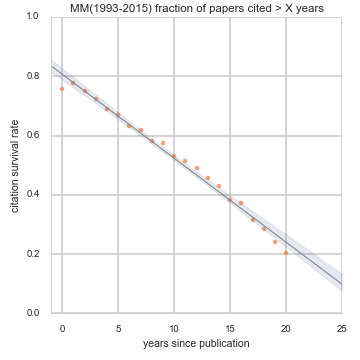
There is no doubt that research in our field has become more data driven. And while the term data science might suggest there is some science without data, it is data the feeds our systems, trains our networks, and tests our results. Recently we have seen examples of a few conferences experimenting with their review process to gain new insights. For those of us in the Multimedia (MM) community, it is not an entirely new thing. In 2013, I led an effort along with my TPC Co-Chairs to look at the past several years of conferences and examine the reviewing system, the process, the scores, and the reviewer load. Additionally, we ran surveys to the authors (accepted and rejected) and the reviewers and ACs to gauge how we did. This was presented at the business meeting in Barcelona along with the suggestion that this practice continues. While this was met with great praise, it was never repeated.
Fast forward to 2017, I found myself asking the same questions about the MM review process which went through several changes (such as the late addition of the “Thematic Workshops” as well as an explicit COI—for papers from the Chairs —which we stated in 2013 could have adverse effects). And, just like before, I requested data from the Director of Conferences and SIGMM chair so I could run an analysis. There are a few things to note about the 2017 data.
- Some reviews were contained in attachments which were unavailable.
- Rebuttals were not present (some chairs allowed them, some did not).
- The conference was divided into a “Regular” set of tracks and a “COI” track for anyone who was on the PC and submitted a paper.
- The Call for Papers was a mixture of “Papers and Posters”.
Finally, the Program Committee accepted 189 out of 684 submissions, yielding an acceptance rate of 27.63 percent. Among the 189 accepted full papers, 49 are selected to give oral presentations on the conference, while the rest are arranged to present to conference attendees in a poster format.
| Track | Reviewed | Accepted | Rate |
| Main Paper | 684 | 189 | 27.63% |
| Thematic Workshop | 495 | 64 | 12.93% |
In 2017, in a departure from previous years, the chairs decided to invite roughly 9% of the accepted papers for an oral presentation with the remaining accepts delegated to a larger poster session. During the review process, to be inclusive, a decision was made to invite some of the rejected papers to a non-archival Thematic workshop where their work could be presented as posters in a non-archival format such that the article can be published elsewhere at a future date. The published rates for these Thematic workshop was 64/495 or roughly 13% of the rejected papers. To dive in further, first, we compute the accepted orals and posters against the total submitted. Second, amongst the rejected papers, we compute the percent of rejects that were invited to a Thematic Workshop. However in the dataset there were 113 papers invited for Thematic Workshops; 49 of these did not make it into the program as the authors refused the automatic enrollment invitation.
| Normal | COI | Normal Rate | COI Rate | |
| Oral | 41 | 8 | 7.03% | 7.92% |
| Poster | 123 | 17 | 21.1% | 16.83% |
| Workshop | 79 | 34 | 18.85% | 44.74% |
| Reject | 339 | 42 | 58.15% | 41.58% |
Comparing the Regular and COI tracks, we find the scores to be correlated (p<0.003) if the workshops are treated as rejects. Including the workshops into the calculation shows no correlation (p<0.093). To further examine this, we plotted the percent decision by area and track.

While one must remember the numbers by volume are smaller in the COI track, some inflation will be seen here. Again, by percentage, you can see Novel Topics – Privacy and Experience – Novel Interactions have a higher oral accept rate while Understanding Vision & Deep Learning and Experience Perceptual pulled in higher Thematic Workshop rates.
No real change was seen in the score distribution across the tracks and areas (as seen here in the following jitter plots).


For the review lengths, the average size by character was 1452 with an IQR of 1231. Some reviews skewed longer in the Regular track but they still are outliers for the most part. The load averaged around 4 papers per reviewer with some normal exception. The people depicted with more than 10 papers were TCP members or ACs.
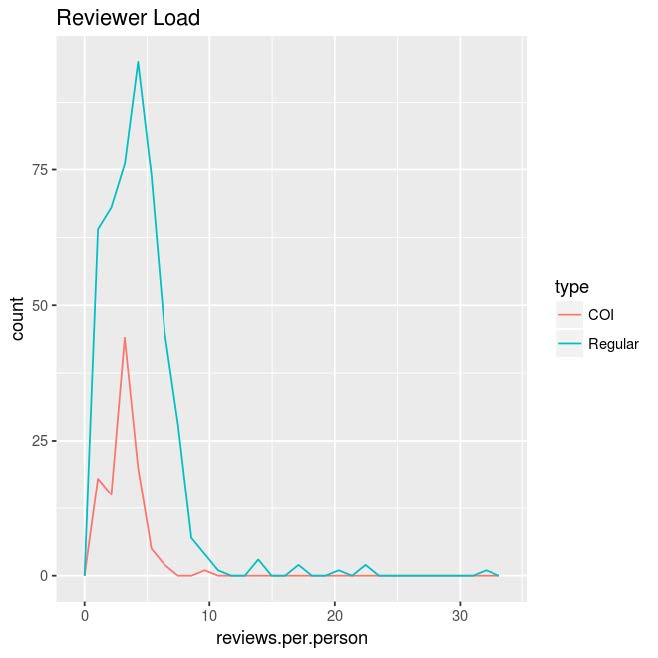
Overall, there is some difference but still a correlation between the COI and Regular tracks and the average number of papers per reviewer was kept to a manageable number. The score distributions roughly seems similar with the exception of the IQR but this is likely more product of the COI track being smaller. For the Thematic Workshops thereʼs an inflation in the accept rate for the COI track: accepting at 18.85% for the regular submissions but 44.74% for the COI. This was dampened by authors rejecting the Thematic Workshop invitation. Of the 79 Regular Workshop invitations and 34 COI invitations, only 50 regular and 14 COI were in the final program. So the final accept rates for what was actually at the conference became 11.93% for Regular Thematic workshop submissions and 18.42% for COI.
So where do we go from here?
Removal of a COI track. A COI track comes and goes in ACM MM and it seems its removal is at the top of the list. Modern conference management software (EasyChair, PCS, CMT, etc.) handles conflicts extremely well already.
TCP and ACs must monitor reviews. Next, while quantity is not related to quality, a short review length might be an early indicator of poor quality. TCP Chairs and ACs should monitor these reviews because a review of 959 characters is not particularly informative despite it being positive or negative (in fact this paragraph is almost as long as the average review). While some might believe trapping that error is the job of the authors and the Author Advocate (and hence the authors who need to invoke the Advocate), it is the job of the ACs and the TPC to ensure review quality and make sure the Advocate never gets invoked (as we presented the role back when we invented it in 2014).
CMS Systems Need To Support Us. There is no shortage of Conference Management Systems (CMS); none of them are data-driven. Why do I have to export a set of CSVs from a conference system then write R scripts to see there are short reviews? Yelp and TripAdvisor give me guidance on how long my review should be, how is it that a review for ACM MM can be two short sentences?
Provide upfront submission information. The Thematic Workshops were introduced late into the submission process and came as a surprise to many authors. While some innovation in the Technical program is a good idea, the decline rate showed it was undesirable. Some a priori communication with the community might give insights into what experiments we should try and what to avoid. Which falls into the final point.
We need a New Role. And while the SIGMM EC has committed to looking back at past conferences, we should continue this practice routinely. Conferences or ideally the SIGMM EC should create a “Data Health and Metrics” role (or assign this to the Director of Conferences) to continue to oversee the TPC as well as issue post-review and post-conference surveys to learn how we did at each step and ensure we can move forward and grow our community. However, if done right, it will be considerable work and should likely be its own role.
To get started, the SIGMM Executive Committee is working on obtaining past MM conference datasets to further track the history of the conference in a data-forward method. Hopefully youʼll hear more at the ACM MM Business Meeting and Town Hall in Seoul; SIGMM is looking to hear more from the community.
![Figure 1. Screenshot from SoundCloud showing a list of timed comments left by listeners on a music track [11].](http://sigmm.hosting.acm.org/wp-content/uploads/2018/03/figure1_datasets.png)
![Figure 2. Screenshot from SoundCloud indicating the useful information present in the timed comments. [11]](http://sigmm.hosting.acm.org/wp-content/uploads/2018/03/figure2_datasets1.png)
![Figure 3. Screenshot from SoundCloud indicating the noisy nature of timed comments [11].](http://sigmm.hosting.acm.org/wp-content/uploads/2018/03/figure3_datasets1.png)