29 October 29 – November 3, 2023)
- MM ’24: The 32nd ACM International Conference on Multimedia (Melbourne, Australia, October 28 – November 1, 2024)
- MM ’25: The 33rd ACM International Conference on Multimedia (Dublin, Ireland, October 27 – 31, 2025)
ACM Multimedia 2022 was reviewed in the Overview of Open Dataset Sessions and Benchmarking Competitions in 2022 – Part 2 (MDRE at MMM 2022, ACM MM 2022), and ACM Multimedia 2024 was reviewed in a general report.
The growing prominence of data-centric research in the multimedia community is illustrated also by the increasing frequency of the term “dataset” in ACM MM proceedings. In paper titles, the term appeared in 9 papers at MM ’22, rising to 22 in MM ’23, 28 in MM ’24, and 106 in MM ’25. In author keywords, the corresponding numbers were 35, 37, 47, and 104, while in abstracts they increased from 438 to 558, 687, and 869, respectively. Notably, among the MM ’25 papers containing the term “dataset”, many were also marked as Artifacts Available (47 in titles, 35 in keywords, and 68 in abstracts), indicating that related research artifacts had been made publicly accessible. Although this is only an approximate indicator, the trend suggests a growing emphasis on datasets, reproducibility, and open research practices within ACM MM.
Across MM ’23, MM ’24, and MM ’25, the term dataset appears in 156 paper titles, 188 author keyword lists, and 2,114 abstracts. Based on these three editions, we present a curated selection of 39 publicly accessible datasets – 10 from MM ’23, 10 from MM ’24, and 19 from MM ’25 – selected for their relevance to multimedia research, diversity of application domains, and potential for reuse by the community.
ACM MM 2023
Numerous dataset-related papers were presented at the 31st ACM International Conference on Multimedia (MM ’23), organized in Ottawa, Canada, October 29 – November 3, 2023. The complete MM ’23: Proceedings of the 31st ACM International Conference on Multimedia are available in the ACM Digital Library (https://dl.acm.org/doi/proceedings/10.1145/3581783).
There was no dedicated dataset session among roughly 33 sessions at the MM ’23 conference. As a small example, ten selected papers focused primarily on new datasets with publicly available data are listed below. Looking across the ACM MM ’23 papers containing “dataset” in the keyword field, the dominant focus is on creating benchmark resources for emerging multimedia tasks rather than merely applying existing datasets. The contributions span a broad range of multimedia domains, including image and video understanding, multimedia quality assessment, multimodal reasoning, user interaction analysis, emotional and social signal processing, immersive media, multimedia security, retrieval, and cross-modal learning. A clear trend is the coupling of dataset construction with benchmark protocols and baseline methods, reflecting the multimedia increasing emphasis on reproducibility, comparative evaluation, and open research resources. From this broader set, the ten examples below were selected based primarily on scientific impact, current relevance, public availability, and representativeness across the core multimedia research themes traditionally associated with ACM MM.
Towards Explainable In-the-Wild Video Quality Assessment: A Database and a Language-Prompted Approach
Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jingwen Hou, Annan Wang, Wenxiu Sun, Qiong Yan, Weisi Lin
Paper available at: https://doi.org/10.1145/3581783.3611737
Dataset available at: https://github.com/VQAssessment/MaxVQA
This work introduces the Maxwell database, a major benchmark for explainable video quality assessment containing 4,543 in-the-wild videos and over two million subjective quality annotations across 13 dimensions. The dataset significantly advances multimedia quality assessment by enabling interpretable analysis of perceptual video quality beyond traditional scalar scoring.
Understanding User Behavior in Volumetric Video Watching: Dataset, Analysis and Prediction
Kaiyuan Hu, Haowen Yang, Yili Jin, Junhua Liu, Yongting Chen, Miao Zhang, Fangxin Wang
Paper available at: https://doi.org/10.1145/3581783.3613810
Dataset available at: https://cuhksz-inml.github.io/user-behavior-in-vv-watching/
This contribution presents one of the first public datasets for volumetric video interaction analysis, including gaze, viewport, and motion behavior. The dataset is highly relevant for immersive multimedia delivery, adaptive streaming, and Quality of Experience optimization in emerging interactive media environments.
TikTalk: A Video-Based Dialogue Dataset for Multi-Modal Chitchat in Real World
Hongpeng Lin, Ludan Ruan, Wenke Xia, Peiyu Liu, Jingyuan Wen, Yixin Xu, Di Hu, Ruihua Song, Wayne Xin Zhao, Qin Jin, Zhiwu Lu
Paper available at: https://doi.org/10.1145/3581783.3612425
Dataset available at: https://ruc-aimind.github.io/projects/TikTalk/
TikTalk provides a large-scale benchmark for video-grounded multimodal dialogue, containing 38,000 videos and 367,000 real-world user conversations. Its scale and realism make it particularly relevant for conversational multimedia AI and multimodal human-computer interaction.
MultiMediate ’23: Engagement Estimation and Bodily Behaviour Recognition in Social Interactions
Philipp Müller, Michal Balazia, Tobias Baur, Michael Dietz, Alexander Heimerl, Dominik Schiller, Mohammed Guermal, Dominike Thomas, François Brémond, Jan Alexandersson, Elisabeth André, Andreas Bulling
Paper available at: https://doi.org/10.1145/3581783.3613851
Dataset available at: https://multimediate-challenge.org/Dataset/
This contribution extends benchmark resources for engagement estimation and bodily behavior recognition in social interactions. The dataset is particularly relevant for multimedia analysis of human communication, behavioral understanding, and socially intelligent interactive systems.
Light-VQA: A Multi-Dimensional Quality Assessment Model for Low-Light Video Enhancement
Yunlong Dong, Xiaohong Liu, Yixuan Gao, Xunchu Zhou, Tao Tan, Guangtao Zhai
Paper available at: https://doi.org/10.1145/3581783.3611923
Dataset available at: https://github.com/wenzhouyidu/Light-VQA
This paper introduces LLVE-QA, a benchmark dataset specifically designed for evaluating perceptual quality in low-light video enhancement. As video enhancement becomes increasingly important in real-world multimedia applications, this dataset fills an important gap between enhancement algorithms and user-centered perceptual evaluation.
SemanticRT: A Large-Scale Dataset and Method for Robust Semantic Segmentation in Multispectral Images
Wei Ji, Jingjing Li, Cheng Bian, Zhicheng Zhang, Li Cheng
Paper available at: https://doi.org/10.1145/3581783.3611738
Dataset available at: https://github.com/jiwei0921/SemanticRT
SemanticRT introduces a large RGB-thermal image benchmark for robust semantic segmentation under adverse environmental conditions. With over 11,000 annotated multispectral image pairs, it provides an important resource for multimodal scene understanding and intelligent visual perception.
MORE: A Multimodal Object-Entity Relation Extraction Dataset with a Benchmark Evaluation
Liang He, Hongke Wang, Yongchang Cao, Zhen Wu, Jianbing Zhang, Xinyu Dai
Paper available at: https://doi.org/10.1145/3581783.3612209
Dataset available at: https://github.com/NJUNLP/MORE
MORE establishes a benchmark for multimodal relation extraction using jointly visual and textual evidence. The dataset addresses a growing need for structured reasoning across multimedia modalities and represents a strong contribution to multimodal understanding.
Ground-to-Aerial Person Search: Benchmark Dataset and Approach
Shizhou Zhang, Qingchun Yang, De Cheng, Yinghui Xing, Guoqiang Liang, Peng Wang, Yanning Zhang
Paper available at: https://doi.org/10.1145/3581783.3612105
Dataset available at: https://github.com/yqc123456/HKD_for_person_search
This paper introduces G2APS, a benchmark for cross-platform person search between UAV and ground surveillance imagery. The dataset is highly relevant for multimedia retrieval, intelligent surveillance, and cross-view visual matching applications.
MEDIC: A Multimodal Empathy Dataset in Counseling
Zhouan Zhu, Chenguang Li, Jicai Pan, Xin Li, Yufei Xiao, Yanan Chang, Feiyi Zheng, Shangfei Wang
Paper available at: https://doi.org/10.1145/3581783.3612346
Dataset available at: https://ustc-ac.github.io/datasets/medic/
MEDIC provides a multimodal benchmark for empathy analysis in face-to-face counseling interactions. The dataset expands multimedia affective computing toward emotionally intelligent systems and richer human-centered interaction modeling.
CCMB: A Large-scale Chinese Cross-modal Benchmark
Chunyu Xie, Heng Cai, Jincheng Li, Fanjing Kong, Xiaoyu Wu, Jianfei Song, Henrique Morimitsu, Lin Yao, Dexin Wang, Xiangzheng Zhang, Dawei Leng, Baochang Zhang, Xiangyang Ji, Yafeng Deng
Paper available at: https://doi.org/10.1145/3581783.3611877
Dataset available at: https://github.com/yuxie11/R2D2
CCMB contributes one of the largest publicly available multimodal vision-language benchmarks, supporting large-scale pretraining and downstream evaluation. Its scale and broad applicability make it a significant resource for multimodal multimedia learning.
ACM MM 2024
Numerous dataset-related papers have been presented at the 32nd ACM International Conference on Multimedia (MM ’24), organized in Melbourne, Australia, October 28 – November 1, 2024. The complete MM ’24: Proceedings of the 32nd ACM International Conference on Multimedia are available in the ACM Digital Library (https://dl.acm.org/doi/proceedings/10.1145/3664647).
There were three specifically dedicated Dataset sessions among roughly 42 sessions at the MM ’24 conference: “Multimodal Datasets, Models & Analytics” (6 papers), “Datasets & Algorithms for Multimedia Analysis” (6 papers), and “Audio-visual Datasets and Applications” (5 papers).
Ten selected papers focused primarily on new datasets or dataset-driven benchmarks are listed below. Looking across the ACM MM ’24 dataset-session papers provided here, the dominant focus shifts strongly toward multimodal foundation models, audiovisual understanding, media authenticity, video safety, and human-centered multimedia applications. Several contributions address emerging risks and opportunities created by generative AI, including deepfake detection, multimedia forgery, safety-aware video generation, and AI-generated image quality. Other works focus on video-centered understanding tasks, such as audio-visual event localization, hateful video detection, video dialogue, and multimodal stance detection. Compared with earlier dataset columns, MM ’24 reflects a clear trend toward datasets designed not only for recognition or retrieval, but also for reasoning, explanation, generation, safety, and robust real-world deployment.
AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset
Zhixi Cai, Shreya Ghosh, Aman Pankaj Adatia, Munawar Hayat, Abhinav Dhall, Tom Gedeon, Kalin Stefanov
Paper available at: https://doi.org/10.1145/3664647.3680795
Dataset available at: https://github.com/ControlNet/AV-Deepfake1M
AV-Deepfake1M is the strongest candidate to highlight first, both for relevance and citation visibility. It provides more than one million videos with content-driven visual, audio, and audiovisual manipulations, supporting both detection and temporal localization of deepfake segments. Its scale and audiovisual nature make it highly relevant for multimedia forensics and trustworthy media analysis.
Identity-Driven Multimedia Forgery Detection via Reference Assistance
Junhao Xu, Jingjing Chen, Xue Song, Feng Han, Haijun Shan, Yu-Gang Jiang
Paper available at: https://doi.org/10.1145/3664647.3680622
Dataset available at: https://github.com/xyyandxyy/IDForge
IDForge introduces an identity-driven multimedia forgery dataset with video shots involving visual, audio, and textual manipulations, together with real reference data for celebrity identities. The paper is especially relevant because it reflects realistic identity-based forgery scenarios and connects dataset design with reference-assisted detection.
GPT4Video: A Unified Multimodal Large Language Model for Instruction-Followed Understanding and Safety-Aware Generation
Zhanyu Wang, Longyue Wang, Zhen Zhao, Minghao Wu, Chenyang Lyu, Huayang Li, Deng Cai, Luping Zhou, Shuming Shi, Zhaopeng Tu
Paper available at: https://doi.org/10.1145/3664647.3681464
GPT4Video contributes dataset resources for video instruction-following, benchmarking, and safety-aware video understanding and generation. It is relevant because it combines video comprehension, generation, and safeguarding, reflecting the growing role of dataset construction in multimodal large language models.
MultiHateClip: A Multilingual Benchmark Dataset for Hateful Video Detection on YouTube and Bilibili
Han Wang, Tan Rui Yang, Usman Naseem, Roy Ka-Wei Lee
Paper available at: https://doi.org/10.1145/3664647.3681521
MultiHateClip focuses on hateful video detection in multilingual and cross-cultural settings. It contains videos from YouTube and Bilibili annotated for hateful, offensive, and normal content, emphasizing the importance of visual, audio, language, and cultural signals in harmful multimedia analysis.
Open-Vocabulary Audio-Visual Semantic Segmentation
Ruohao Guo, Liao Qu, Dantong Niu, Yanyu Qi, Wenzhen Yue, Ji Shi, Bowei Xing, Xianghua Ying
Paper available at: https://doi.org/10.1145/3664647.3681586
Dataset available at: https://github.com/ruohaoguo/ovavss
This work introduces open-vocabulary audio-visual semantic segmentation and builds AVSBench-OV from AVSBench-semantic. It is highly relevant for open-world video understanding because it combines audio cues, visual segmentation, and zero-shot category recognition.
OpenAVE: Moving towards Open Set Audio-Visual Event Localization
Jiale Yu, Baopeng Zhang, Zhu Teng, Jianping Fan
Paper available at: https://doi.org/10.1145/3664647.3681232
Dataset available at: https://github.com/yujialele/OpenAVE
OpenAVE extends audio-visual event localization beyond closed-set recognition. It is important for real-world audiovisual video understanding, where systems must distinguish known events, unknown events, and background segments.
G-Refine: A General Quality Refiner for Text-to-Image Generation
Chunyi Li, Haoning Wu, Hongkun Hao, Zicheng Zhang, Tengchuan Kou, Chaofeng Chen, Lei Bai, Xiaohong Liu, Weisi Lin, Guangtao Zhai
Paper available at: https://doi.org/10.1145/3664647.3681152
Dataset available at: https://github.com/Q-Future/Q-Refine
G-Refine addresses quality refinement for AI-generated images, focusing on both perceptual quality and text-image alignment. It is a strong representative of growing interest in generative media quality, image quality assessment, and practical improvement of text-to-image outputs.
NovaChart: A Large-scale Dataset towards Chart Understanding and Generation of Multimodal Large Language Models
Linmei Hu, Duokang Wang, Yiming Pan, Jifan Yu, Yingxia Shao, Chong Feng, Liqiang Nie
Paper available at: https://doi.org/10.1145/3664647.3680790
Dataset available at: https://github.com/Elucidator-V/NovaChart
NovaChart provides 47,000 chart images and 856,000 chart-related instructions across multiple chart types and tasks. Although not video-centered, it is a strong image-and-language benchmark for visual reasoning, chart understanding, and chart generation.
Multimodal Multi-turn Conversation Stance Detection: A Challenge Dataset and Effective Model
Fuqiang Niu, Zebang Cheng, Xianghua Fu, Xiaojiang Peng, Genan Dai, Yin Chen, Hu Huang, Bowen Zhang
Paper available at: https://doi.org/10.1145/3664647.3681416
Dataset available at: https://github.com/nfq729/MmMtCSD
This paper introduces MmMtCSD, a dataset for multimodal multi-turn conversational stance detection. It is relevant for social multimedia analysis because it models realistic online discussions involving both text and images rather than isolated image-text pairs.
CT2C-QA: Multimodal Question Answering over Chinese Text, Table and Chart
Bowen Zhao, Tianhao Cheng, Yuejie Zhang, Ying Cheng, Rui Feng, Xiaobo Zhang
Paper available at: https://doi.org/10.1145/3664647.3681053
CT2C-QA introduces a multimodal question answering dataset over Chinese text, tables, and charts. It is relevant for evaluating whether multimodal systems can reason across heterogeneous information sources, including visual and structured data.
ACM MM 2025
Numerous dataset-related papers have been presented at the 33rd ACM International Conference on Multimedia (MM ’25), organized in Dublin, Ireland, October 27 – 31, 2025. The complete MM ’25: Proceedings of the 33rd ACM International Conference on Multimedia are available in the ACM Digital Library (https://dl.acm.org/doi/proceedings/10.1145/3746027).
There was a specifically dedicated dataset session among roughly 26 sessions at the MM ’25 conference. This dataset track attracted 263 submissions, of which 123 were accepted. Considering the entire MM ’25 Proceedings, the term “dataset” appears in the title of 106 papers (28 in MM ’24), the keywords of 104 papers (47 in MM ’24), and the abstracts of 869 papers (687 in MM ’24). This substantial year-over-year increase highlights the growing centrality of datasets and benchmark creation in multimedia research, increasingly positioning dataset construction itself as a major scientific contribution rather than merely supporting experimental evaluation.
The ACM MM ’25 dataset papers show a shift toward datasets as primary research contributions. The dominant themes include high-quality video resources for compression, streaming, enhancement, video quality assessment, and QoE; immersive and 3D media datasets for VR, spatial video, 3D Gaussian Splatting, point clouds, and volumetric applications; multimodal and vision-language datasets for reasoning, event grounding, image/video generation, and instruction following; and safety-oriented datasets addressing deepfakes, harmful videos, social engineering, and media authenticity. A second major cluster concerns domain-specific multimedia datasets in medicine, robotics, agriculture, food computing, biometrics, wildlife monitoring, and urban or engineering environments. Overall, the MM ’25 dataset papers reflect a clear expansion from traditional image/video recognition benchmarks toward open resources for generative media evaluation, trustworthy AI, embodied perception, subjective quality assessment, and real-world multimodal decision-making.
Among the ACM MM ’25 papers that explicitly mention datasets and provide publicly accessible artifacts, the following is a curated selection of 20 representative examples chosen for their relevance to the multimedia community, diversity of topics, and availability of reusable public datasets.
Screen Content Video Dataset and Benchmark
Nickolay Safonov, Mikhail Rakhmanov, Dmitriy S. Vatolin
Paper available at: https://doi.org/10.1145/3746027.3758306
Dataset available at: https://videoprocessing.github.io/screen-content-dataset
This dataset focuses on screen-content video scenarios such as screen sharing, desktop streaming, and video conferencing, providing a large benchmark with subjective quality annotations for distorted content. The work is especially relevant for multimedia quality assessment, video compression research, and perceptual QoE modeling in increasingly important screen-based communication environments.
Nature-1k: The Raw Beauty of Nature in 4K at 60FPS
Mohammad Ghasempour, Hadi Amirpour, Christian Timmerer
Paper available at: https://doi.org/10.1145/3746027.3758258
Dataset available at: https://cd-athena.github.io/Nature-1k
Nature-1k provides a large-scale collection of professionally captured 4K 60 fps natural video content designed for modern video processing research. Its scale and quality make it highly relevant for video compression, streaming optimization, super-resolution, enhancement, frame interpolation, and generative video applications.
VIDEA-8K-60FPS Dataset: 8K 60FPS Video Sequences for Analysis and Development
Tariq Al Shoura, Ali Mollaahmadi Dehaghi, Reza Razavi, Mohammad Moshirpour
Paper available at: https://doi.org/10.1145/3746027.3758278
Dataset available at: https://github.com/talshoura/VIDEA-8K-60FPS-Dataset
VIDEA-8K-60FPS addresses the shortage of publicly available ultra-high-resolution video benchmarks by providing native 8K HDR sequences captured at 60 fps. The dataset is particularly valuable for next-generation video coding, scalable streaming, UHD content analysis, and benchmarking computationally intensive multimedia methods.
LEHA-CVQAD: Dataset To Enable Generalized Video Quality Assessment of Compression Artifacts
Aleksandr Gushchin, Maksim Smirnov, Dmitriy S. Vatolin, Anastasia Antsiferova
Paper available at: https://doi.org/10.1145/3746027.3758303
Dataset available at: https://aleksandrgushchin.github.io/lcvqad/
LEHA-CVQAD is a large-scale benchmark specifically designed for studying perceptual degradation caused by video compression artifacts. Its subjective quality annotations and codec diversity make it particularly useful for developing video quality metrics and improving practical codec parameter optimization.
HVEval: Towards Unified Evaluation of Human-Centric Video Generation and Understanding
Sijing Wu, Yunhao Li, Huiyu Duan, Yanwei Jiang, Yucheng Zhu, Guangtao Zhai
Paper available at: https://doi.org/10.1145/3746027.3758299
Dataset available at: https://huggingface.co/datasets/wsj-sjtu/HVEval
HVEval introduces a benchmark for evaluating human-centric video generation and understanding, a rapidly growing topic in generative multimedia research. It combines perceptual quality judgments with semantic evaluation tasks, making it highly relevant for benchmarking generative video systems and multimodal understanding models.
BrokenVideos: A Benchmark Dataset for Fine-Grained Artifact Localization in AI-Generated Videos
Jiahao Lin, Weixuan Peng, Bojia Zi, Yifeng Gao, Xianbiao Qi, Xingjun Ma, Yu-Gang Jiang
Paper available at: https://doi.org/10.1145/3746027.3758305
Dataset available at: https://broken-video-detection-datetsets.github.io/Broken-Video-Detection-Datasets.github.io/
BrokenVideos addresses a critical challenge in AI-generated media by providing fine-grained annotations for artifact localization in synthetic videos. The dataset is highly relevant for trustworthy generative AI, media forensics, and automated video quality assurance.
AEGIS: Authenticity Evaluation Benchmark for AI-Generated Video Sequences
Jieyu Li, Xin Zhang, Joey Tianyi Zhou
Paper available at: https://doi.org/10.1145/3746027.3758295
Dataset available at: https://huggingface.co/datasets/Clarifiedfish/AEGIS
AEGIS provides a large benchmark for evaluating authenticity detection in increasingly realistic AI-generated videos. It is particularly relevant for multimedia security, deepfake detection, and the broader challenge of trustworthy synthetic media verification.
SVD: Spatial Video Dataset
MohammadHossein Izadimehr, Milad Ghanbari, Guodong Chen, Wei Zhou, Xiaoshuai Hao, Mallesham Dasari, Christian Timmerer, Hadi Amirpour
Paper available at: https://doi.org/10.1145/3746027.3758246
Dataset available at: https://cd-athena.github.io/SVD/
SVD introduces a public benchmark for consumer-captured stereoscopic spatial video, reflecting the increasing adoption of immersive video technologies. It is especially relevant for research in spatial video compression, immersive streaming, QoE evaluation, and depth-aware media analysis.
EyeNavGS: A 6-DoF Navigation Dataset and Record-n-Replay Software for Real-World 3DGS Scenes in VR
Zihao Ding, Cheng-Tse Lee, Mufeng Zhu, Tao Guan, Yuan-Chun Sun, Cheng-Hsin Hsu, Yao Liu
Paper available at: https://doi.org/10.1145/3746027.3758265
Dataset available at: https://symmru.github.io/EyeNavGS/
EyeNavGS provides immersive navigation traces, gaze data, and interaction recordings in virtual reality environments built on 3D Gaussian Splatting scenes. The dataset is particularly important for adaptive rendering, viewport prediction, foveated streaming, and immersive interaction research.
UVG-CWI-DQPC: Dual-Quality Point Cloud Dataset for Volumetric Video Applications
Guillaume Gautier, Xuemei Zhou, Thong Nguyen, Jack Jansen, Louis Fréneau, Marko Viitanen, Uyen Phan, Jani Käpylä, Irene Viola, Alexandre Mercat, Pablo Cesar, Jarno Vanne
Paper available at: https://doi.org/10.1145/3746027.3758263
Dataset available at: https://ultravideo.fi/UVG-CWI-DQPC/
This dataset provides paired high-end and consumer-grade point cloud captures for volumetric video research. It is highly relevant for point cloud compression, enhancement, quality assessment, and immersive multimedia benchmarking.
The CASTLE 2024 Dataset: Advancing the Art of Multimodal Understanding
Luca Rossetto, Werner Bailer, Duc-Tien Dang-Nguyen, Graham Healy, Björn Þór Jónsson, Onanong Kongmeesub, Hoang-Bao Le, Stevan Rudinac, Klaus Schöffmann, Florian Spiess, Allie Tran, Minh-Triet Tran, Quang-Linh Tran, Cathal Gurrin
Paper available at: https://doi.org/10.1145/3746027.3758199
Dataset available at: https://castle-dataset.github.io/
CASTLE is a rich multimodal dataset combining egocentric and exocentric video, audio, and sensor streams captured in realistic environments. It is highly relevant for multimodal understanding, retrieval, lifelogging, embodied perception, and context-aware AI research.
OpenEvents V1: Large-Scale Benchmark Dataset for Multimodal Event Grounding
Hieu Nguyen, Phuc-Tan Nguyen, Thien-Phuc Tran, Minh-Quang Nguyen, Tam V. Nguyen, Minh-Triet Tran, Trung-Nghia Le
Paper available at: https://doi.org/10.1145/3746027.3758264
Dataset available at: https://ltnghia.github.io/eventa/openevents-v1
OpenEvents V1 provides a large benchmark for multimodal event understanding through aligned images, text, and news content. It is especially relevant for event retrieval, multimodal reasoning, news analysis, and contextual multimedia understanding.
StreamingCoT: A Dataset for Temporal Dynamics and Multimodal Chain-of-Thought Reasoning in Streaming VideoQA
Yuhang Hu, Zhenyu Yang, Shihan Wang, Shengsheng Qian, Bin Wen, Fan Yang, Tingting Gao, Changsheng Xu
Paper available at: https://doi.org/10.1145/3746027.3758311
Dataset available at: https://github.com/Fleeting-hyh/StreamingCoT
StreamingCoT focuses on temporal reasoning in evolving video streams and introduces explicit multimodal reasoning annotations. The dataset is particularly relevant for streaming video understanding, video question answering, and multimodal reasoning research.
SynthVLM: Towards High-Quality and Efficient Synthesis of Image-Caption Datasets for Vision-Language Models
Zheng Liu, Hao Liang, Bozhou Li, Wentao Xiong, Chong Chen, Conghui He, Wentao Zhang, Bin Cui
Paper available at: https://doi.org/10.1145/3746027.3758222
Dataset available at: https://github.com/starriver030515/SynthVLM
SynthVLM introduces a synthetic image-caption dataset aimed at efficient vision-language model training. The work is particularly relevant because it addresses scalable multimodal data generation and benchmarking for next-generation multimodal foundation models.
UniSVG: A Unified Dataset for Vector Graphic Understanding and Generation with Multimodal Large Language Models
Jinke Li, Jiarui Yu, Chenxing Wei, Hande Dong, Qiang Lin, Liangjing Yang, Zhicai Wang, Yanbin Hao
Paper available at: https://doi.org/10.1145/3746027.3758269
Dataset available at: https://ryanlijinke.github.io/
UniSVG expands multimedia benchmarking into vector graphics, a modality often neglected in conventional multimedia datasets. It is highly relevant for multimodal reasoning, structured content understanding, and AI-driven graphic generation.
RoboAfford: A Dataset and Benchmark for Enhancing Object and Spatial Affordance Learning in Robot Manipulation
Yingbo Tang, Lingfeng Zhang, Shuyi Zhang, Yinuo Zhao, Xiaoshuai Hao
Paper available at: https://doi.org/10.1145/3746027.3758209
Dataset available at: https://roboafford-dataset.github.io/
RoboAfford bridges multimedia perception and embodied intelligence through object and spatial affordance annotations for robotic manipulation. The dataset is particularly relevant for scene understanding, multimodal perception, and interaction-aware robotics research.
GynSurg: A Comprehensive Gynecology Laparoscopic Surgery Dataset
Sahar Nasirihaghighi, Negin Ghamsarian, Leonie Peschek, Matteo Munari, Heinrich Husslein, Raphael Sznitman, Klaus Schoeffmann
Paper available at: https://doi.org/10.1145/3746027.3758267
Dataset available at: https://ftp.itec.aau.at/datasets/GynSurge/
GynSurg provides richly annotated surgical video data for gynecological laparoscopic procedures. It is highly relevant for medical multimedia analysis, workflow understanding, semantic segmentation, and AI-assisted surgical support systems.
DFBench: Benchmarking Deepfake Image Detection Capability of Large Multimodal Models
Jiarui Wang, Huiyu Duan, Juntong Wang, Jia Ziheng, Woo Yi Yang, Xiaorong Zhu, Yu Zhao, Jiaying Qian, Yuke Xing, Guangtao Zhai, Xiongkuo Min
Paper available at: https://doi.org/10.1145/3746027.3758204
Dataset available at: https://github.com/IntMeGroup/DFBench
DFBench introduces a large benchmark for evaluating deepfake detection with modern multimodal models. It is especially relevant for multimedia forensics, trustworthy AI, adversarial robustness, and authenticity verification research.
Multiverse Through Deepfakes: The MultiFakeVerse Dataset of Person-Centric Visual and Conceptual Manipulations
Parul Gupta, Shreya Ghosh, Tom Gedeon, Thanh-Toan Do, Abhinav Dhall
Paper available at: https://doi.org/10.1145/3746027.3758283
Dataset available at: https://github.com/Parul-Gupta/MultiFakeVerse
MultiFakeVerse extends deepfake benchmarking beyond simple identity swaps toward semantically meaningful person-centric manipulations. The dataset is particularly important for studying higher-level multimedia misinformation, contextual authenticity analysis, and robust deepfake detection.
The progression across ACM MM 2023-2025 clearly illustrates the evolution of datasets from supporting experimental resources toward primary research outputs in their own right. Beyond traditional benchmarks for recognition and retrieval, recent datasets increasingly target generative media evaluation, trustworthy AI, immersive environments, multimodal reasoning, and domain-specific real-world applications. This trajectory reflects the multimedia community’s growing commitment to reproducibility, open science, and shared evaluation resources that enable sustainable scientific progress.