ConfFlow is an application to encourage people with similar or complementary research interests to find each other at conferences. How scientific collaborations are initiated, how people meet and how an intention is developed to work together is an open question. The aim of this follow-up initiative to ConfLab: Meet the Chairs! held at ACM MM 2019 (conflab.ewi.tudelft.nl) is to help people in the multimedia community to connect with potential collaborators.
As a community, Multimedia is so diverse that it is easy for community members to miss out on very useful expertise and potentially fruitful collaborations. There is a lot of latent knowledge and potential synergies that could exist if we were to offer conference attendees an alternative perspective on their similarities to other attendees. As researchers, we typically find connections through talking to people at the conference either through scientific presentations, personal introductions, or by chance.
The aim of ConfFlow is to allow attendees to browse their similarity to other attendees by harvesting publicly available information about them related to their research interests. Depending on the richness of experience that users are looking for, ConfFlow aims to offer an alternative way for researchers to make new research connections with a similar space. At the basic level, we define the similarity of attendees with an approach similar to paper-reviewer assignment tools, such as the Toronto Paper Matching System (TPMS). Usually, TPMS is used to match reviewers to papers. In an analogous way, ConfFlow creates a visualised similarity space using the publications of the conference attendees. This will allow attendees to interactively explore and find new connections with researchers with complementary research interests (or similar ones). More details about ConfFlow can be found in the associated demo paper [1]. An example snapshot of the application is shown in Figure 1 below.
ConfFlow was funded by the SIGMM special initiatives fund which supports initiatives related to boosting excellence and strength of SIGMM, addressing opportunities for growth in the community and SIGMM related activities, as well as nurturing new talent. The aim of ConfFlow is to target building on excellence, strengths, and community.
Figure 1: Visualisation of ConfFlow
This report records our experience and practical issues related to running ConfFlow at ACM Multimedia last year.
Method
Privacy and Ethical Practices
The aim of ConfFlow was to adhere to the highest levels of ethical practice. One of the debates online relates to what is considered private data. One could consider that deriving novel information from publicly available data can still be considered an invasion of privacy [2]. So ConfFlow was proposed and designed to be opt-in only. This means that unlike the visualisation seen in Figure 1, all the identities for anyone visiting the ConfFlow application appeared as just an icon unless the person had activated their account and gave permission for others to see it. While this might seem quite strict, there can be unforeseen privacy related questions when social information is extracted from publicly available information as those who do not choose to opt-in can still become exposed.
Due to this opt-in strict procedure, we needed to find an active way to engage conference attendees by advertising the application through the conference and also getting access to the conference attendee list so we could target and encourage those people to activate their accounts. This required close coordination with the General Chairs of ACM Multimedia 2020.
Application Realization
ConfFlow was rolled out at ACM Multimedia 2020 for conference attendees. Shortly after the building of this application was approved, the Corona Virus pandemic hit and ACM Multimedia became a virtual conference. Since the embedding space of ConfFlow needs to be built apriori, we needed to have access to the conference attendee list. The workload for the conference organisers increased significantly as a result of the pandemic so we did not manage to get the logistical support to optimise the impact of the application. Since we could not get this, we defaulted to visualising the much larger accepted author list. Each identity in ConfFlow needs to be manually verified which also takes considerable effort.
However, there remained the issue that the application was opt-in. For those who tested the application, they were disappointed because many people were not visible. Many of the authors in any case did not attend the conference, which exacerbated the sparsity issue. Advertising ConfFlow and encouraging participants to activate their account was extremely hard due to the virtual format of the conference and because it was hard to reach the actual conference attendees.
The demo paper for the application was presented at ACM Multimedia 2020 and received positively.
Discussion and Recommendations
The instantiation of the app was well-received by community members and the SIGMM board. There were some teething problems that we aim to resolve in a follow up to the 2021 edition where we will revise the opt-in policy to something that can allow for a better user experience whilst being careful with individual privacy. We also want to make the possibility for users to connect with people they see in the embedding space directly in the app so that the use of ConfFlow as a social connector tool becomes more explicit. We also plan to focus on different ways to advertise and communicate the application for a wider userbase. Finally, due to the considerable effort required to verify the identities of all individuals in the visualisations, we would like to build a more efficient procedure to make visualisations in future years less manually intensive. To this end, the SIGMM board has funded a second edition of ConfFlow in order for these improvements to be made so we can realise the full potential of the idea while also minimising too much additional logistical support from conference general chairs. We look forward to seeing its impact on future research collaborations.
Acknowledgements
ConfFlow was supported in part by the SIGMM New Initiatives Fund and the Dutch NWO funded MINGLE project number 639.022.606. We thank users who gave feedback on the application during prototyping and implementation and the General Chairs of ACM Multimedia 2020 for their support.
References
[1] Ekin Gedik and Hayley Hung. 2020. ConfFlow: A Tool to Encourage New Diverse Collaborations. In Proceedings of the 28th ACM International Conference on Multimedia (MM ’20). Association for Computing Machinery, New York, NY, USA, 4562–4564. DOI:https://doi.org/10.1145/3394171.3414459.
[2] Townsend, L., & Wallace, C, 2016. Social Media Research: A Guide to Ethics.
The 2020 edition of SISAP was planned to be held at IT University of Copenhagen, Denmark, but was converted into an online event due to the on-going pandemic.
A strong technical program was assembled by three program committee co-chairs, 63 program committee members, and 18 additional reviewers. Each of 50 valid submissions, with authors from 22 countries, was reviewed by at least three referees. 31 papers were accepted, 12 of them as short papers. The doctoral symposium accepted 2 papers.
Gallery view from the special session on Artificial Intelligence and Similarity
The program included four regular sessions, the doctoral symposium, and a special session on Artificial Intelligence and Similarity, chaired by Anshumali Shrivastava, with four talks followed by a panel discussion. The technical program was completed with three distinguished keynote speakers:
Marcel Worring from the University of Amsterdam spoke about Interactive Exploration using Hypergraphs. In his engaging presentation, Marcel focused on an interactive exploration of large multimedia collections. He first reviewed recent successes in supporting scalable categorisation, and then highlighted the opportunities provided by the new field of hypergraph learning.
Divesh Srivastava from AT&T Labs-Research spoke about Exploiting Similarity Relationships to Repair Graphs. In an entertaining talk, Divesh showed how similarity concepts are important in data management tasks such as entity resolution and taxonomies for noisy data.
Ilya Razenshteyn from Microsoft Research spoke about Scalable Nearest Neighbor Search for Optimal Transport. The Wasserstein (aka Optimal Transport) distance is a popular similarity measure for structured data domains, modelled as collections of point sets. The talk focused on efficient algorithms for approximating the distance between a pair of point sets, showing both theoretically well-founded and practical results.
The program committee identified five papers as candidates for the best paper award. It was decided to give the award to Vladimir Mic and Pavel Zezula for their paper “Accelerating Metric Filtering by Improving Bounds on Estimated Distances”. The best student paper award was given Erik Thordsen and Erich Schubert for the paper “ABID: Angle Based Intrinsic Dimensionality”. The best doctoral symposium paper award was given to Shima Moghtasedi for the paper “Temporal Similarity of Trajectories in Graphs”. Top papers from the conference were invited for a special issue of the journal Information Systems.
116 participants signed up for the conference, about half of them from Europe and the other half from institutions around the world. Due to generous sponsorships from Springer, Google, and the IT University of Copenhagen, we were able to make registration completely free. To allow participation from many time zones, a condensed schedule was used with a 5-6 hour main time slot each day. Speakers provided pre-recorded long versions of their talks and gave a short, interactive version on Zoom during the conference. Most participants were active, with 30-40 participants on average in poster sessions, and 30-60 in the technical sessions.
To facilitate interaction, there were three poster sessions placed such that it was possible to attend two at reasonable hours in any time zone. There was also a social event, featuring a popular quiz about Copenhagen. For the poster and social events, we used the gather.town platform, in which a small virtual conference venue had been built.
The conference venue in gather.town: poster room
The conference venue in gather.town: room for gatherings
A scene from the Copenhagen quiz during the social event.
Acknowledgements: Many people worked hard to make SISAP 2020 a success, despite the challenging circumstances. We are particularly indebted to the PC chairs Shin’ichi Satoh, Lucia Vadicamo, and Arthur Zimek, the doctoral symposium chair Ilaria Bartolini, the publication chair Fabio Carrara, and our local arrangements chair Julie Tollund.
Towards SISAP 2021:
As is traditional, the venue for SISAP 2021 was unveiled during the social event. SISAP 2021 is planned to be held in Dortmund, Germany, with Erich Schubert as general chair. We hope that by fall of 2021, the pandemic has subsided sufficiently to allow us to travel to Dortmund, but the experience from SISAP 2020 should provide a template for an online event. On behalf of the organisers, we thank all authors and participants for their contributions, and look forward to seeing you all at SISAP 2021!
About SISAP:
The International Conference on Similarity Search and Applications (SISAP) is an annual forum for researchers and application developers in the area of similarity data management. It aims at the technological problems shared by numerous application domains, such as data mining, information retrieval, multimedia, computer vision, pattern recognition, computational biology, geography, biometrics, machine learning, and many others that make use of similarity search as a necessary supporting service.
From its roots as a regional workshop in metric indexing, SISAP has expanded to become the only international conference entirely devoted to the issues surrounding the theory, design, analysis, practice, and application of content-based and feature-based similarity search. The SISAP initiative has also created a repository serving the similarity search community, for the exchange of examples of real-world applications, the source code for similarity indexes, and experimental testbeds and benchmark data sets (http://www.sisap.org). The proceedings of SISAP are published by Springer as a volume in the Lecture Notes in Computer Science (LNCS) series.
The International Conference on Similarity Search and Applications (SISAP) is an annual forum for researchers and application developers in the area of similarity data management. It aims at the technological problems shared by numerous application domains, such as data mining, information retrieval, multimedia, computer vision, pattern recognition, computational biology, geography, biometrics, machine learning, and many others that make use of similarity search as a necessary supporting service.
From its roots as a regional workshop in metric indexing, SISAP has expanded to become the only international conference entirely devoted to the issues surrounding the theory, design, analysis, practice, and application of content-based and feature-based similarity search. The SISAP initiative has also created a repository serving the similarity search community, for the exchange of examples of real-world applications, the source code for similarity indexes, and experimental testbeds and benchmark data sets (http://www.sisap.org). The proceedings of SISAP are published by Springer as a volume in the Lecture Notes in Computer Science (LNCS) series.
The 2019 edition of SISAP was held at the New Jersey Institute of Technology in Newark, New Jersey, USA. Newark is an attractive location in the New York City metropolitan area with easy and convenient travel to and from the conference. The organization was smooth and with a strong technical program assembled by two co-chairs and sixty program committee members. Each paper was reviewed by at least three referees. SISAP 2019 received 42 papers and accepted 12 as full papers (28% acceptance rate). The program was completed with three keynote speakers of high calibre and one panel.
The first keynote speaker was Fabrizio Silvestri, a Software Engineer at Facebook London working in the Search Systems team. The Facebook AI team in London deals with applying artificial intelligence techniques to address societal problems such as the spread of online misinformation, or the integrity of election processes around the world. To do so, the team has developed a set of tools that exploit similarity search technologies to efficiently and effectively run a very high number of classification tasks on a massive set of data. Fabrizio Silvestri’s talk reviewed some of the problems studied and the solutions adopted.
The second keynote speaker was Alexander Tuzhilin, the Leonard N. Stern Professor of Business in the Department of Technology, Operations and Statistics at the Stern School of Business, NYU. Alex Tuzhilin discussed the role of similarity measures in recommender systems. Measures of similarity between users and between items to be recommended to the users lie at the core of many recommendation algorithms, and numerous metrics have been proposed in the recommender systems field since its inception. The talk explored the evolution of various similarity-based measures from the initial class of rating-based measures to the more recently proposed latent metrics and the metric learning methods. It also explored possible future research directions and novel applications of similarity measures in recommender systems.
The third keynote speaker was Dr. Cong Yu, a research scientist and manager at Google Research in New York City. Cong Yu leads the Structured Data Research Group. The group’s mission is to understand and leverage structured data on the Web to enhance user experience for Google products and has been responsible for several impactful products such as WebTables, Structured Snippets, and Fact-Checking at Google. Currently, his group focuses on technical research for news and has been partnering with journalists and policy advisors to combat online misinformation and improve news consumption. The ClaimReview structured data (http://schema.org/ClaimReview) is a successful example of such collaborations and powers various fact check features for Google. This talk described the genesis of ClaimReview and its role in combating online misinformation.
The SISAP 2019 panel was on Deep Learning meets Similarity Search. The panel was moderated by K. Selçuk Candan (Arizona State University, USA). The panellists were James Bailey (University of Melbourne, Australia), Ilaria Bartolini (University of Bologna, Italy), Michael Houle (National Institute of Informatics, Japan) and Stéphane Marchand-Maillet (University of Geneva, Switzerland).
As it is usually the case, SISAP 2019 included a program with papers exploring various similarity-aware data analysis and processing problems from multiple perspectives. The papers presented at the conference in 2019 studied the role of similarity processing in the context of metric search, visual search, nearest neighbour queries, clustering, outlier detection, and graph analysis. Some of the papers had a theoretical emphasis, while others had a systems perspective, presenting experimental evaluations comparing against state-of-the-art methods. An interesting event at the 2019 conference, as well as the two previous editions, was an electronic poster session that included all accepted papers. This component of the conference generated many lively interactions between presenters and attendees, to not only learn more about the presented techniques but also to identify potential topics for future collaboration.
In a tradition that began with the 2009 conference in Prague, extended versions of the top-ranked papers were invited for a Special Issue of the Information Systems journal. A shortlist for the best papers was created from those conference papers nominated by at least one of their 3 reviewers. An award committee of 3 researchers ranked the shortlisted papers, from which a final ranking was decided. The Best Paper Award was presented to Martin Aumüller and Matteo Ceccarello (IT University of Copenhagen, Copenhagen, Denmark) for the paper titled “The Role of Local Intrinsic Dimensionality in Benchmarking Nearest Neighbor Search” during the Conference Dinner. The best paper reconsiders common benchmarking approaches to nearest neighbour search and studies the effect of different local intrinsic dimensionality (LID) distributions on the running time performance of different implementations.
In addition to the excellent conference facilities at NJIT, we had several student volunteers who were ready to help ensure that the logistical aspects of the conference ran smoothly. Our conference banquet was held at the Newark Museum (https://www.newarkmuseum.org), the largest museum of the state of New Jersey. It holds major collections of American art, decorative arts, contemporary art, and arts of Asia, Africa, the Americas, and the ancient world. The participants were given a highlight tour of the museum prior to the banquet held in the Ballantine House. The Ballantine House is part of The Newark Museum since 1937, the house was designed a National Historic Landmark in 1985. Built in 1885 for Jeannette and John Holme Ballantine, of the celebrated Newark beer-brewing family, this brick and limestone mansion originally had 27 rooms, including eight bedrooms and three bathrooms.
SISAP 2019 demonstrated that the SISAP community has a strong stable kernel of researchers, active in the field of similarity search and to fostering the growth of the community. Organizing SISAP is a smooth experience thanks to the support of the Steering Committee and dedicated participants.
The SISAP 2019 Doctoral Symposium provided a forum for PhD students to present their research ideas and receive feedback from senior members of the research community. The Symposium fostered a collaborative environment with constructive discussions that benefited the students.
SISAP 2020 was supposed to be organized in Copenhagen by Martin Aumüller, Björn Þór Jónsson and Rasmus Pagh from the IT University of Copenhagen. But it will become a virtual event because of the COVID-19 pandemic. One of the major challenges of the SISAP conference series is to continue to raise its profile in the landscape of scientific events related to information indexing, database and search systems.
Conor Keighrey (@ConorKeighrey) recently completed his PhD in the Athlone Institute of Technology which aimed to capture and understand the quality of experience (QoE) within a novel immersive multimedia speech and language assessment. He is currently interested in exploring the application of immersive multimedia technologies within health, education and training.
With a warm welcome from Istanbul, Ali C. Begen (Ozyegin University and Networked Media, Turkey) opened MMSys 2020 this year. In light of the global pandemic, the conference has taken a new format being delivered online for the first time. This, however, was not the only first for MMSys, Laura Toni (University College London, UK) is introduced as the first-ever female co-chair for the conference. This year, the organising committee presented gender and culturally diverse line-up of researchers from all around the globe. In parallel, two new grand challenges were introduced on the topics of “Improving Open-Source HEVC Encoding” and “Low-latency live streaming” for the first time ever at MMSys.
The conference attracted paper submissions from a range of multimedia topics including but not limited to streaming technologies, networking, machine learning, volumetric media, and fake media detection tools. Core areas were complemented with in-depth keynotes delivered by academic and industry experts.
Examples of such include Ryan Overbeck’s (Google, USA) keynote on “Light Fields – Building the Core Immersive Photo and Video Format for VR and AR” presented on the first day. Light fields provide the opportunity to capture full 6DOF and photo-realism in virtual reality. In his talk, Ryan provided key insight into the camera rigs and results from Google’s recent approach to perfect the capture of virtual representations of real-world spaces.
Later during the conference, Roderick Hodgson from Amber Video presented an interesting keynote on “Preserving Video Truth: an Anti-Deepfakes Narrative”. Roderick delivered a fantastic overview of the emerging area of deep fakes, and the application platforms which are being developed to detect, what will without a doubt be used as highly influential media streams in the future. Discussion closed with Stefano Petrangeli asking how the concept of deep fakes could be applied within the context of AR filters. Although AR is within its infancy from a visual quality perspective, the future may rapidly change how we perceive faces through immersive multimedia experiences utilizing AR filters. The concept is interesting, and it leads to the question of what future challenges will be seen with these emerging technologies.
Although not the main focus of the MMSys conference, the co-located workshops have always stood out for me. I have attended MMSys for the last three years and the warm welcome expressed by all members of the research community has been fantastic. However, the workshops have always shined through as they provide the opportunity to meet those who are working in focused areas of multimedia research. This year’s MMSys was no different as it hosted three workshops:
NOSSDAV – The International workshop on Network and Operating System Support for Digital Audio and Video
MMVE – The International Workshop on Immersive Mixed and Virtual Environment Systems
With a focus on novel immersive media experiences, the MMVE workshop was highly successful with five key presentations exploring the topics of game mechanics, cloud computing, head-mounted display field of view prediction, navigation, and delay. Highlights include the work presented by Na Wang et. Al (George Mason University) which explored field of view prediction within augmented reality experiences on mobile platforms. With the emergence of new and proposed areas of research in augmented reality cloud, field of view predication will alleviate some of the challenges associated with the optimization of network communication for novel immersive multimedia experiences in the future.
Unlike previous years, conference organisers faced the challenge of creating social events which were completely online. A trivia night hosted on Zoom brought over 40 members of the MMSys community together virtually to test their knowledge against a wide array of general knowledge. Utilizing online the platform “Kahoot”, attendees were challenged with a series of 47 questions. With great interaction from the audience, the event provided a great opportunity to socialise in a relaxing manner much like the real world counterpart!
Leader boards towards the end were close, with Wei Tsang Ooi gaining the first place with a last-minute bonus question! Jean Botev and Roderick Hodgson took second and third place respectively. Events like this have always been a highlight of the MMSys community, we hope to see it take place this coming year in person over some quite beers and snacks!
Mea Wang opened the N2Women Meeting on the 10th of June. The event openly discussed core influential topics such as the separation of work and life needs within the research community. With a primary objective of assisting new researchers to maintain a healthy work and life balance. Overall, the event was a success, the topic of work and life balance is important for those at all stages of their research careers. Reflecting on my own personal experiences during my PhD, it can be a struggle to determine when to “clock out” and when to spend a few extra hours engaged with research. Key members of the community shared their own personal experiences, discussing other topics such the importance of mentoring, as academic supervisors can often become a mentor for life. Ozgu Alay discussed the importance of developing connections at research-orientated events. Those new to the community should not be afraid to spark a conversation with experts in the field, often the ideal approach is to take interest in their work and begin discussion from there.
Lastly, Mea Wang mentioned that the initiative had initially acquired funding for the purpose of travel supports and childcare for those attending the conference. Due to the online nature this year, the supports have now been placed aside for next year’s event. Such funding provides a fantastic opportunity to support the cost of attending an international conference and engage with the multimedia community!
Closing the conference, Ali C. Begen opened with the announcement of the awards. The Best Paper Award was presented by Özgü Alay and Christian Timmerer who announced Nan Jiang et al as the winner for their paper on “QuRate: Power-Efficient Mobile Immersive Video Streaming”. The paper is available for download on the ACM Digital Library at the following link. The conference closed with the announcement of key celebrations for next year as the NOSSDAV workshop celebrates it’s 30thanniversary, and the Packet Video workshop celebrates the 25th anniversary!
Overall, the expertise in multimedia shined through in this year’s ACM MMSys, with fantastic keynotes, presentations, and demonstrations from researchers around the globe. Although there are many benefits to attending a virtual conference, after numerous experiences this year I can’t help but feel there is something missing. Over the past 3 years, I’ve attended ACM MMSys in person as a PhD candidate, one of the major benefits of in person events are social encounters. Although this year’s iteration of ACM MMSys did a phenomenal job at the presentation of these events in the new and unexpected virtual format. I believe that it is these social events which shine through as they provide the opportunity to meet, discuss, and develop professional and social links throughout the multimedia research community in a more relaxed setting.
As a result, I look forward to what Özgü Alay, Cheng-Hsin Hsu, and Ali C. Begen have in store for us at ACM Multimedia Systems 2021, located in the beautiful city of Istanbul, Turkey.
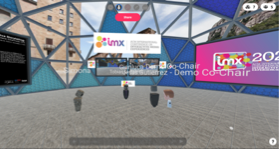
I work in the department of Research & Development, based in London, at the BBC. My interests include Interactive and Immersive Media, Interaction Design, Evaluative Methods, Virtual Reality, Augmented Reality, Synchronised Experiences & Connected Homes. In the interest of full disclosure, I serve on the steering board of ACM Interactive Media Experiences (IMX) as Vice President for Conferences. It was an honour to be invited to the organising committee as one of IMX’s first Diversity Co-Chairs and as a Doctoral Consortium Co-Chair. I will also be the General Co-Chair for ACM IMX 2021. I hope you join us at IMX 2021 but if you need convincing, please read on about my experiences with IMX 2020! I am quite active on Twitter (@What2DoNext), so I don’t think it came as a massive surprise to the IMX community that I won the award of the Best Social Media Reporter for ACM IMX 2020. Here are some of the award-winning tweets describing a workshop, a creative challenge, the opening keynote, my co-author presenting our paper (which incidentally won an honourable mention), the closing keynote and announcing the venue for ACM IMX 2021. This report is a summary of my experiences with IMX 2020.
Before the conference
Summary of activities at IMX 2020.
For the first time in the history of IMX, it was going entirely virtual. As if that wasn’t enough, IMX 2020 was the conference that got rebranded. In 2019, it was called TVX – Interactive Experiences for Television and Online Video! However, the steering committee unanimously voted to rename and rebrand it to reflect the fact that the conference had outgrown its original remit. The new name – Interactive Media Experiences (IMX) – was succinct and all-compassing of the conference’s current scope. With the rebrand, came a revival of principles and ethos. For the first time in the history of IMX, the organising committee worked with the steering committee to include Diversity co-chairs.
The tech industry has suffered from a lack of diverse representation, and 2020 was the year, we decided to try to improve the situation in the IMX community. So, in addition to holding the position of the Doctoral Consortium co-chair, a relatively well-defined role, I was invited to be one of two Diversity chairs. The conference was going to take place in Barcelona, Spain – a city I have been lucky to visit multiple times. I love the people, the culture, the food (and wine) and the city, especially in the summer. The organisation was on track when, due to the unprecedented and global pandemic, we called in an emergency meeting to immediately transfer conference activities to various online platforms. Unfortunately, we lost one keynote, a panel, & 3 workshops, but we managed to transfer the rest into a live virtual event over a combination of platforms: Zoom, Mozilla Hubs, Miro, Slack & Sli.do.
The organising committee came together to reach out to the IMX community to ask for their help in converting their paper, poster and demo presentations to a format suitable for a virtual conference. We were quite amazed at how the community came together to make the virtual conference possible. Quite a few of us spent a lot of late nights getting everything ready!
We set about creating an accessible program and proceedings with links to the various online spaces scheduled to host track sessions and links to papers for better access using the SIGCHI progressive web app and the ACM Publishing System. It didn’t hurt that one of our Technical Program chairs, David A. Shamma, is the current SIGCHI VP of Operations. It was also helpful to have access to the ACM’s guide for virtual conferences and the experience gained by folks like Blair McIntyre (general co-chair of IEEE VR 2020 & Professor at Georgia Institute of Technology). We also got lots of support from Liv Erickson (Emerging Tech Product Manager at Mozilla).
About a week before the conference, Mario Montagud (General Co-Chair) sent an email to all registered attendees to inform them about how to join. Honestly, there were moments when I thought it might be touch and go. I had issues with my network, last-minute committee jobs kept popping up, and social distancing was becoming problematic.
During the conference…
Traditionally, IMX brings together international researchers and practitioners from a wide range of disciplines to attend workshops and challenges on the first day followed by two days of keynotes, panels, paper presentations, posters and demos. The activities are interspersed with lunches, networking with colleagues, copious coffee and a social event.
The advantage of a virtual event is that I had no jet lag and I woke up in my bed at home on the day of the conference. However, I had to provide my coffee and lunches in the 2020 instantiation while (very briefly) considering the option of attending an international conference in my pyjamas. The other early difference is that I didn’t get a name badge in a conference branded registration packet, however, due to my committee roles at IMX 2020, the communications team made us zoom background ‘badges’ – which I loved!
Virtual Backgrounds for use in Zoom.
My first day was exciting and diverse! I had a three-hour workshop in the morning (starting 10 AM BST) titled “Toys & the TV: Serious Play” I had organised with my colleagues Suzanne Clark and Barbara Zambrini from BBC R&D, Christoph Ziegler from IRT and Rainer Kirchknopf from ZDF. We had a healthy interest in the workshop and enthusiastic contributions. A few of the attendees contributed idea/position papers while the other attendees were asked to support their favourite amongst the presented ideas. The groups of people were then sent to a breakout group to work on the concept and produce a newspaper-type summary page of an exemplar manifestation of the idea. We all worked over Zoom and a collaborative whiteboard on Miro. It was the virtual version of an interactive “post-it on a wall” type workshop.
Summary of the IMX 2020 workshop on Toys & the TV: House Rules.
Then it was time for lunch and a cup of tea while managing home learning activities for my kids. Usually, I would have been hunting for a quiet place in the conference venue (depending on the time difference) to facetime with my kids. None of that in 2020! I could chat with my fellow organising committee to make sure things were running smoothly and offer aid if needed. Most of the day’s activities were being efficiently coordinated by Mario, based during the conference, at the i2Cat offices in Barcelona.
Around 4 PM (BST), I had a near four-hour creative challenge meet up. However, before that, I dropped into the IMX in Latin America workshop which was organised by colleagues in (you guessed it) Latin America as a way to introduce the work they do to IMX. Things were going well in that workshop, so after a quick hello to the organisers, I rushed over to take part in the creative challenge!
Screenshots from the IMX 2020 Creative Challenge: Andrés starting proceedings off with while demonstrating his best Snap filter.
The virtual background Mar crafted for us.
The largest Zoom meeting I have ever been a part of.
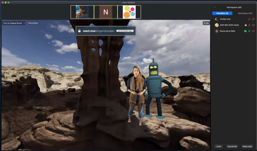
The creative challenge, titled “Snap Creative Challenge: Reimagine the Future of Storytelling with Augmented Reality (AR) ”, was an invited event. It was sponsored by Snap (Andrés Monroy-Hernández) and co-organised by Microsoft Research (Mar González-Franco) and BBC Research & Development (myself). Earlier in the year, over six months, eleven academic teams from eight countries created AR projects to demonstrate their vision of what storytelling would look like in a world where AR is more prevalent. We mentored the teams with the help of Anthony Steed (University College London), Nonny de La Peña (Emblematic Group), Rajan Vaish (Snap), Vanessa Pope (Queen Mary, University of London), and some colleagues who generously donated their time and expertise. We started with a welcome to the event (hosted on Zoom) given by Andrés Monroy-Hernández and then it was straight into presentations of the project. Snap created a summary video of the ideas presented on the day.
IDC Herzliya with a project on Storytelling with AR & IoT devices
UCL with Narrative drive AR companions for kids visiting hospitals
IIIT Delhi with Translating traditional Indian street storytelling to AR
Univ. of Porto with Door Guardians exploring physical doors as triggers for uncovering stories
ENTI-Universitat de Barcelona with the use of shadows as triggers in narrative-based AR & puzzle games
Dalhousie Univ. with a tool for storytellers to turn indoor locations into AR triggers
Virginia Tech with exploring 1st person stories across AR
CMU with converting existing games into immersive AR experiences
Tec de Monterrey with turning sci-fi novels into bite-sized AR games/puzzles to promote reading
ArtCenter with AI-Human partnering to tell AR stories in spatially
UCSB with new design paradigms for creating & sharing AR stories
Each project was distinct, unique and had the potential for so much more development and expansion. The creative challenge was closed by one of the co-founders of Snap (Bobby Murphy). After closing, some teams had office hours where we could go and have an extended chat about the various projects. Everyone was super enthusiastic and keen to share ideas.
It was 8.20 PM, so I had to end the day with my glass of wine with my other half, but I had a brilliant day and couldn’t get over how many interesting people I got to chat to – and it was just the first day of the conference! On the second day of the conference, Christian Timmerer (Alpen-Adria-Universität Klagenfurt & Bitmovin) and I had an hour-long doctoral consortium to host bright and early at 9 AM (BST). Three doctoral students presented a variety of topics. Each student was assigned two mentors who were experts in the field the students were working in. This year, the organising committee were keen to ensure diverse participation through all streams of the conference so, Christian and I kept this in mind in choosing mentors for the doctoral students. We were also able to invite mentors regardless of whether they would travel to a venue or not since everyone was attending online. In a way, it gave us more freedom to be diverse in our choices and thinking. Turns out one hour was whetting the appetite for everyone but the conference had other activities scheduled in the day, so I quite liked having a short break before my next session at noon! Time for another cup of coffee and a piece of chocolate!
Carlos Cortés – Universidad Politécnica de Madrid – talked about his work on “Interaction for Extended Reality environments” (mentored by Daniela Romano – UCL and Teresa Chambel – Univ. of Lisbon)
Wilmer Moina-Rivera – Universitat de València – presented his work on “Video Encoding Cloud System for High Performance Scenarios” (mentored by Lucia D’Acunto – TNO and Ooi Wei Tsang – National University of Singapore)
Simona Manni. – University of York – talked about “Interactive Media and Non-Linear Participatory Narratives of Mental Health” mentored by Bill Gaver – Goldsmiths, University of London and Bill Thompson – BBC R&D
The general chairs (Pablo Cesar – CWI, Mario Montagud & Sergi Fernandez – i2Cat) welcomed everyone to the conference at noon (BST). Pablo gave a summary of the number of participants we had at IMX. This is one of the most unfortunate things in a virtual conference. It’s difficult to get a sense of ‘being together’ with the other attendees at the conference but we got some idea from Pablo. Asreen Rostami (RISE) and I gave a summary of diversity & inclusion activities we put in place through the organisation of the conference to begin the process of improving the representation of under-represented groups within the IMX community. Unfortunately, a lot of the plans were not implemented once IMX 2020 went virtual but some of the guidance to inject diverse thinking into all parts of the conference were still carried out – ensuring that the make-up of the ACs was diverse, encouraging workshop organisers to include a diverse set of participants and use inclusive language, casting a wider net in our search for keynotes and mentors, and selecting a time period to run the conference that was best suited to a majority of our attendees. The Technical Program Co-Chair (Lucia D’Acunto, TNO) gave a summary of how the tracks were populated w.r.t papers. To round off the opening welcome for IMX 2020, Mario gave an overview of communication channels, the tools used and the conference program. The wonderful thing about being in a virtual conference is that you can easily screenshot presentations, so you have a good record of what happened. Under pre-pandemic situations, I would have photographed the slides on a screen on stage from my seat in the auditorium hall. So unfashionable in 2020 – you will agree. Getting a visual reminder of talks is useful if you want to remember key points! It also exceedingly good for illustrations as part of a report you might write about the conference three months later.
Summary of the welcome to IMX 2020 – 1
Summary of the welcome to IMX 2020 – 2
Summary of the welcome to IMX 2020 – 3
Sergi Fernandez introduced the opening keynote: Mel Slater (University of Barcelona) who talked about using Virtual Reality to Change Attitudes and Behaviour. Mel was my doctoral supervisor back in between 2001 and 2006 when I did a PhD at UCL. He was the reason I decided to focus my postgraduate studies to build expressive virtual characters. It was fantastic to “go to a conference with him” again even if he got the seat with the better weather. His opening keynote was engaging, entertaining and gave a lot of food for thought. He also had a new video of his virtual self being a rock star. To this day, I believe this is the main reason he got into VR in the first place! And why ever not?
Some of Mel Slater‘s opening keynote insights at IMX 2020 – 1.
Some of Mel Slater‘s opening keynote insights at IMX 2020 – 2.
Some of Mel Slater‘s opening keynote insights at IMX 2020 – 3.
Immediately after Mels’ talk and Q&A session, it was time to inform attendees about the demos and posters available for viewing as part of the conference. The demos and posters were displayed in a series of Mozilla Hubs rooms (domes) created by Jesús Gutierrez (Universidad Politecnica de Madrid, Demo co-chair) and I, based off some models given to us by Liv (Mozilla). We were able to personalise the virtual spaces and give it a Spanish twist using a couple of panorama images David A. Shamma (FXPAL & Technical Program co-chair for IMX 2020) found on Flickr. Ayman and Julie Williamson (Univ. of Glasgow) also enabled the infrastructure behind the IMX Hub spaces. Jesús and I gave a short ‘how-to’ presentation to let attendees know what to expect in the IMX Hub Spaces. After our presentation, Mario played a video of pitches giving us quick lightning summaries of the demos, work-in-progress poster presentations and doctoral consortium poster displays.
The Poster on Mozilla Hubs in virtual Barcelona for IMX 2020 – 1.
The Poster on Mozilla Hubs in virtual Barcelona for IMX 2020 – 2.
The Demo Domes on Mozilla Hubs in virtual Barcelona for IMX 2020.
I managed to persuade Jesús to take a selfie.
Thirty minutes later, it was time for the first paper session of the day (and the conference)! Ayman chaired the first four papers in the conference in a session titled ‘Augmented TV’. The first paper presented was one I co-authored with Radu-Daniel Vatavu (Univ. Stefan cel Mare of Suceava), Pejman Saeghe (Univ. of Manchester), Teresa Chambel (Univ. of Lisbon), and Marian F Ursu (Univ. of York). The paper (‘Conceptualising Augmented Reality Television for the Living Room’) examined the characteristics of Augmented Reality Television (ARTV) by analysing commonly accepted views on augmented and mixed reality systems, by looking at previous work, by looking at tangential fields (ambient media, interactive TV, 3D TV etc.) and by proposing a conceptual framework for ARTV – the “Augmented Reality Television Continuum”. The presentation is on the ACM SIGCHI’s YouTube channel if you feel like watching Pejman talk about the paper instead of reading it or maybe in addition to reading it!
Ayman and Pejman talking about our paper ‘Conceptualising Augmented Reality Television for the Living Room
I did not present the paper, but I was still relieved that it was done! I have noticed that once a paper I was involved with is done, I tend to have enough headspace to engage and ask questions of other authors. So that’s what I was able to do for the rest of the conference. In that same first paper session, Simon von der Au (IRT) et al. presented ‘The SpaceStation App: Design and Evaluation of an AR Application for Educational Television’ in which they got to work with models and videos of the International Space Station! Now, I love natural history documentaries so when I need to work with content, I don’t think I can go wrong if I choose David Attenborough narrated content – think Blue Planet. However, the ISS is a close second! They also cited two of my co-authored papers – Ziegler et al. 2018 and Saeghe et al. 2019 – which is always lovely to see.
Simon von der Au et al.’s paper on using AR for educational TV – 1.
Simon von der Au et al.’s paper on using AR for educational TV – 2.
Simon von der Au et al.’s paper on using AR for educational TV – 3.
My reaction to Simon von der Au et al.’s paper on using AR for educational TV.
After the first session, we had a 30-minute break before making our way to the Hubs Domes to look at demos and posters. Our outstanding student volunteers were deployed to guide IMX attendees to various domes. It was very satisfying seeing all our Hubs space populated with demos/posters with snippets of conversation flowing past as I passed through the domes to see how folks fared in the space. The whole experience resulted in a lot of selfies and images!
Selfies Galore and a few “candid” shots of others!!!
There were moments of delight throughout the event. I thought I’d rebel against my mom and get pink hair! Pablo got purple hair and IRL he does not have hair that colour (or that uniformly distributed). Ayman and I tried getting some virtual drinks – I got myself a pina colada while Ayman stayed sober. I also visited all the posters and demos which seldom happens when I attend conferences IRL. In Hubs, it was an excellent way to ‘bump into’ folks. I have been in the IMX community for a while, so I was able to recognise many people by reading their floating name labels. Most of their avatars looked nothing like the people I knew! Christian and Omar Niamut (TNO) had more photorealistic avatars but even those were only recognisable if I squinted! I was also very jealous of Omar’s (and Julie’s) virtual hands which they got because they visited the domes using their VR headsets. It was loads of fun seeing how people represented themselves through their virtual clothes, hair and body choice.
All of the demos and posters were well presented but the ‘Watching Together but Apart’ caught my eye because I knew my colleagues Rajiv Ramdhany, Libby Miller, and Kristian Hentschel built ‘BBC Together’ – an experimental BBC R&D prototype to enable people to watch and listen to BBC programmes together while they are physically apart. It was a response to the situation brought to a lot of our doorsteps by the pandemic! It was amazing to see that another research group responded in the same way to build a similar application. It was great fun talking to Jannik Munk Bryld about their project and compare notes.
“Sifter: A Hybrid Workflow for Theme-based Video Curation at Scale” from Univ. of Michigan and Snap Inc.
Once the paper session was over, there was a 45 minutes break to stretch our legs and rest our eyes. Longer in-between session breaks are a necessity in virtual conferences. At 2:30 PM (BST), it was time to listen to two industry talks chaired by Steve Schirra (YouTube) and Mikel Zorrilla (Vicomtech). Mike Darnell (Samsung Electronics America) talked of conclusions he drew from a survey study of hundreds of participants which focused on user behaviour when it came to choosing what to watch on the TV. The main take-home message was that people generally knew in advance exactly what they want to watch on TV.
Industry talk from Samsung – 1.
Industry talk from Samsung – 2.
Industry talk from Samsung – 3.
Industry talk from Samsung – 4.
Natàlia Herèdia (Media UX Design) talked of her pop-up media lab focusing on designing an OTT for a local public channel. She spoke of the process she used and gave a summary of her work on reaching new audiences.
Industry talk from Media UX Design, MediaLab Betevé – 1.
Industry talk from Media UX Design, MediaLab Betevé – 2.
Industry talk from Media UX Design, MediaLab Betevé – 3.
After the industry talk, it was time for a half an hour break. The organising committee and student volunteers went out to the demo domes in Hubs to get a group selfie! We realised that Ayman has serious ambitions when it comes to cinematography. After we got our shots, we attended another paper session chaired by Aisling Kelliher (Virginia Tech) titled ‘Live Production and Audience’. Other people might have mosquitos or mice as a pest problem. In this paper session, I learnt that there are people like Aisling whose pest problems are a little more significant – like bear sized bigger! So many revelations in such a short time!
The first paper of the last session, titled ‘DAX: Data-Driven Audience Experiences in Esports’, was presented by Athanasios Vasileios Kokkinakis (Univ. of York). He gave a fascinating insight into how companion screen applications might allow audiences to consume interesting data-driven insights during and around the broadcasts of Esports. It was great to see this wort of work since I have some history of working on companion screen applications with sports being one of the genres that could benefit from multi-device applications. The paper won the best paper award! Yvette Wohn (New Jersey Institute of Technology) presented a paper, titled ‘Audience Management practices of Live Streamers on Twitch’, in which she interviewed Twitch streamers to understand how streamers discover audience composition and use appropriate mechanisms to interact with them. The last paper of the conference was presented by Marian – ‘Authoring Interactive Fictional Stories in Object-Based Media (OBM)’. The paper referred to quite a few BBC R&D OBM projects. Again, it was quite lovely to see some reaffirmation of ideas with similar thought processes flowing through the screen.
Memories of the last paper session at IMX 2020 – 1.
Memories of the last paper session at IMX 2020 – 2.
Memories of the last paper session at IMX 2020 – 3.
My last question of the conference.
At 6 PM (BST), I had the honour of chairing the closing keynote by Nonny. Nonny had a lot of unique immersive journalism pieces to show us! She also gave us a live demo of her XR creation, remixing and sharing platform – REACH.love. She imported a virtual character inspired by the Futurama animated character – Bender. Incidentally, my very first virtual character was also created in Bender’s image. I had to remove the antenna off his head because Anthony Steed, who was my project lead at the time, wasn’t as appreciative of my character design – tragic times.
Nonny de la Peña’s closing keynote at IMX 2020 – 1.
Nonny de la Peña’s closing keynote at IMX 2020 – 2.
Nonny de la Peña’s closing keynote at IMX 2020 – 3.
Nonny de la Peña’s closing keynote at IMX 2020 – 4.
Alas, we had come near the end of the conference which meant it was time for Mario to give a summary of numbers to indicate how many attendees participated in IMX 2020 – spoiler: it was the highest attendance yet. He also handed out various awards. It turns out that our co-authored paper on ‘Conceptualising Augmented Reality Television for the Living Room’ got an honourable mention! More importantly, I was awarded the best social media reporter which is of course why you are reading this report! I guess this is an encouragement to keep on tweeting about IMX!
IMX 2020 numbers.
The organising committee who worked hard to virtualise the conference at such short notice.
Extra kudos – every conference should give extra kudos!
Awards collected at IMX 2020 – 1!
Awards collected at IMX 2020 – 2!
Frank Bentley (Verizon Media, IMX Steering Committee president) gave a short presentation in which he acknowledged that it was June the 19th – Juneteenth (Freedom Day) in the US. He gave a couple of poignant suggestions on how we might consider marking the day. He also talked about the rebranding exercise that resulted in the conference going from TVX to IMX.
Presentation from Frank Bentley (IMX Steering Committee President) – Juneteeth!
IMX rebrand and call for IMX 2022 bids!
Frank also announced that we are looking for host bids for IMX 2022! As VP of Conferences, I would be very excited to hear from you! Please do email me if you are looking for information about hosting an IMX conference in 2022 or beyond. You can also drop me a tweet @What2DoNext!
He then handed over the floor to Yvette and me to announce the proposed venue of IMX 2021 – New York! A few of the organising committee positions are still up for grabs. Do consider joining our exciting and diverse organising committee if you feel like you could contribute to making IMX 2021 a success! In the meantime, I managed to persuade my lovely colleague at BBC R&D (Vicky Barlow) to make a teaser video to introduce IMX 2021.
That brought us to the end of IMX 2020, sadly. The stragglers of the IMX community lingered a little to have a little bit of chat over zoom which was lovely.
Group Snaps at IMX 2020!
After the conference…
You would think that once the conference was over, that was it but no, not so. In years past, all that was left to do was to stalk people you met at the conference on LinkedIn to make sure the ‘virtual business cards’ were saved. Of course, I did a bit of that this year as well. However, this year had been a much more involved experience. I have had a chance to define the role of Diversity chairs with Asreen. I have had the chance to work with Ayman, Julie, Jesús, Liv and Blair to bring demos and posters to Hubs as part of the IMX 2020 virtual experience. It was a blast! You might have thought that I would be taking a rest! You would be wrong!
I am joining forces with Yvette and the rest of a whole new committee to start organising IMX 2021 – New York into a format that continues the success of IMX 2020 and strive to improve on it. Finally, let’s not forget Frank’s reminder that we are looking for colleagues out there (maybe you?) to host IMX 2022 and beyond!
Crowdsourcing is a well-established concept in the scientific community, used for instance by Jeff Howe and Mark Robinson in 2005 to describe how businesses were using the Internet to outsource work to the crowd [2], but can be dated back up to 1849 (weather prediction in the US). Crowdsourcing has enabled a huge number of new engineering rules and commercial applications. To better define crowdsourcing in the context of network measurements, a seminar was held in Würzburg, Germany 25-26 September 2019 on the topic “Crowdsourced Network and QoE Measurements”. It notably showed the need for releasing a white paper, with the goal of providing a scientific discussion of the terms “crowdsourced network measurements” and “crowdsourced QoE measurements”. It describes relevant use cases for such crowdsourced data and its underlying challenges.
The outcome of the seminar is the white paper [1], which is – to our knowledge – the first document covering the topic of crowdsourced network and QoE measurements. This document serves as a basis for differentiation and a consistent view from different perspectives on crowdsourced network measurements, with the goal of providing a commonly accepted definition in the community. The scope is focused on the context of mobile and fixed network operators, but also on measurements of different layers (network, application, user layer). In addition, the white paper shows the value of crowdsourcing for selected use cases, e.g., to improve QoE, or address regulatory issues. Finally, the major challenges and issues for researchers and practitioners are highlighted.
This article now summarizes the current state of the art in crowdsourcing research and lays down the foundation for the definition of crowdsourcing in the context of network and QoE measurements as provided in [1]. One important effort is first to properly define the various elements of crowdsourcing.
1.1 Crowdsourcing
The word crowdsourcing itself is a mix of the crowd and the traditional outsourcing work-commissioning model. Since the publication of [2], the research community has been struggling to find a definition of the term crowdsourcing [3,4,5] that fits the wide variety of its applications and new developments. For example, in ITU-T P.912, crowdsourcing has been defined as:
Crowdsourcing consists of obtaining the needed service by a large group of people, most probably an on-line community.
The above definition has been written with the main purpose of collecting subjective feedback from users. For the purpose of this white paper focused on network measurements, it is required to clarify this definition. In the following, the term crowdsourcing will be defined as follows:
Crowdsourcing is an action by an initiator who outsources tasks to a crowd of participants to achieve a certain goal.
The following terms are further defined to clarify the above definition:
A crowdsourcing action is part of a campaign that includes processes such as campaign design and methodology definition, data capturing and storage, and data analysis.
The initiator of a crowdsourcing action can be a company, an agency (e.g., a regulator), a research institute or an individual.
Crowdsourcingparticipants (also “workers” or “users”) work on the tasks set up by the initiator. They are third parties with respect to the initiator, and they must be human.
The goal of a crowdsourcing action is its main purpose from the initiator’s perspective.
The goals of a crowdsourcing action can be manifold and may include,
for example:
Gathering subjective feedback from users about an application (e.g., ranks expressing the experience of users when using an application)
Leveraging existing capacities (e.g., storage, computing, etc.) offered by companies or individual users to perform some tasks
Leveraging cognitive efforts of humans for problem-solving in a scientific context.
In general, an initiator adopts a
crowdsourcing approach to remedy a lack of resources (e.g., running a
large-scale computation by using the resources of a large number of users to
overcome its own limitations) or to broaden a test basis much further than classical
opinion polls. Crowdsourcing thus covers a wide range of actions with various
degrees of involvement by the participants.
In crowdsourcing, there are various methods of identifying, selecting, receiving, and retributing users contributing to a crowdsourcing initiative and related services. Individuals or organizations obtain goods and/or services in many different ways from a large, relatively open and often rapidly-evolving group of crowdsourcing participants (also called users). The use of goods or information obtained by crowdsourcing to achieve a cumulative result can also depend on the type of task, the collected goods or information and final goal of the crowdsourcing task.
1.2
Roles and Actors
Given the above definitions, the actors involved in a crowdsourcing action are the initiator and the participants. The role of the initiator is to design and initiate the crowdsourcing action, distribute the required resources to the participants (e.g., a piece of software or the task instructions, assign tasks to the participants or start an open call to a larger group), and finally to collect, process and evaluate the results of the crowdsourcing action.
The role of participants depends on their degree of contribution or involvement. In general, their role is described as follows. At least, they offer their resources to the initiator, e.g., time, ideas, or computation resources. In higher levels of contributions, participants might run or perform the tasks assigned by the initiator, and (optionally) report the results to the initiator.
Finally, the relationships between the initiator and the participants are governed by policies specifying the contextual aspects of the crowdsourcing action such as security and confidentiality, and any interest or business aspects specifying how the participants are remunerated, rewarded or incentivized for their participation in the crowdsourcing action.
2 Crowdsourcing in the Context of Network
Measurements
The above model considers crowdsourcing at large. In this section, we
analyse crowdsourcing for network measurements, which creates crowd data. This exemplifies the
broader definitions introduced above, even if the scope is more restricted but
with strong contextual aspects like security and confidentiality rules.
2.1
Definition: Crowdsourced Network Measurements
Crowdsourcing enables a distributed and scalable approach to perform network measurements. It can reach a large number of end-users all over the world. This clearly surpasses the traditional measurement campaigns launched by network operators or regulatory agencies able to reach only a limited sample of users. Primarily, crowd data may be used for the purpose of evaluating QoS, that is, network performance measurements. Crowdsourcing may however also be relevant for evaluating QoE, as it may involve asking users for their experience – depending on the type of campaign.
With regard to the previous section and the special aspects of network measurements, crowdsourced network measurements/crowd data are defined as follows, based on the previous, general definition of crowdsourcing introduced above:
Crowdsourced network measurements are actions by an initiator who outsources tasks to a crowd of participants to achieve the goal of gathering network measurement-related data.
Crowd data is the data that is generated in the context of crowdsourced network measurement actions.
The format of the crowd data is specified by the initiator and depends
on the type of crowdsourcing action. For instance, crowd data can be the
results of large scale computation experiments, analytics, measurement data,
etc. In addition, the semantic interpretation of crowd data is under the
responsibility of the initiator. The participants cannot interpret the crowd
data, which must be thoroughly processed by the initiator to reach the
objective of the crowdsourcing action.
We consider in this paper the contribution of human participants only. Distributed measurement actions solely made by robots, IoT devices or automated probes are excluded. Additionally, we require that participants consent to contribute to the crowdsourcing action. This consent might, however, vary from actively fulfilling dedicated task instructions provided by the initiator to merely accepting terms of services that include the option of analysing usage artefacts generated while interacting with a service.
It follows that in the present document, it is assumed that
measurements via crowdsourcing (namely, crowd data) are performed by human
participants aware of the fact that they are participating in a crowdsourcing
campaign. Once clearly stated, more details need to be provided about the
slightly adapted roles of the actors and their relationships in a crowdsourcing
initiative in the context of network measurements.
2.2
Active and Passive Measurements
For a better classification of crowdsourced network measurements, it is
important to differentiate between active
and passive measurements. Similar to
the current working definition within the ITU-T Study Group 12 work item
“E.CrowdESFB” (Crowdsourcing Approach for
the assessment of end-to-end QoS in Fixed Broadband and Mobile Networks),
the following definitions are made:
Active measurements create
artificial traffic to generate crowd data.
Passive
measurements do not create artificial traffic, but measure crowd
data that is generated by the participant.
For example, a typical case of an active measurement is a
speed test that generates artificial traffic against a test server in order to
estimate bandwidth or QoS. A passive measurement instead may be realized by
fetching cellular information from a mobile device, which has been collected
without additional data generation.
2.3
Roles of the Actors
Participants have to commit to participation in the crowdsourcing measurements. The level of contribution can vary depending on the corresponding effort or level of engagement. The simplest action is to subscribe to or install a specific application, which collects data through measurements as part of its functioning – often in the background and not as part of the core functionality provided to the user. A more complex task-driven engagement requires a more important cognitive effort, such as providing subjective feedback on the performance or quality of certain Internet services. Hence, one must differentiate between participant-initiated measurements and automated measurements:
Participant-initiated measurements require
the participant to initiate the measurement. The measurement data are typically
provided to the participant.
Automated
measurements can be performed without the need for the participant
to initiate them. They are typically performed in the background.
A participant can thus be a user or a worker. The distinction depends on the main focus of the person doing the contribution and his/her engagement:
A
crowdsourcing user is providing
crowd data as the side effect of another activity, in the context of passive,
automated measurements.
A crowdsourcing
worker is providing crowd data as a consequence of his/her engagement when
performing specific tasks, in the context of active, participant-initiated
measurements.
The term “users” should, therefore, be used when the crowdsourced activity is not the main focus of engagement, but comes as a side effect of another activity – for example, when using a web browsing application which collects measurements in the background, which is a passive, automated measurement.
“Workers” are involved when the crowdsourced activity is the main driver of engagement, for example, when the worker is paid to perform specific tasks and is performing an active, participant-initiated measurement. Note that in some cases, workers can also be incentivized to provide passive measurement data (e.g. with applications collecting data in the background if not actively used).
In general,
workers are paid on the basis of clear guidelines for their specific
crowdsourcing activity, whereas users provide their contribution on the basis
of a more ambiguous, indirect engagement, such as via the utilization of a
particular service provided by the beneficiary of the crowdsourcing results, or
a third-party crowd provider. Regardless of the participants’ level of
engagement, the data resulting from the crowdsourcing measurement action is
reported back to the initiator.
The initiator of the crowdsourcing measurement action often has to design a crowdsourcing measurement campaign, recruit the participants (selectively or openly), provide them with the necessary means (e.g. infrastructure and/or software) to run their action, provide the required (backend) infrastructure and software tools to the participants to run the action, collect, process and analyse the information, and possibly publish the results.
2.4 Dimensions of Crowdsourced Network
Measurements
In light of the previous section, there are multiple dimensions to
consider for crowdsourcing in the context of network measurements. A
preliminary list of dimensions includes:
Level of
subjectivity (subjective vs. objective measurements) in the crowd data
Level of
engagement of the participant (participant-initiated or background) or their
cognitive effort, and awareness (consciousness) of the measurement level of
traffic generation (active vs. passive)
Type and
level of incentives (attractiveness/appeal, paid or unpaid)
Besides these key dimensions, there are other features which are relevant in characterizing a crowdsourced network measurement activity. These include scale, cost, and value; the type of data collected; the goal or the intention, i.e. the intention of the user (based on incentives) versus the intention of the crowdsourcing initiator of the resulting output.
Figure 1: Dimensions for network measurements crowdsourcing definition, and relevant characterization features (examples with two types of measurement actions)
In Figure 1, we have illustrated some dimensions of network measurements based on crowdsourcing. Only the subjectivity, engagement and incentives dimension are displayed, on an arbitrary scale. The objective of this figure is to show that an initiator has a wide range of combinations for crowdsourcing action. The success of a measurement action with regard to an objective (number of participants, relevance of the results, etc.) is multifactorial. As an example, action 1 may indicate QoE measurements from a limited number of participants and action 2 visualizes the dimensions for network measurements by involving a large number of participants.
3
Summary
The attendees of the Würzburg seminar on “Crowdsourced Network and QoE Measurements” have produced a white paper, which defines terms in the context of crowdsourcing for network and QoE measurements, lists of relevant use cases from the perspective of different stakeholders, and discusses the challenges associated with designing crowdsourcing campaigns, analyzing, and interpreting the data. The goal of the white paper is to provide definitions to be commonly accepted by the community and to summarize the most important use-cases and challenges from industrial and academic perspectives.
“What does history mean to computer scientists?” – that was the first question that popped up in my mind when I was to attend the ACM Heritage Workshop at Minneapolis few months back. And needless to say, the follow up question was “what does history mean for a multimedia systems researcher?” As a young graduate student, I had the joy of my life when my first research paper on multimedia authoring (a hot topic those days) was accepted for presentation in the first ACM Multimedia in 1993, and that conference was held along side SIGGRAPH. Thinking about that, it gives multimedia systems researchers about 25 to 30 years of history. But what a flow of topics this area has seen: from authoring to streaming to content-based retrieval to social media and human-centered multimedia, the research area has been hot as ever. So, is it the history of research topics or the researchers or both? Then, how about the venues hosting these conferences, the networking events, or the grueling TPC meetings that prepped the conference actions?
Figure 1. Picture from the venue
With only questions and no clear answers, I decided to attend the workshop with an open mind. Most SIGs (Special Interest Groups) in ACM had representation at this workshop. The workshop itself was organized by the ACM History Committee. I understood this committee, apart from the workshop, organizes several efforts to track, record, and preserve computing efforts across disciplines. This includes identifying distinguished persons (who are retired but made significant contributions to computing), coming up with a customized questionnaire for the persons, training the interviewer, recording the conversations, curating them, archiving, and providing them for public consumption. Efforts at most SIGs were mostly based on the website. They were talking about how they try to preserve conference materials such as paper proceedings (when only paper proceedings were published), meeting notes, pictures, and videos. For instance, some SIGs were talking about how they tracked and preserved ACM’s approval letter for the SIG!
It was very interesting – and touching – to see some attendees (senior Professors) coming to the workshop with boxes of materials – papers, reports, books, etc. They were either downsizing their offices or clearing out, and did not feel like throwing the material in recycling bins! These materials were given to ACM and Babbage Institute (at University of Minnesota, Minneapolis) for possible curation and storage.
Figure 2. Galleries with collected material
ACM History committee members talked about how they can fund (at a small
level) projects that target specific activities for preserving and archiving
computing events and materials. ACM History Committee agreed that ACM
should take more responsibility in providing technical support to web hosting –
obviously, not sure whether anything tangible would result.
Over the two days at the workshop, I was getting answers to my questions: History can mean pictures and videos taken at earlier MM conferences, TPC meetings, SIGMM sponsored events and retreats. Perhaps, the earlier paper proceedings that have some additional information than what is found in the corresponding ACM Digital Library version. Interviews with different research leaders that built and promoted SIGMM.
It was clear that history meant different things to different SIGs, and
as SIGMM community, we would have to arrive at our own
interpretation, collect and preserve that. And that made me understand the most
obvious and perhaps, the most important thing: today’s events become tomorrow’s
history! No brainer, right? Preserving today’s SIGMM events will give
us a richer, colorful, and more complete SIGMM history for the future
generations!
The annual ACM Multimedia Conference was held in Nice, France during October 21st to 25th, 2019. Being the 27th of its series, it attracted approximately 800 participants from all over the World. Among them were the student volunteers who supported the smooth organization of the Conference. In this article, I would like to introduce the reports and comments provided by each of them.
Figure. Student volunteers at ACM Multimedia 2019
Reports from student volunteers
Hui Chen (Tsinghua University, China)
It was such an honor for me to be granted for the student travel funding. During my stay in Nice, as a Ph.D. researcher, I read a lot of nice academical works which inspired me a lot. And I had wonderful conversations with authors from all over the world. Meanwhile, as a session volunteer, I was glad to help speakers and the audience during sessions. Their nice works and warm smiles impressed me a lot. What I most valued about is the friendship with other volunteers. We often discussed the attractive places and the delicious food in Nice, and cared for each other along the journey. I am deeply thankful for this wonderful experience in Nice. Some advice: (1) I think the beret was not necessary for the volunteers. Majority of us seemed to dislike it, because I did not see many volunteers wearing them. (2) Notifications about the room changing for sessions should be made clear early. (3) The manner of being punctual can be emphasized in the ice-break meeting. (4) Reminding of volunteered sessions could be shown in the Whova app.
Shizhe Chen (Renmin University of China, China)
It was a great pleasure to attend the ACM Multimedia this year. I have attended MM twice and the organizations are getting better and better. One big change was the deployment of the Whova APP, which really improved our experience at MM. On the one hand, it made connections among different attendants and organizations more convenient and efficient. On the other hand, it was nice to share photos in the APP about the conference. The volunteers are very devoted to serve the conference and uploaded many good pictures. The conference banquet at Nice also improved a lot. I really enjoyed local foods and magic shows. Even though there were so many people at that night, the organization was very ordered and made everyone satisfied. I also liked some multimedia modern art pieces exhibited at the conference which were wonderful. The conference session I enjoyed most was the Multimedia Grand Challenge, which provided a great opportunity for us academics to get involved in real-life problems in industries. It would have been better if there were more opportunities off-line to communicate with industry people in the conference. In summary, thanks for all the efforts the organizers have put on the conference. I am also proud to be able to contribute a little as a volunteer this time.
Yang Chen (University of Science and Technology of China, China)
This was my first time attending an international conference and needed to be a session volunteer during the conference. It was also my first time abroad. So I felt a litter nervous before going abroad for the conference. Fortunately, everything went smoothly in the end. The MM conference has been held for many years, so the experience of organizing the conference is rich, and the scale is also large. The MM conference provided a lot of convenience for the participants. All conference schedules can be found at the venue, so attendees can easily find the sessions that they needed to participate or were interested in. In addition, this year, the MM conference had many local characteristics of Nice, France. All attendees were given the famous local soap of Nice. The French food provided at the venue was also very delicious. All in all, it was a very impressive MM conference experience.
Amanda Duarte (Universitat Politècnica de Catalunya, Spain)
ACM Multimedia 2019 for me was a different and great experience. This was the first time that I attended this conference and it was very different of what I am used to find in a big conference. For the past four years I have been going to conferences more focused on Computer Vision and Machine Learning which nowadays have a large number of attendees, accepted papers, parallel sessions, and all the stress of being in a large venue and need to find the sessions that interest you across large rooms full of people.
ACM Multimedia on the other way around was held in a smaller venue with less attendees but yet with a very large amount of high quality researchers. Thus, I had the chance of talking more to great researchers in the areas that I have interest and also were interested in my work. In addition to my great experience during the conference in general, I had a great experience participating in the Doctoral Symposium during the conference. This event gave me the opportunity to present my work to great researchers that work on topics related to my doctoral thesis and were able of giving me great feedback and suggestions on how to improve my research.
Gelli Francesco (National University of Singapore, Singapore)
Although I am still a student, this edition of ACM Multimedia has been my third. Similar to the previous times, I met with the now more familiar community and allocated my time between attending sessions, walking around the posters, and rehearsing my presentation. My observation is that this year, there has been a major focus on applications rather than on the technical aspects. For example, the Best Paper session included works on zooming audio together with video, multi-modal dialogue system and privacy. The Brave New Ideas session, in which I presented, saw some more unusual and daring applications, such as the automatic creation of a sequence of images to match a short story. I had a great time presenting my paper on ranking images by subjective attributes, as I did my best to engage the audience with multiple questions. I learned from the senior organizers that their goal is to push the Multimedia community on applications such as Wellness and Human-Machine interaction, which naturally involves multimedia data. It was also inspiring to see so many engaged volunteers all dressed in blue running around with that very traditional beret. Definitely looking forward to attend the next edition.
Trung-Hiếu Hoàng (University of Science, Vietnam National University Ho Chi Minh City, Vietnam)
I am excited to share my experience in ACMMM 2019, as a person who received the student travel grant. Living in Vietnam, I cannot believe that I had such a great opportunity to travel thousands of kilometers and attend one of the top conferences in the world. On the first day, I met a lot of friends who received the same travel grant like me. We hung out together sharing different stories and experiences, all of us were enthusiastic and couldn’t wait to become a part of the volunteer team and contribute to the success of this year’s conference. During the last two years, I have had a strong interest in medical image processing. In detail, my research focuses on abnormality detection in the endoscopic image. Attending ACMMM 2019 gave me a wonderful chance to present my work, and discuss with experts in this field. I enjoyed the Healthcare Multimedia workshop, where I met the organizers of the BioMedia Grand Challenge track. I loved talking with them and discussing the future and their interests. In conclusion, I am so glad that the student grant brought me to Europe for the first time, opened up my mind and showed me wonderful things that I had never seen before.
I attended the ACM Multimedia 2019 in Nice, France, and listened to new AI approaches by experts and scholars from various countries. In this conference, I got the chance to learn about the latest studies’ results from world-renowned universities and research institutions, and learn about the latest developments in the industry. These most advanced tools broadened my view and realized the disabilities that can be improved in our future research. Furthermore, I appreciated serving as a volunteer at the conference. This forced me to interact with people and have made many good friends from all over the world. Everything is really well to attend MM’19, but a fly in the ointment is that the attendance of the last two days was pretty low. With some special benefits for people to stay, there could be more academic exchanges at the conference.
Michael Kerr (RMIT University, Australia)
I came to the conference this year hoping to learn about some very specific research that was being presented in my own field of employment of video surveillance. My expectations around these presentations was well met, but additionally I also took away new insights into other areas that were previously not of great interest to me, mainly as I had not explored their application to my own field.
I particularly enjoyed the Tutorials on Multimedia Forensics and was interested to see the work done in areas that had been developed in recent years. I was very engaged by the application of CNN to solve forensic challenges and quickly found that the application of these systems was a major theme in the entire conference. So, whilst I enjoyed many of the practical applications such as the Tutorials, the System Demonstrations, and the Open Source Software Competition, I also learnt a great deal about the growth of CNN technologies within the multimedia discipline as a whole. This has had a positive effect by helping to develop my own research plans and in particular enabling the identification of new applications that may be of interest to those working in multimedia as well as my specific field of interest.
Saurabh Kumar (Indian Institute of Technology Bombay, India)
I had an enjoyable experience at ACM Multimedia and learned a lot as this was my first big international conference. The papers were from diverse applications, and it was great talking to the speakers after the talks and at the posters. This allowed me to meet many amazing people from various backgrounds and talk about the exciting research they are doing. It was easy to approach anyone at the conference for casual or technical discussions. These days conferences are recorded with recording and proceedings are put up online, but that is just the tip of the iceberg. Attending a conference is a much broader experience, and I got an opportunity to experience this thanks to this travel grant. I made friends from many countries, thanks to the friendly atmosphere, and learned how my research fits in. I would like to highlight that being a volunteer was the primary reason all of this was possible. As a volunteer, it was so much easier to talk to people, and it was great helping them around. I would love to come and help out again anytime. The conference was just perfect, and I will remember my experience as a volunteer, which made it way more fun and especially the people I interacted with. I am certainly submitting to the next MM and coming back again with more exciting research and to meet this fantastic community. Also, visiting Nice was a delight, and it is a magnificent city, and the food was delicious.
Yadan Luo (University of Queensland, Australia)
It has been a great experience attending ACM Multimedia 2019 in Nice this October, where I met many brilliant people working in the same field. The Invited Talks offered impressive ideas, inspiring visions of the future and excellent coverage of many areas, like preserving audiovisual archives and data protection law. The most impressive part of the conference was the Art Exhibition, which showed a great power of installation art and interactive multimedia. Moreover, this great meeting brought me a lot of precious opportunities of meeting other researchers working in other subfields like video streaming, domain adaptation, and image generation. All chatting with them helped me quickly pick up plenty of new knowledge and opened a door to other research directions. In conclusion, I would like to sincerely express my thanks to people who have prepared the conference, in which I have benefited a lot from this fantastic event.
Kwanyong Park (Korea Advanced Institute of Science and Technology, Korea)
ACM Multimedia 2019 was especially special to me in terms of my improvement. Honestly speaking, my paper, presented in ACM Multimedia 2019, is my first international research accomplishment. So I really lacked experiences and skills about presenting my work and communicating with other researchers. But after ACM Multimedia 2019, I have confidence that at least I can do better and better. Combination of Oral and Poster sessions was really impressive and effective to obtain a lot of information in a short time. Every paper had at least 2 minutes oral presentation, and I could catch the core concept. Based on that, I easily decided whether the paper is closely related to my interest or not. I agree that this kind of configuration is a really efficient way. Through the conference, I saw which topics the students, who have mostly academic perspective, are focusing on. Although it is a great stimulus to me, I think practical perspective from various companies is also important to broaden the horizon. However, research from companies was relatively hard to find in ACM Multimedia 2019. I think that having some interactive booths from companies would be helpful.
K. R. Prajawal (International Institute of Information Technology, India)
ACM Multimedia was not only my first top-tier conference, but my first conference as well. I was pleased to see a lot of interesting and impactful papers from people from various backgrounds and universities. I particularly liked the conference venue as well, as it was spacious and comfortable to encourage a healthy discussion. I personally feel the food and meals could have been better curated. For example, I’m a vegetarian. I understand I have few items to eat, but the vegetarian items were not clearly labeled. This can be rectified in the future editions of the conference. I also believe that most of the presentation rooms were well prepared and organized for the presentation. During my oral presentation, however, I had an issue in playing a demo video. This issue had occurred because the conference organizers were not fully prepared to play a video during the presentation. That is rather odd, I felt, given this is a top-tier multimedia conference, which means it will have lots of audio and visual content. But, other than that, I had a very pleasant and fruitful time at the conference. I was able to connect and socialize with eminent researchers at ACM Multimedia and I hope to attend the next edition as well.
Estêvão Bissoli Saleme (Federal University of Espírito Santo, Brazil)
ACM Multimedia 2019 in Nice was such a unique experience. I volunteered for six sessions and attended a couple more, including the Best Paper session which I particularly liked the most. Not only because it brought original ideas, but also because I had the opportunity to witness an innovative presentation of the paper “Multimodal Dialog System: Generating Responses via Adaptive Decoders,” in which the speakers kept a dialog between them to give their talk. Besides that, I enjoyed the poster presentation hall, which we could mingle with other participants, get to know other people’s work better, and interact with them. One presentation that impressed me was entitled “Editing Text in the Wild.” In this work, the researchers proposed a method to replace any text in a picture keeping the background intact. The outcome looked like a real figure. Just impressive! Technically, I was more interested in Quality of Experience and Interaction, but I thought the subject of the papers in this session was spread out, which hindered the interaction with other presenters. It lacked a bit of work related to QoE itself. Finally, another aspect that deserves praise was the organization. Whova helped hugely, and we could post photos and interact with other people there. Moreover, Martha, Laurent, and Benoit were omnipresent and tireless. They were just on fire and worked very well to deliver such a great conference!
David Semedo (Universidade NOVA de Lisboa, Portugal)
My experience at ACM MM 2019 was very positive. I presented two full papers: one as a full oral and one as a short presentation. As such, the whole event was quite intense for me but also very personally enriching. I could do a lot of networking, with both students and senior researchers (the ConfLab contributed in this regard). As I am in my last Ph.D. year, I could talk with several researchers, from which I got valuable advices on how to take the next steps towards pursuing a career in research. At the poster sessions, I had the opportunity to discuss in detail my work with several people, from which I received constructive feedback. While I liked the fact that posters stayed posted during the whole conference, some were hard to find or were a bit hidden (e.g. the ones facing the wall). The conference program covered a wide range of topics on Multimedia. This allowed me to understand which techniques are being used on different tasks, and identify common technical aspects across these different tasks. It not only helped me in being updated, in terms of state-of-the-art approaches, but also in defining potential future research directions.
Junbo Wang (Institute of Automation, Chinese Academy of Sciences, China)
From 21-25 October 2019, I attended the ACM Multimedia 2019 Conference in Nice, France. This conference is a premier international conference in the area of multimedia within the field of computer science and I am very proud of attending this professional conference thanks to the ACM student travel grant. In this conference, I met many famous researchers in the area of multimedia, such as Tao Mei, Tat-Seng Chua, and Changsheng Xu. During the Poster or Oral sessions, I discussed many academic problems with these researchers, which really gave me new vision and insight. In addition to many academic talks, I also enjoyed a lot of French food, such as Macaroon and Foie Gras. As a session volunteer, I was also very happy to help the attendees in some session talks. The interesting and professional talks inspired me and guided my interest to many different research areas. Moreover, the conference was held at the NICE ACROPOLIS Convention Center in Nice, which is a beautiful and peaceful city. The fresh air and pleasant sea breeze gave us a good mood every day and made us have an unforgettable experience in this city. Overall, I think this conference was very successful to reach its fundamental objective: free communication. However, I also found that the sponsors this year was far less than that for last year, which can be expected to be better in the next year.
Xin Wang (Donghua University, China)
In my experience, I think MM’19 was very impressive and easy to follow. The arrangement of the conference was very reasonable especially the Whova APP helped me a lot whenever I wanted to figure on what is going on during the conference. Except one thing that I found in the first two days, there were still some workshops that had different room numbers between the session volunteer schedule (a Google sheet). That made me confused for a while, but luckily Martha told us use the APP as the standard. I really loved the Demo session and I think there must be people who had the same feeling like me. I met and talked with many researchers from all of the world, such as NUS, DCU, Nagoya University, Shandong University, National Chiao Tung University, etc. I still keep contact with some of them and exchange our research ideas. Besides, the weather in Nice was very comfortable. The food during the conference was rich and delicious. All of these reasons make me look forward to the next year’s MM conference.
Yitian Yuan (Tsinghua University, China)
It was very enjoyable to attend the ACM MM 2019 conference. As a volunteer, I could meet peers from other countries and schools and communicate with them, which is of great benefit to my scientific research knowledge. I think the agenda of this ACM MM conference was compact and reasonably arranged, but there are still the following problems that I think need to be improved: (1) The entrance of the main conference hall was dimly lit and the signs were not obvious, so volunteers needed to guide, otherwise it was difficult for participants to find the place. (2) I wish the stage at the Banquet had a bigger screen, so that everyone can see the name of the winners and the prize information. Finally, I wish the ACM MM better and better and more international influence.
Zhengyu Zhao (Radboud University, The Netherlands)
This was my second time to attend ACM Multimedia, after the first time in Korea in 2018. Overall, I felt the conference this year was a very successful edition, reflected by the perfect location, delicious food, well-designed program and especially the efforts from the volunteers. But still, I have some suggestions for further improvement. Specifically, from the experience of the poster presentation of my reproducibility paper, I realized that most people actually know nothing about this new reproducibility track. This made most of my time spent on explaining the general background of the track and so less time for my own research. I was happy to explain and get more people involved in this track but it would be better if the organization team could give more exposure of this track beforehand. From this experience serving as one of the poster session chairs, I figured out that many people do not use the official communication APP Whova, so the instructions and important announcements could not reach all the participants timely. In my opinion, more offline solutions (e.g., a big screen on the spot) would help.
Summary
In general, the student volunteers seemed to have enjoyed the event to the full extent, but some of them have proposed constructive suggestions that organizers and participants to future versions of the conference could take in account to provide better experiences!
All in all, I think we can see from the submitted reports that providing the chance to experience top-level research and to mix with all-range of researchers at a top-level Conference to young researchers who may one day become leaders in our community, would surely benefit us in the future.
The QoMEX 2019 was held from 5 to 7 June 2019 in Berlin, with Sebastian Möller (TU Berlin and DFKI) and Sebastian Egger-Lampl (AIT Vienna) as general chairs. The annual conference celebrated its 10th birthday in Berlin since the first edition in 2009 in San Diego. The latter focused on classic multimedia voice, video and video services. Among the fundamental questions back then were how to measure and how to quantify quality from the user’s point of view in order to improve such services? Answers to these questions were also presented and discussed at QoMEX 2019, where technical developments and innovations in terms of video and voice quality were considered. The scope has however broadened significantly over the last decade: interactive applications, games and immersive technologies, which require new methods for the subjective assessment of perceived quality of service and QoE, were addressed. With a focus on 5G and its implications for QoE, the influence of communication networks and network conditions for the transmission of data and the provisioning of services were also examined. In this sense, QoMEX 2019 looked at both classic multimedia applications such as voice, audio and video as well as interactive and immersive services: gaming QoE, virtual realities such as VR exergames, and augmented realities such as smart shopping, 360° video, Point Clouds, Web QoE, text QoE, perception of medical ultrasound videos for radiologists, QoE of visually impaired users with appropriately adapted videos, QoE in smart home environments, etc.
In addition to this application-oriented perspective, methodological approaches and fundamental models of QoE were also discussed during QoMEX 2019. While suitable methods for carrying out user studies and assessing quality remain core topics of QoMEX, advanced statistical methods and machine learning (ML) techniques emerged as another focus topic at this year’s QoMEX. The applicability, performance and accuracy of e.g. neural networks or deep learning approaches have been studied for a wide variety of QoE models and in several domains: video quality in games, content of image quality and compression methods, quality metrics for high-dynamic-range (HDR) images, instantaneous QoE for adaptive video streaming over the Internet and in wireless networks, speech quality metrics, and ML-based voice quality improvement. Research questions addressed at QoMEX 2019 include the impact of crowdsourcing study design on the outcomes, or the reliability of crowdsourcing, for example, in assessing voice quality. In addition to such data-driven approaches, fundamental theoretical work on QoE and its quantification in systems as well as fundamental relationships and model approaches were presented.
The TPC Chairs were Lynne Baillie (HWU Edinburgh), Tobias Hoßfeld (Univ. Würzburg), Katrien De Moor (NTNU Trondheim), Raimund Schatz (AIT Vienna). In total, the program included 11 sessions on the above topics. From those 11 sessions, 6 sessions on dedicated topics were organized by various Special Session organizers in an open call. A total of 82 full paper contributions were submitted, out of which 35 contributions were accepted (acceptance rate: 43%). Out of the 77 short papers submitted, 33 were accepted and presented in two dedicated poster sessions. The QoMEX 2019 Best Paper Award went to Dominik Keller, Tamara Seybold, Janto Skowronek and Alexander Raake for “Assessing Texture Dimensions and Video Quality in Motion Pictures using Sensory Evaluation Techniques”. The Best Student Paper Award went to Alexandre De Masi and Katarzyna Wac for “Predicting Quality of Experience of Popular Mobile Applications in a Living Lab Study”.
The keynote speakers addressed several timely topics. Irina Cotanis gave an inspiring talk on QoE in 5G. She addressed both the emerging challenges and services in 5G and the question of how to measure quality and QoE in these networks. Katrien De Moor highlighted the similarities and differences between QoE and User Experience (UX), considering the evolution of the two terms QoE and UX in the past and current status. An integrated view of QoE and UX was discussed and how the two concepts develop in the future. In particular, she posed the question how the two communities could empower each other and what would be needed to bring both communities together in the future. The final day of QoMEX 2019 began with the keynote of artist Martina Menegon, who presented some of her art projects based on VR technology.
Additional activities and events within QoMEX 2019 comprised the following. (1) In the Speed PhD mentoring organized by Sebastian Möller and Saman Zadtootaghaj, the participating doctoral students could apply for a short mentoring session (10 minutes per mentor) with various researchers from industry and academia in order to ask technical or general questions. (2) In a session organized by Sebastian Egger-Lampl, the best works of the last 5 years of the simultaneous TVX Conference and QoMEX were presented to show the similarities and differences between the QoE and the UX communities. This was followed by a panel discussion. (3) There was a 3-minute madness session organized by Raimund Schatz and Tobias Hoßfeld, which featured short presentations of “crazy” new ideas in a stimulating atmosphere. The intention of this second session is to playfully encourage the QoMEX community to generate new unconventional ideas and approaches and to provide a forum for mutual creative inspiration.
The next edition, QoMEX 2020, will be held May 26th to 28th 2020 in Athlone, Ireland. More information: http://qomex2020.ie/
Alia Sheikh (@alteralias) is researching immersive and interactive content. At present she is interested in the narrative language of immersive environments and how stories can best be choreographed within them.
Being part of an international academic research community and actually meeting said international research community are not exactly the same thing it turns out. After attending the 2019 ACM MMSys conference this year, I have decided that leaving the office and actually meeting the people behind the research is very worth doing.
This year I was invited to give an overview presentation at ACM MMSys ’19, which was being hosted at the University of Massachusetts. The MMSys, NOSSDAV and MMVE (International Workshop on Immersive Mixed and Virtual Environment Systems) conferences happen back to back, in a different location each year. I was asked to talk about some of our team’s experiments in immersive storytelling at MMVE. This included our current work on lightfields and my work on directing attention in, and the cinematography of, immersive environments.
To be honest it wasn’t the most convenient time to decide to catch a plane to New York and then a train to Boston for a multi-day conference, but it felt like the right time to take a break from the office and find out what the rest of the community had been working on.
Fig.1: A picturesque scene from the wonderful University of Massachussetts Amherst campus
I arrived at Amherst the day before the conference and (along with another delegate who had taken the same bus) wandered the tranquil university grounds slightly lost before being rescued by the ever calm and cheerful Michael Zink. Michael is the chair of the MMSys organising committee and someone who later spent much of the conference introducing people with shared interests to each other – he appeared to know every delegate by name.
Once installed in my UMass hotel room, I proceeded to spend the evening on my usual pre-conference ritual: entirely rewriting my presentation.
As the timetable would have it, I was going to be the first speaker.
Fig. 2: Attendees at MMSys 2019 taking their seats
Fig. 3: Alia in full flow during our talk on day 1
I don’t actually know why I do this to myself, but there is something about turning up to the event proper that gives you a sense of what will work for that particular audience, and Michael had given me a brilliantly concise snapshot of the type of delegate that MMSys attracts – highly motivated, expert on the nuts and bolts of how to get data to where it needs to be and likely to be interested in a big picture overview of how these systems can be used to create a meaningful human connection.
Using selected examples from our research, I put together a talk on how the experience of stories in high tech immersive environments differs from more traditional formats, but, once the language of immersive cinematography is properly understood, we find that we are able to create new narrative experiences that are both meaningful and emotionally rich.
The next morning I walked into an auditorium full of strangers filing in, gave my talk (I thought it went well?) and then sank happily into a plush red flip-seat chair safe in the knowledge that I was free to enjoy the rest of the event.
The next item was the keynote and easily one of the best talks I have ever experienced at a conference. Presented by Professor Nimesha Ranasinghe it was a masterclass in taking an interesting problem (how do we transmit a full sensory experience over a network?) And presenting it in such a way as to neatly break down and explain the science (we can electrically stimulate the tongue to recreate a taste!) while never losing sight of the inherent joy in working on the kind of science you dream of as a child (therefore electrified cutlery!).
Fig. 4: Professor Nimesha Ranasinghe during his talk on Multisensory experiences
Fig. 5: Multisensory enhanced multimedia – experiences of the future ?
Fig. 6: Networking and some delicious lunch
At lunch I discovered the benefit of having presented my talk early – I made a lot of friends with people who had specific questions about our work, and got a useful heads up on work they were presenting either in the afternoon’s long papers session or the poster session.
We all spent the evening at the welcome reception on the top floor of UMass Hotel, where we ate a huge variety of tiny, delicious cakes and got to know each other better. It was obvious that in some cases, researchers that might collaborate remotely all year, were able to use MMSys as an excellent opportunity to catch up. As a newcomer to this ACM conference however, I have to say that I found it a very welcoming event, and I met a lot of very friendly people many of them working on research that was entirely different to my own, but which seemed to offer an interesting insight or area of overlap.
I wasn’t surprised that I really enjoyed MMVE – virtual environments are very much my topic of interest right now. But I was delighted by how much of MMSys was entirely up my street. ACM MMSys provides a forum for researchers to present and share their latest research findings in multimedia systems, and the conference cuts across all media/data types to showcase the intersections and the interplay of approaches and solutions developed for different domains. This year, the work presented on how to best encode and transport mixed reality content, as well as predict head motion to better encode and deliver the part of a spherical panorama a viewer was likely to be looking at, was particularly interesting to me. I wondered whether comparing the predicted path of user attention to the desired path of user attention, would teach us how to better control a users attention within a panoramic scene, or whether peoples viewing patterns were simply too variable. In the Open Datasets & Software track, I was fascinated by one particular dataset: “ A Dataset of Eye Movements for the Children with Autism Spectrum Disorder”. This was a timely reminder for me that diversity within the audience needed to be catered for when designing multimedia systems, to avoid consigning sections of our audience to a substandard experience.
Of the demos, there were too many interesting ones to list, but I was hugely impressed by the demo for Multi-Sensor Capture and Network Processing for Virtual Reality Conferencing. This used cameras and Kinects to turn me into a point cloud and put a live 3D representation of my own physical body in a virtual space.A brilliantly simple and incredibly effective idea and I found myself sitting next to the people responsible for it at a talk later that day and discussing ways to optimise their data compression.
Despite wearing a headset that allowed me to see the other participants, I was still able to see and therefore use my own hands in the real world – even extending to picking up and using my phone.
Fig. 7: Trying out some cool demos during a bustling demo session
Fig. 8: An example of the social media interaction from my “tweeting”
Amusingly, I found that I was (virtually) sat next to a point-cloud of TNO researcher Omar Niamut which led to my favourite twitter exchange of the whole conference. I knew Omar from online, but we had never actually managed to meet in real life. Still, this was the most life-like digital incarnation yet!
I really should mention the Women’s and Diversity lunch event which (pleasingly) was attended by both men and women and offered some absolutely fascinating insights.
These included: the value of mentors over the course of a successful academic life, how a gender pay-gap is inextricably related to work family policies and steps that have successfully been taken by some countries and organisations to improve work-life balance for all genders.
It was incredibly refreshing to see these topics being discussed both scientifically and openly. The conversations I had with people afterwards as they opened up about their own experiences of work and parenthood, were among the most interesting I have ever had on the topic.
Another nice surprise – MMSys offers childcare grants available for conference attendees who are bringing small children to the conference and require on-site childcare or who incur extra expenses in leaving their children at home. It was very cheering to see that the Inclusion Policy did not stop at simply providing interesting talks, but also translated into specific inclusive action.
Fig. 9: Women’s and Diversity lunch! What a wonderful initiative – well done MMSys and SIGMM
I am delighted that I made the decision to attend MMSys. I had not realised that I was feeling somewhat detached from my peers and the academic research community in general, until I was put in an environment which contained a concentrated amount of interesting research, interesting researchers and an air of collaboration and sheer good will. It is easy to get tunnel vision when you are focused on your own little area of work, but every conversation I had at the conference reminded me that research does not happen in a vacuum.
Fig. 10: A fascinating talk at the Women’s and Diversity lunch – it initiated great post event discussions!
Fig. 11: The food truck experience – one of many wonderful social aspects to MMSys 2019
I could write a thousand more words about every interesting thing I saw or person I met at MMSys, but that would only give you my own specific experience of the conference. (I did live tweet* a lot of the talks and demos just for my own records and that can all be found here: https://twitter.com/Alteralias/status/1148546945859952640?s=20)
Fig. 12: Receiving the SIGMM Social Media Reporter Award for MMSys 2019!
Whether you were someone I was sitting next to at a paper session, a person I spoke to standing next to in line at the food truck (one of the many sociable meal events) or someone who demoed their PhD work to me, thank you so much for sharing this event with me.