Introduction
The Video Quality Experts Group (VQEG) fall plenary meeting took place online from December 15th to 19th 2025. More than 130 participants registered to the meeting, coming from industry and academic institutions worldwide.
The meeting was dedicated to present updates and discuss about topics related to the ongoing projects within VQEG. All the related information, minutes, and files from the meeting are available online in the VQEG meeting website, and video recordings of the meeting are available in Youtube.
Several of the addressed topics can be of interest for the SIGMM community working on quality assessment, such as the shift toward Artificial Intelligence (AI) and neural-based media processing, requiring updated evaluation methodologies; the increasing emphasis on immersive media and XR systems, including the recently published recommendation ITU-T P.1321; the growing interest in user-centric Quality of Experience (QoE) modeling, including individualized quality prediction; and the continued development of datasets, tools, and statistical frameworks for reproducible research.
Readers of these columns interested in the ongoing projects of VQEG are encouraged to subscribe to their corresponding reflectors to follow the activities going on and to get involved in them
Overview of VQEG Projects
Immersive Media Group (IMG)
The IMG group continues its focus on quality assessment for immersive technologies. In this meeting, Marta Orduna (Nokia XR Lab, Spain) and Jesús Gutiérrez (Universidad Politécnica de Madrid, Spain) reported updates on the multi-laboratory test plan and next steps for immersive communication assessment. In this sense, a major achievement of the group was the publication of the recommendation ITU-T P.1321 “Interactive test methods for subjective assessment of extended reality communications”, approved in October 2025. In addition, the following presentations related to IMG topics were delivered:
- Felix Immohr (RWTH Aachen University, Germany) introduced the ICS-MR dataset, providing standardized conversational scenarios for evaluating mixed reality communication systems.
- Jakob Hartbrich and William Menz (RWTH Aachen University and TU Ilmenau, Germany) analyzed how encoding parameters, such as texture resolution and polygon count influence the perceived quality of volumetric avatars, showing that texture resolution and quality level are dominant factors.
- Daniel Zielasko (Technical University of Denmark, Denmark) presented a cross-laboratory initiative to establish standardized evaluation protocols for cybersickness, aiming to improve reproducibility and enable large-scale datasets.
- Another contribution focused on datasets and evaluation tools. Abhinav Bhattacharya (RWTH Aachen University, Germany) introduced AMIS, a multimodal dataset for eXtended Reality (XR) research including multiple representation formats, such as talking-head videos, full-body videos, volumetric avatars, and personalized animated avatars.
- An additional work explored teleoperation and user experience, with Shirin Rafiei (RISE, Sweden) presenting a study showing that latency and field of view significantly impact user performance, while video quality mainly affects subjective confidence.
Statistical Analysis Methods (SAM)
The group SAM presented several contributions focused on their main topics, which are data analysis, subjective evaluation, and statistical modeling:
- Ryan Lei (Meta, USA) provided an update on AV2 common test conditions and coding gains, including both subjective and objective evaluation methodologies.
- Lucjan Janowski (AGH University of Krakow, Poland) introduced a simulation framework for evaluating subject screening methods, demonstrating that correlation-based approaches outperform traditional kurtosis-based techniques.
- Dietmar Saupe (University of Konstanz, Germany) proposed the use of G-test statistical methods for validating models in subjective quality datasets, improving reliability in quality scale reconstruction.
- A discussion led by Robert Grosso (NTIA/ITS, USA) addressed open challenges in crowdsourcing-based subjective quality evaluation, including whether such approaches can replace standardized lab-based methodologies.
Joint Effort Group (JEG) – Hybrid
The group JEG addresses several areas of Video Quality Assessment (VQA), and in this meeting it provided contributions focused on advanced modeling of perceptual quality and subjective evaluation methods. In particular, Lohic Fotio Tiotsop (Politecnico di Torino, Italy) introduced a novel attention-based model for predicting individual perceived image coding quality, moving beyond Mean Opinion Score (MOS) toward personalized QoE modeling. In a second contribution, he also presented ongoing work on the evaluation of high-resolution image quality, highlighting variability in no-reference metrics and the need for subjective validation.
Emerging Technologies Group (ETG)
The ETG group continued to highlight forward-looking topics in multimedia. In this meeting:
- Abhijay Ghildyal, Saman Zadtootaghaj, and Nabajeet Barman (Sony Interactive Entertainment, Germany and USA) proposed a non-aligned reference image quality assessment framework for novel view synthesis, addressing the challenge of quality evaluation when pixel-perfect references are unavailable.
- Mathias Wien (RWTH Aachen University, Germany) presented updates on JVET activities, including results from a Call for Evidence (CfE) on next-generation video compression beyond Versatile Video Coding (VVC) and the outlook for future standardization.
Subjective and objective assessment of GenAI content (SOGAI)
The SOGAI group researches on subjective testing methodologies and objective metrics for assessing the quality of GenAI-generated content. In this meeting, the following topcis were presented and discussed:
- Ryan Lei (Meta, USA) presented an evaluation of AI-based image codecs, comparing neural compression approaches with traditional codecs and discussing challenges in measuring compression efficiency.
- Benjamin Herb (TU Ilmenau, Germany) presented a large-scale subjective testing of neural codecs, highlighting that metric reliability is comparable between neural and traditional compression methods.
5G Key Performance Indicators (5GKPI)
The 5GKPI group focuses on networked multimedia systems and QoE modeling. In this meeting, the following contributions were presented:
- Henrique Rossi and Karan Mitra (Lulea University of Technology, Sweden) proposed a Bayesian network framework for analyzing interactivity in cloud gaming, showing that latency is the dominant factor influencing QoE.
- Pablo Pérez (Nokia XR Lab, Spain) presented proposed updates to the QoE definition in ITU-T SG12 recommendation P.10/G.100, raising awareness within VQEG.
- Martín Varela (Metosin, Finland / University of Malaga, Spain) discussed broader concepts of QoE at the system level, including fairness and group-level QoE metrics.
- Finally, François Blouin (Meta, USA) and Pablo Pérez (Nokia XR Lab, Spain) reported on the status and future directions of the VQEG White Paper on QoE management.
Multimedia Experience and Human Factors (MEHF)
The MEHF group contributions address human perception and subjective evaluation challenges. In this meeting the following presentations were delivered:
- Kamran Javidi and Maria Martini (Kingston University London) presented a subjective study on a commercial light field display of the KULF-TT53 Dataset, showing that AV1 encoding outperforms HEVC in perceived quality for light field content.
- Jingwen Zhu investigated resolution cross-over in adaptive streaming of live sports, demonstrating that pairwise comparison (PC) methodologies outperform traditional Absolute Category Rating (ACR) methods for identifying optimal encoding decisions.
Quality Assessment for Computer Vision Applications (QACoViA)
In this meeting, the QACoViA group explored deep learning approaches for image enhancement:
- Mehrunnisa (AGH University of Krakow, Poland) presented a MOS-guided deep learning framework for underwater image enhancement, combining perceptual loss functions with subjective score optimization.
- Doğukan Öztürk (AGH University of Krakow, Poland) further examined deep learning-based enhancement models, comparing multiple approaches for visual quality improvement.
Other updates
Additional presentations covered diverse topics related to quality assessment of audiovisual technologies:
- Kjell Brunnström (RISE, Sweden) presented a study on digital rear-view mirrors highlighting the importance of augmented visual cues for depth perception in automotive systems.
- Werner Robitza (AVEQ, Germany) introduced Videoparser-ng, a fast open-source bitstream parser for model development.
- Margaret Pinson (NTIA/ITS, USA) presented a new camera dataset (JNR-ITScam) containing information from videographers on this video dataset being filmed on modern cameras.
- Syed Uddin (AGH University of Krakow, Poland) presented a segment-Level QoE assessment dataset for adaptive bitrate video streaming.
- Henrique Rossi and Karan Mitra (Lulea University of Technology, Sweden) made a demonstration of ALTRUIST, a multi-platform tool to conduct subjective tests efficiently, for conducting QoE subjective tests in immersive systems.
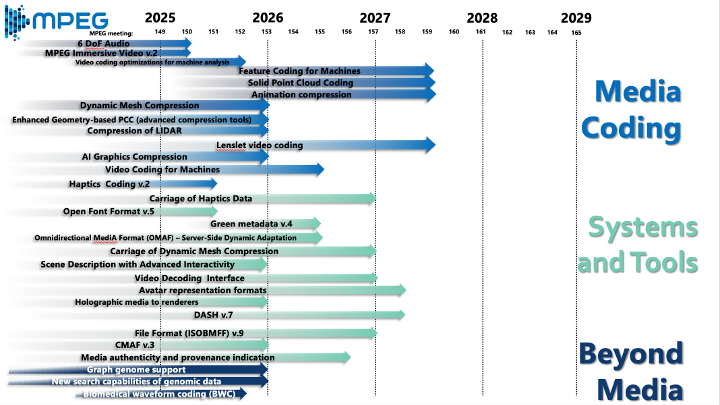
- In terms of standardization efforts, MPEG representatives provided an overview of AG5 activities, including updates on datasets and evaluation methodologies, and there was an ITU-T Q19 interim meeting to discuss progresses on the recommendations of no-reference metrics (J.Noref).
Finally, as announced in the VQEG website, the next face-to-face VQEG plenary meeting was planned for May 2026.