Conor Keighrey (@ConorKeighrey) recently completed his PhD in the Athlone Institute of Technology which aimed to capture and understand the quality of experience (QoE) within a novel immersive multimedia speech and language assessment. He is currently interested in exploring the application of immersive multimedia technologies within health, education and training.
With a warm welcome from Istanbul, Ali C. Begen (Ozyegin University and Networked Media, Turkey) opened MMSys 2020 this year. In light of the global pandemic, the conference has taken a new format being delivered online for the first time. This, however, was not the only first for MMSys, Laura Toni (University College London, UK) is introduced as the first-ever female co-chair for the conference. This year, the organising committee presented gender and culturally diverse line-up of researchers from all around the globe. In parallel, two new grand challenges were introduced on the topics of “Improving Open-Source HEVC Encoding” and “Low-latency live streaming” for the first time ever at MMSys.
The conference attracted paper submissions from a range of multimedia topics including but not limited to streaming technologies, networking, machine learning, volumetric media, and fake media detection tools. Core areas were complemented with in-depth keynotes delivered by academic and industry experts.
Examples of such include Ryan Overbeck’s (Google, USA) keynote on “Light Fields – Building the Core Immersive Photo and Video Format for VR and AR” presented on the first day. Light fields provide the opportunity to capture full 6DOF and photo-realism in virtual reality. In his talk, Ryan provided key insight into the camera rigs and results from Google’s recent approach to perfect the capture of virtual representations of real-world spaces.
Later during the conference, Roderick Hodgson from Amber Video presented an interesting keynote on “Preserving Video Truth: an Anti-Deepfakes Narrative”. Roderick delivered a fantastic overview of the emerging area of deep fakes, and the application platforms which are being developed to detect, what will without a doubt be used as highly influential media streams in the future. Discussion closed with Stefano Petrangeli asking how the concept of deep fakes could be applied within the context of AR filters. Although AR is within its infancy from a visual quality perspective, the future may rapidly change how we perceive faces through immersive multimedia experiences utilizing AR filters. The concept is interesting, and it leads to the question of what future challenges will be seen with these emerging technologies.
Although not the main focus of the MMSys conference, the co-located workshops have always stood out for me. I have attended MMSys for the last three years and the warm welcome expressed by all members of the research community has been fantastic. However, the workshops have always shined through as they provide the opportunity to meet those who are working in focused areas of multimedia research. This year’s MMSys was no different as it hosted three workshops:
NOSSDAV – The International workshop on Network and Operating System Support for Digital Audio and Video
MMVE – The International Workshop on Immersive Mixed and Virtual Environment Systems
With a focus on novel immersive media experiences, the MMVE workshop was highly successful with five key presentations exploring the topics of game mechanics, cloud computing, head-mounted display field of view prediction, navigation, and delay. Highlights include the work presented by Na Wang et. Al (George Mason University) which explored field of view prediction within augmented reality experiences on mobile platforms. With the emergence of new and proposed areas of research in augmented reality cloud, field of view predication will alleviate some of the challenges associated with the optimization of network communication for novel immersive multimedia experiences in the future.
Unlike previous years, conference organisers faced the challenge of creating social events which were completely online. A trivia night hosted on Zoom brought over 40 members of the MMSys community together virtually to test their knowledge against a wide array of general knowledge. Utilizing online the platform “Kahoot”, attendees were challenged with a series of 47 questions. With great interaction from the audience, the event provided a great opportunity to socialise in a relaxing manner much like the real world counterpart!
Leader boards towards the end were close, with Wei Tsang Ooi gaining the first place with a last-minute bonus question! Jean Botev and Roderick Hodgson took second and third place respectively. Events like this have always been a highlight of the MMSys community, we hope to see it take place this coming year in person over some quite beers and snacks!
Mea Wang opened the N2Women Meeting on the 10th of June. The event openly discussed core influential topics such as the separation of work and life needs within the research community. With a primary objective of assisting new researchers to maintain a healthy work and life balance. Overall, the event was a success, the topic of work and life balance is important for those at all stages of their research careers. Reflecting on my own personal experiences during my PhD, it can be a struggle to determine when to “clock out” and when to spend a few extra hours engaged with research. Key members of the community shared their own personal experiences, discussing other topics such the importance of mentoring, as academic supervisors can often become a mentor for life. Ozgu Alay discussed the importance of developing connections at research-orientated events. Those new to the community should not be afraid to spark a conversation with experts in the field, often the ideal approach is to take interest in their work and begin discussion from there.
Lastly, Mea Wang mentioned that the initiative had initially acquired funding for the purpose of travel supports and childcare for those attending the conference. Due to the online nature this year, the supports have now been placed aside for next year’s event. Such funding provides a fantastic opportunity to support the cost of attending an international conference and engage with the multimedia community!
Closing the conference, Ali C. Begen opened with the announcement of the awards. The Best Paper Award was presented by Özgü Alay and Christian Timmerer who announced Nan Jiang et al as the winner for their paper on “QuRate: Power-Efficient Mobile Immersive Video Streaming”. The paper is available for download on the ACM Digital Library at the following link. The conference closed with the announcement of key celebrations for next year as the NOSSDAV workshop celebrates it’s 30thanniversary, and the Packet Video workshop celebrates the 25th anniversary!
Overall, the expertise in multimedia shined through in this year’s ACM MMSys, with fantastic keynotes, presentations, and demonstrations from researchers around the globe. Although there are many benefits to attending a virtual conference, after numerous experiences this year I can’t help but feel there is something missing. Over the past 3 years, I’ve attended ACM MMSys in person as a PhD candidate, one of the major benefits of in person events are social encounters. Although this year’s iteration of ACM MMSys did a phenomenal job at the presentation of these events in the new and unexpected virtual format. I believe that it is these social events which shine through as they provide the opportunity to meet, discuss, and develop professional and social links throughout the multimedia research community in a more relaxed setting.
As a result, I look forward to what Özgü Alay, Cheng-Hsin Hsu, and Ali C. Begen have in store for us at ACM Multimedia Systems 2021, located in the beautiful city of Istanbul, Turkey.
I work in the department of Research & Development, based in London, at the BBC. My interests include Interactive and Immersive Media, Interaction Design, Evaluative Methods, Virtual Reality, Augmented Reality, Synchronised Experiences & Connected Homes. In the interest of full disclosure, I serve on the steering board of ACM Interactive Media Experiences (IMX) as Vice President for Conferences. It was an honour to be invited to the organising committee as one of IMX’s first Diversity Co-Chairs and as a Doctoral Consortium Co-Chair. I will also be the General Co-Chair for ACM IMX 2021. I hope you join us at IMX 2021 but if you need convincing, please read on about my experiences with IMX 2020! I am quite active on Twitter (@What2DoNext), so I don’t think it came as a massive surprise to the IMX community that I won the award of the Best Social Media Reporter for ACM IMX 2020. Here are some of the award-winning tweets describing a workshop, a creative challenge, the opening keynote, my co-author presenting our paper (which incidentally won an honourable mention), the closing keynote and announcing the venue for ACM IMX 2021. This report is a summary of my experiences with IMX 2020.
Before the conference
Summary of activities at IMX 2020.
For the first time in the history of IMX, it was going entirely virtual. As if that wasn’t enough, IMX 2020 was the conference that got rebranded. In 2019, it was called TVX – Interactive Experiences for Television and Online Video! However, the steering committee unanimously voted to rename and rebrand it to reflect the fact that the conference had outgrown its original remit. The new name – Interactive Media Experiences (IMX) – was succinct and all-compassing of the conference’s current scope. With the rebrand, came a revival of principles and ethos. For the first time in the history of IMX, the organising committee worked with the steering committee to include Diversity co-chairs.
The tech industry has suffered from a lack of diverse representation, and 2020 was the year, we decided to try to improve the situation in the IMX community. So, in addition to holding the position of the Doctoral Consortium co-chair, a relatively well-defined role, I was invited to be one of two Diversity chairs. The conference was going to take place in Barcelona, Spain – a city I have been lucky to visit multiple times. I love the people, the culture, the food (and wine) and the city, especially in the summer. The organisation was on track when, due to the unprecedented and global pandemic, we called in an emergency meeting to immediately transfer conference activities to various online platforms. Unfortunately, we lost one keynote, a panel, & 3 workshops, but we managed to transfer the rest into a live virtual event over a combination of platforms: Zoom, Mozilla Hubs, Miro, Slack & Sli.do.
The organising committee came together to reach out to the IMX community to ask for their help in converting their paper, poster and demo presentations to a format suitable for a virtual conference. We were quite amazed at how the community came together to make the virtual conference possible. Quite a few of us spent a lot of late nights getting everything ready!
We set about creating an accessible program and proceedings with links to the various online spaces scheduled to host track sessions and links to papers for better access using the SIGCHI progressive web app and the ACM Publishing System. It didn’t hurt that one of our Technical Program chairs, David A. Shamma, is the current SIGCHI VP of Operations. It was also helpful to have access to the ACM’s guide for virtual conferences and the experience gained by folks like Blair McIntyre (general co-chair of IEEE VR 2020 & Professor at Georgia Institute of Technology). We also got lots of support from Liv Erickson (Emerging Tech Product Manager at Mozilla).
About a week before the conference, Mario Montagud (General Co-Chair) sent an email to all registered attendees to inform them about how to join. Honestly, there were moments when I thought it might be touch and go. I had issues with my network, last-minute committee jobs kept popping up, and social distancing was becoming problematic.
During the conference…
Traditionally, IMX brings together international researchers and practitioners from a wide range of disciplines to attend workshops and challenges on the first day followed by two days of keynotes, panels, paper presentations, posters and demos. The activities are interspersed with lunches, networking with colleagues, copious coffee and a social event.
The advantage of a virtual event is that I had no jet lag and I woke up in my bed at home on the day of the conference. However, I had to provide my coffee and lunches in the 2020 instantiation while (very briefly) considering the option of attending an international conference in my pyjamas. The other early difference is that I didn’t get a name badge in a conference branded registration packet, however, due to my committee roles at IMX 2020, the communications team made us zoom background ‘badges’ – which I loved!
Virtual Backgrounds for use in Zoom.
My first day was exciting and diverse! I had a three-hour workshop in the morning (starting 10 AM BST) titled “Toys & the TV: Serious Play” I had organised with my colleagues Suzanne Clark and Barbara Zambrini from BBC R&D, Christoph Ziegler from IRT and Rainer Kirchknopf from ZDF. We had a healthy interest in the workshop and enthusiastic contributions. A few of the attendees contributed idea/position papers while the other attendees were asked to support their favourite amongst the presented ideas. The groups of people were then sent to a breakout group to work on the concept and produce a newspaper-type summary page of an exemplar manifestation of the idea. We all worked over Zoom and a collaborative whiteboard on Miro. It was the virtual version of an interactive “post-it on a wall” type workshop.
Summary of the IMX 2020 workshop on Toys & the TV: House Rules.
Then it was time for lunch and a cup of tea while managing home learning activities for my kids. Usually, I would have been hunting for a quiet place in the conference venue (depending on the time difference) to facetime with my kids. None of that in 2020! I could chat with my fellow organising committee to make sure things were running smoothly and offer aid if needed. Most of the day’s activities were being efficiently coordinated by Mario, based during the conference, at the i2Cat offices in Barcelona.
Around 4 PM (BST), I had a near four-hour creative challenge meet up. However, before that, I dropped into the IMX in Latin America workshop which was organised by colleagues in (you guessed it) Latin America as a way to introduce the work they do to IMX. Things were going well in that workshop, so after a quick hello to the organisers, I rushed over to take part in the creative challenge!
Screenshots from the IMX 2020 Creative Challenge: Andrés starting proceedings off with while demonstrating his best Snap filter.
The virtual background Mar crafted for us.
The largest Zoom meeting I have ever been a part of.
The creative challenge, titled “Snap Creative Challenge: Reimagine the Future of Storytelling with Augmented Reality (AR) ”, was an invited event. It was sponsored by Snap (Andrés Monroy-Hernández) and co-organised by Microsoft Research (Mar González-Franco) and BBC Research & Development (myself). Earlier in the year, over six months, eleven academic teams from eight countries created AR projects to demonstrate their vision of what storytelling would look like in a world where AR is more prevalent. We mentored the teams with the help of Anthony Steed (University College London), Nonny de La Peña (Emblematic Group), Rajan Vaish (Snap), Vanessa Pope (Queen Mary, University of London), and some colleagues who generously donated their time and expertise. We started with a welcome to the event (hosted on Zoom) given by Andrés Monroy-Hernández and then it was straight into presentations of the project. Snap created a summary video of the ideas presented on the day.
IDC Herzliya with a project on Storytelling with AR & IoT devices
UCL with Narrative drive AR companions for kids visiting hospitals
IIIT Delhi with Translating traditional Indian street storytelling to AR
Univ. of Porto with Door Guardians exploring physical doors as triggers for uncovering stories
ENTI-Universitat de Barcelona with the use of shadows as triggers in narrative-based AR & puzzle games
Dalhousie Univ. with a tool for storytellers to turn indoor locations into AR triggers
Virginia Tech with exploring 1st person stories across AR
CMU with converting existing games into immersive AR experiences
Tec de Monterrey with turning sci-fi novels into bite-sized AR games/puzzles to promote reading
ArtCenter with AI-Human partnering to tell AR stories in spatially
UCSB with new design paradigms for creating & sharing AR stories
Each project was distinct, unique and had the potential for so much more development and expansion. The creative challenge was closed by one of the co-founders of Snap (Bobby Murphy). After closing, some teams had office hours where we could go and have an extended chat about the various projects. Everyone was super enthusiastic and keen to share ideas.
It was 8.20 PM, so I had to end the day with my glass of wine with my other half, but I had a brilliant day and couldn’t get over how many interesting people I got to chat to – and it was just the first day of the conference! On the second day of the conference, Christian Timmerer (Alpen-Adria-Universität Klagenfurt & Bitmovin) and I had an hour-long doctoral consortium to host bright and early at 9 AM (BST). Three doctoral students presented a variety of topics. Each student was assigned two mentors who were experts in the field the students were working in. This year, the organising committee were keen to ensure diverse participation through all streams of the conference so, Christian and I kept this in mind in choosing mentors for the doctoral students. We were also able to invite mentors regardless of whether they would travel to a venue or not since everyone was attending online. In a way, it gave us more freedom to be diverse in our choices and thinking. Turns out one hour was whetting the appetite for everyone but the conference had other activities scheduled in the day, so I quite liked having a short break before my next session at noon! Time for another cup of coffee and a piece of chocolate!
Carlos Cortés – Universidad Politécnica de Madrid – talked about his work on “Interaction for Extended Reality environments” (mentored by Daniela Romano – UCL and Teresa Chambel – Univ. of Lisbon)
Wilmer Moina-Rivera – Universitat de València – presented his work on “Video Encoding Cloud System for High Performance Scenarios” (mentored by Lucia D’Acunto – TNO and Ooi Wei Tsang – National University of Singapore)
Simona Manni. – University of York – talked about “Interactive Media and Non-Linear Participatory Narratives of Mental Health” mentored by Bill Gaver – Goldsmiths, University of London and Bill Thompson – BBC R&D
The general chairs (Pablo Cesar – CWI, Mario Montagud & Sergi Fernandez – i2Cat) welcomed everyone to the conference at noon (BST). Pablo gave a summary of the number of participants we had at IMX. This is one of the most unfortunate things in a virtual conference. It’s difficult to get a sense of ‘being together’ with the other attendees at the conference but we got some idea from Pablo. Asreen Rostami (RISE) and I gave a summary of diversity & inclusion activities we put in place through the organisation of the conference to begin the process of improving the representation of under-represented groups within the IMX community. Unfortunately, a lot of the plans were not implemented once IMX 2020 went virtual but some of the guidance to inject diverse thinking into all parts of the conference were still carried out – ensuring that the make-up of the ACs was diverse, encouraging workshop organisers to include a diverse set of participants and use inclusive language, casting a wider net in our search for keynotes and mentors, and selecting a time period to run the conference that was best suited to a majority of our attendees. The Technical Program Co-Chair (Lucia D’Acunto, TNO) gave a summary of how the tracks were populated w.r.t papers. To round off the opening welcome for IMX 2020, Mario gave an overview of communication channels, the tools used and the conference program. The wonderful thing about being in a virtual conference is that you can easily screenshot presentations, so you have a good record of what happened. Under pre-pandemic situations, I would have photographed the slides on a screen on stage from my seat in the auditorium hall. So unfashionable in 2020 – you will agree. Getting a visual reminder of talks is useful if you want to remember key points! It also exceedingly good for illustrations as part of a report you might write about the conference three months later.
Summary of the welcome to IMX 2020 – 1
Summary of the welcome to IMX 2020 – 2
Summary of the welcome to IMX 2020 – 3
Sergi Fernandez introduced the opening keynote: Mel Slater (University of Barcelona) who talked about using Virtual Reality to Change Attitudes and Behaviour. Mel was my doctoral supervisor back in between 2001 and 2006 when I did a PhD at UCL. He was the reason I decided to focus my postgraduate studies to build expressive virtual characters. It was fantastic to “go to a conference with him” again even if he got the seat with the better weather. His opening keynote was engaging, entertaining and gave a lot of food for thought. He also had a new video of his virtual self being a rock star. To this day, I believe this is the main reason he got into VR in the first place! And why ever not?
Some of Mel Slater‘s opening keynote insights at IMX 2020 – 1.
Some of Mel Slater‘s opening keynote insights at IMX 2020 – 2.
Some of Mel Slater‘s opening keynote insights at IMX 2020 – 3.
Immediately after Mels’ talk and Q&A session, it was time to inform attendees about the demos and posters available for viewing as part of the conference. The demos and posters were displayed in a series of Mozilla Hubs rooms (domes) created by Jesús Gutierrez (Universidad Politecnica de Madrid, Demo co-chair) and I, based off some models given to us by Liv (Mozilla). We were able to personalise the virtual spaces and give it a Spanish twist using a couple of panorama images David A. Shamma (FXPAL & Technical Program co-chair for IMX 2020) found on Flickr. Ayman and Julie Williamson (Univ. of Glasgow) also enabled the infrastructure behind the IMX Hub spaces. Jesús and I gave a short ‘how-to’ presentation to let attendees know what to expect in the IMX Hub Spaces. After our presentation, Mario played a video of pitches giving us quick lightning summaries of the demos, work-in-progress poster presentations and doctoral consortium poster displays.
The Poster on Mozilla Hubs in virtual Barcelona for IMX 2020 – 1.
The Poster on Mozilla Hubs in virtual Barcelona for IMX 2020 – 2.
The Demo Domes on Mozilla Hubs in virtual Barcelona for IMX 2020.
I managed to persuade Jesús to take a selfie.
Thirty minutes later, it was time for the first paper session of the day (and the conference)! Ayman chaired the first four papers in the conference in a session titled ‘Augmented TV’. The first paper presented was one I co-authored with Radu-Daniel Vatavu (Univ. Stefan cel Mare of Suceava), Pejman Saeghe (Univ. of Manchester), Teresa Chambel (Univ. of Lisbon), and Marian F Ursu (Univ. of York). The paper (‘Conceptualising Augmented Reality Television for the Living Room’) examined the characteristics of Augmented Reality Television (ARTV) by analysing commonly accepted views on augmented and mixed reality systems, by looking at previous work, by looking at tangential fields (ambient media, interactive TV, 3D TV etc.) and by proposing a conceptual framework for ARTV – the “Augmented Reality Television Continuum”. The presentation is on the ACM SIGCHI’s YouTube channel if you feel like watching Pejman talk about the paper instead of reading it or maybe in addition to reading it!
Ayman and Pejman talking about our paper ‘Conceptualising Augmented Reality Television for the Living Room
I did not present the paper, but I was still relieved that it was done! I have noticed that once a paper I was involved with is done, I tend to have enough headspace to engage and ask questions of other authors. So that’s what I was able to do for the rest of the conference. In that same first paper session, Simon von der Au (IRT) et al. presented ‘The SpaceStation App: Design and Evaluation of an AR Application for Educational Television’ in which they got to work with models and videos of the International Space Station! Now, I love natural history documentaries so when I need to work with content, I don’t think I can go wrong if I choose David Attenborough narrated content – think Blue Planet. However, the ISS is a close second! They also cited two of my co-authored papers – Ziegler et al. 2018 and Saeghe et al. 2019 – which is always lovely to see.
Simon von der Au et al.’s paper on using AR for educational TV – 1.
Simon von der Au et al.’s paper on using AR for educational TV – 2.
Simon von der Au et al.’s paper on using AR for educational TV – 3.
My reaction to Simon von der Au et al.’s paper on using AR for educational TV.
After the first session, we had a 30-minute break before making our way to the Hubs Domes to look at demos and posters. Our outstanding student volunteers were deployed to guide IMX attendees to various domes. It was very satisfying seeing all our Hubs space populated with demos/posters with snippets of conversation flowing past as I passed through the domes to see how folks fared in the space. The whole experience resulted in a lot of selfies and images!
Selfies Galore and a few “candid” shots of others!!!
There were moments of delight throughout the event. I thought I’d rebel against my mom and get pink hair! Pablo got purple hair and IRL he does not have hair that colour (or that uniformly distributed). Ayman and I tried getting some virtual drinks – I got myself a pina colada while Ayman stayed sober. I also visited all the posters and demos which seldom happens when I attend conferences IRL. In Hubs, it was an excellent way to ‘bump into’ folks. I have been in the IMX community for a while, so I was able to recognise many people by reading their floating name labels. Most of their avatars looked nothing like the people I knew! Christian and Omar Niamut (TNO) had more photorealistic avatars but even those were only recognisable if I squinted! I was also very jealous of Omar’s (and Julie’s) virtual hands which they got because they visited the domes using their VR headsets. It was loads of fun seeing how people represented themselves through their virtual clothes, hair and body choice.
All of the demos and posters were well presented but the ‘Watching Together but Apart’ caught my eye because I knew my colleagues Rajiv Ramdhany, Libby Miller, and Kristian Hentschel built ‘BBC Together’ – an experimental BBC R&D prototype to enable people to watch and listen to BBC programmes together while they are physically apart. It was a response to the situation brought to a lot of our doorsteps by the pandemic! It was amazing to see that another research group responded in the same way to build a similar application. It was great fun talking to Jannik Munk Bryld about their project and compare notes.
“Sifter: A Hybrid Workflow for Theme-based Video Curation at Scale” from Univ. of Michigan and Snap Inc.
Once the paper session was over, there was a 45 minutes break to stretch our legs and rest our eyes. Longer in-between session breaks are a necessity in virtual conferences. At 2:30 PM (BST), it was time to listen to two industry talks chaired by Steve Schirra (YouTube) and Mikel Zorrilla (Vicomtech). Mike Darnell (Samsung Electronics America) talked of conclusions he drew from a survey study of hundreds of participants which focused on user behaviour when it came to choosing what to watch on the TV. The main take-home message was that people generally knew in advance exactly what they want to watch on TV.
Industry talk from Samsung – 1.
Industry talk from Samsung – 2.
Industry talk from Samsung – 3.
Industry talk from Samsung – 4.
Natàlia Herèdia (Media UX Design) talked of her pop-up media lab focusing on designing an OTT for a local public channel. She spoke of the process she used and gave a summary of her work on reaching new audiences.
Industry talk from Media UX Design, MediaLab Betevé – 1.
Industry talk from Media UX Design, MediaLab Betevé – 2.
Industry talk from Media UX Design, MediaLab Betevé – 3.
After the industry talk, it was time for a half an hour break. The organising committee and student volunteers went out to the demo domes in Hubs to get a group selfie! We realised that Ayman has serious ambitions when it comes to cinematography. After we got our shots, we attended another paper session chaired by Aisling Kelliher (Virginia Tech) titled ‘Live Production and Audience’. Other people might have mosquitos or mice as a pest problem. In this paper session, I learnt that there are people like Aisling whose pest problems are a little more significant – like bear sized bigger! So many revelations in such a short time!
The first paper of the last session, titled ‘DAX: Data-Driven Audience Experiences in Esports’, was presented by Athanasios Vasileios Kokkinakis (Univ. of York). He gave a fascinating insight into how companion screen applications might allow audiences to consume interesting data-driven insights during and around the broadcasts of Esports. It was great to see this wort of work since I have some history of working on companion screen applications with sports being one of the genres that could benefit from multi-device applications. The paper won the best paper award! Yvette Wohn (New Jersey Institute of Technology) presented a paper, titled ‘Audience Management practices of Live Streamers on Twitch’, in which she interviewed Twitch streamers to understand how streamers discover audience composition and use appropriate mechanisms to interact with them. The last paper of the conference was presented by Marian – ‘Authoring Interactive Fictional Stories in Object-Based Media (OBM)’. The paper referred to quite a few BBC R&D OBM projects. Again, it was quite lovely to see some reaffirmation of ideas with similar thought processes flowing through the screen.
Memories of the last paper session at IMX 2020 – 1.
Memories of the last paper session at IMX 2020 – 2.
Memories of the last paper session at IMX 2020 – 3.
My last question of the conference.
At 6 PM (BST), I had the honour of chairing the closing keynote by Nonny. Nonny had a lot of unique immersive journalism pieces to show us! She also gave us a live demo of her XR creation, remixing and sharing platform – REACH.love. She imported a virtual character inspired by the Futurama animated character – Bender. Incidentally, my very first virtual character was also created in Bender’s image. I had to remove the antenna off his head because Anthony Steed, who was my project lead at the time, wasn’t as appreciative of my character design – tragic times.
Nonny de la Peña’s closing keynote at IMX 2020 – 1.
Nonny de la Peña’s closing keynote at IMX 2020 – 2.
Nonny de la Peña’s closing keynote at IMX 2020 – 3.
Nonny de la Peña’s closing keynote at IMX 2020 – 4.
Alas, we had come near the end of the conference which meant it was time for Mario to give a summary of numbers to indicate how many attendees participated in IMX 2020 – spoiler: it was the highest attendance yet. He also handed out various awards. It turns out that our co-authored paper on ‘Conceptualising Augmented Reality Television for the Living Room’ got an honourable mention! More importantly, I was awarded the best social media reporter which is of course why you are reading this report! I guess this is an encouragement to keep on tweeting about IMX!
IMX 2020 numbers.
The organising committee who worked hard to virtualise the conference at such short notice.
Extra kudos – every conference should give extra kudos!
Awards collected at IMX 2020 – 1!
Awards collected at IMX 2020 – 2!
Frank Bentley (Verizon Media, IMX Steering Committee president) gave a short presentation in which he acknowledged that it was June the 19th – Juneteenth (Freedom Day) in the US. He gave a couple of poignant suggestions on how we might consider marking the day. He also talked about the rebranding exercise that resulted in the conference going from TVX to IMX.
Presentation from Frank Bentley (IMX Steering Committee President) – Juneteeth!
IMX rebrand and call for IMX 2022 bids!
Frank also announced that we are looking for host bids for IMX 2022! As VP of Conferences, I would be very excited to hear from you! Please do email me if you are looking for information about hosting an IMX conference in 2022 or beyond. You can also drop me a tweet @What2DoNext!
He then handed over the floor to Yvette and me to announce the proposed venue of IMX 2021 – New York! A few of the organising committee positions are still up for grabs. Do consider joining our exciting and diverse organising committee if you feel like you could contribute to making IMX 2021 a success! In the meantime, I managed to persuade my lovely colleague at BBC R&D (Vicky Barlow) to make a teaser video to introduce IMX 2021.
That brought us to the end of IMX 2020, sadly. The stragglers of the IMX community lingered a little to have a little bit of chat over zoom which was lovely.
Group Snaps at IMX 2020!
After the conference…
You would think that once the conference was over, that was it but no, not so. In years past, all that was left to do was to stalk people you met at the conference on LinkedIn to make sure the ‘virtual business cards’ were saved. Of course, I did a bit of that this year as well. However, this year had been a much more involved experience. I have had a chance to define the role of Diversity chairs with Asreen. I have had the chance to work with Ayman, Julie, Jesús, Liv and Blair to bring demos and posters to Hubs as part of the IMX 2020 virtual experience. It was a blast! You might have thought that I would be taking a rest! You would be wrong!
I am joining forces with Yvette and the rest of a whole new committee to start organising IMX 2021 – New York into a format that continues the success of IMX 2020 and strive to improve on it. Finally, let’s not forget Frank’s reminder that we are looking for colleagues out there (maybe you?) to host IMX 2022 and beyond!
Welcome to the second column on the ACM SIGMM Records from the Video Quality Experts Group (VQEG). VQEG plays a major role in research and the development of standards on video quality and this column presents examples of recent contributions to International Telecommunication Union (ITU) recommendations, as well as ongoing contributions to recommendations to come in the near future. In addition, the formation of a new group within VQEG addressing Quality Assessment for Health Applications (QAH) has been announced.
VQEG website:www.vqeg.org Authors: Jesús Gutiérrez (jesus.gutierrez@upm.es), Universidad Politécnica de Madrid (Spain) Kjell Brunnström (kjell.brunnstrom@ri.se), RISE (Sweden) Thanks to Lucjan Janowski (AGH University of Science and Technology), Alexander Raake (TU Ilmenau) and Shahid Satti (Opticom) for their help and contributions.
Introduction
VQEG is an international and independent organisation that provides a forum for technical experts in perceptual video quality assessment from industry, academia, and standardization organisations. Although VQEG does not develop or publish standards, several activities (e.g., validation tests, multi-lab test campaigns, objective quality models developments, etc.) carried out by VQEG groups have been instrumental in the development of international recommendations and standards. VQEG contributions have been mainly submitted to relevant ITU Study Groups (e.g., ITU-T SG9, ITU-T SG12, ITU-R WP6C), but also to other standardization bodies, such as MPEG, ITU-R SG6, ATIS, IEEE P.3333 and P.1858, DVB, and ETSI.
In our first column on the ACM SIGMM Records we provided a table summarizing the several VQEG studies that have resulted in ITU Recommendations. In this new column, we describe with more detail the last contributions to recent ITU standards, and we provide an insight on the ongoing contributions that may result in ITU recommendations in the near future.
ITU Recommendations with recent inputs from VQEG
ITU-T Rec. P.1204 standard series
A campaign within the ITU-T Study Group (SG) 12 (Question 14) in collaboration with the VQEG AVHD group resulted in the development of three new video quality model standards for the assessment of sequences of up to UHD/4K resolution. This campaign was carried out during more than two years under the project “AVHD-AS / P.NATS Phase 2”. While “P.NATS Phase 1” (finalized in 2016 and resulting in the standards series ITU-T Rec. P.1203, P.1203.1, P.1203.2 and P.1203.3) addressed the development of improved bitstream-based models for the prediction of the overall quality of long (1-5 minutes) video streaming sessions, the second phase addressed the development of short-term video quality models covering a wider scope with bitstream-based, pixel-based and hybrid models. The P.NATS Phase 2 project was executed as a competition between nine participating institutions in different tracks resulting in the aforementioned three types of video quality models.
For the competition, a total of 26 databases were created, 13 used for training and 13 for validation and selection of the winning models. In order to establish the ground truth, subjective video quality tests were performed on four different display devices (PC-monitors, 55-75” TVs, mobile, and tablet) with at least 24 subjects each and using the 5-point Absolute Category Rating (ACR) scale. In total, about 5000 test sequences with a duration of around 8 seconds were evaluated, containing a variety of resolutions, encoding configurations, bitrates, and framerates using the codecs H.264/AVC, H.265/HEVC and VP9.
More details about the whole workflow and results of the competition can be found in [1]. As a result of this competition, the new standard series ITU-T Rec. P.1204 [2] has been recently published, including a bitstream-based model (ITU-T Rec. P.1204.3 [3]), a pixel-based model (ITU-T Rec. P.1204.4 [4]) and a hybrid model (ITU-T Rec. P.1204.5 [5]).
ITU-T Rec. P.1401
ITU-T Rec. P.1401 [6] is about statistical analysis, evaluation and reporting guidelines of quality measurements and was recently revised in January 2020. Based on the article by Brunnström and Barkowsky [7], it was recognized and pointed out by VQEG that this Recommendation, which is very useful, lacked a section on the topic of multiple comparisons and its potential impact on the performance evaluations of objective quality methods. In the latest revision, Section 7.6.5 covers this topic.
Ongoing VQEG Inputs to ITU Recommendations
ITU-T Rec. P.919
ITU has been working on a recommendation for subjective test methodologies for 360º video on Head-Mounted Displays (HMDs), under the SG12 Question 13 (Q13). The Immersive Media Group (IMG) of the VQEG has collaborated in this effort through the fulfilment of the Phase 1 of the Test Plan for Quality Assessment of 360-degree Video. In particular, the Phase 1 of this test plan addresses the assessment of short sequences (less than 30 seconds), in the spirit of ITU-R BT.500 [8] and ITU-T P.910 [9]. In this sense, the evaluation of audiovisual quality and simulator sickness was considered. On the other hand, the Phase 2 of the test plan (envisioned for the near future) covers the assessment of other factors that can be more influential with longer sequences (several minutes), such as immersiveness and presence.
Therefore, within Phase 1 the IMG designed and executed a cross-lab test with the participation of ten international laboratories, from AGH University of Science and Technology (Poland), Centrum Wiskunde & Informatica (The Netherlands), Ghent University (Belgium), Nokia Bell-Labs (Spain), Roma TRE University (Italy), RISE Acreo (Sweden), TU Ilmenau (Germany), Universidad Politécnica de Madrid (Spain), University of Surrey (England), Wuhan University (China).
This test was aimed at assessing and validating subjective evaluation methodologies for 360º video. Thus, the single-stimulus methodology Absolute Category Rating (ACR) and the double-stimulus Degradation Category Rating (DCR) were considered to evaluate audiovisual quality of 360º videos distorted with uniform and non-uniform degradations. In particular, different configurations of uniform and tile-based coding were applied to eight video sources with different spatial, temporal and exploration properties. Other influence factors were also studied, such as the influence of the sequence duration (from 10 to 30s) and the test setup (considering different HMDs and methods to collect the observers’ ratings, using audio or not, etc.). Finally, in addition to the evaluation of audiovisual quality, the assessment of simulator sickness symptoms was addressed studying the use of different questionnaires. As a result of this work, the IMG of VQEG presented two contributions to the recommendation ITU-T Rec. P.919 (ex P.360-VR), which has been consented in the last SG12 meeting (7-11 September 2020) and is envisioned to be published soon. In addition, the results and the annotated dataset coming from the cross-lab test will be published soon.
ITU-T Rec. P.913
Another upcoming contribution is prepared by the Statistical Analysis Group (SAM). The main goal of the proposal is to increase the precision of the subjective experiment analysis by describing a subjective answer as a random variable. The random variable is described by three key influencing factors, the sequence quality, a subject bias, and a subject precision. It is further development of the ITU-T P.913 [10] recommendation where subject bias was introduced. Adding subject precision allows for two achievements: Better handling unreliable subjects and easier estimation procedure.
Current standards describe a way to remove an unreliable subject. The problem is that the methods proposed in BT.500 [8] and P.913 [10] are different and point to different subjects. Also, both methods have some arbitrary parameters (e.g., thresholds) deciding when a subject should be removed. It means that two subjects can be similarly imprecise but one is over the threshold, and we accept all his answers as correct and the other is under the threshold, and we remove her all answers. The proposed method weights the impact of each subject answer depending on the subject precision. As the consequence, each subject is to some extent removed and kept. The balance between how much information we keep and how much we remove depends on the subject precision.
The estimation procedure of the proposed model, described in the literature, is MLE (Maximum Likelihood Estimation). Such estimation is computationally costly and needs a careful setup to obtain a reliable solution. Therefore, we proposed Alternating Projection (AP) solver which is less general than MLE but works as well as MLE for the subject model estimation. This solver is called “alternating projection” because, in a loop, we alternate between projecting (or averaging) the opinion scores along the subject dimension and the stimulus dimension. It increases the precision of the obtained model parameters’ step by step weighting more information coming from the more precise subjects. More details can be found in the white paper in [11].
Other updates
A new VQEG group has been recently established related to Quality Assessment for Health Applications (QAH), with the motivation to study visual quality requirements for medical imaging and telemedicine. The main goals of this new group are:
Assemble all the existing publicly accessible databases on medical quality.
Develop databases with new diagnostic tasks and new objective quality assessment models.
Provide methodologies, recommendations and guidelines for subjective test of medical image quality assessment.
Study the quality requirements and Quality of Experience in the context of telemedicine and other telehealth services.
For any further questions or expressions of interest to join this group, please contact QAH Chair Lu Zhang (lu.ge@insa-rennes.fr), Vice Chair Meriem Outtas (Meriem.Outtas@insa-rennes.fr), and Vice Chair Hantao Liu (hantao.liu@cs.cardiff.ac.uk).
Describe your journey into research from your youth up to the present. What foundational lessons did you learn from this journey? Why were you initially attracted to multimedia?
This is an excellent question. Indeed, life is a journey, and every step is a lesson. I was originally attracted by electronics but as I was studying it, I discovered computers. Remember, for those who were old enough in the 1980’s, this was the start of personal computers. So I decided to learn more about them, and as I was studying computer science I found out about AI, yes AI 1990’s style. I was interested, but this coincided with one of the AI winters and I was advised, or rather decided, to go in a different direction. The area that attracted me most was computer vision. The reason was that it seemed like a very hard problem which would clearly have a very broad impact. It turns out that vision alone is indeed very hard and using additional information or signals could help obtain better results, hence reducing time to impact for such a scientific approach/method. This was what attracted me to multimedia and kept me busy for many years at EURECOM. What did I learn along the way? Follow your instinct and your heart as you go along as it is rare to know where to go from the very start. Your destination might not even exist at the time you started your journey!
Tell us more about your vision and objectives behind your current roles? What do you hope to accomplish and how will you bring this about?
Since July 2019 I have headed the Data Science team of MEDIAN Technologies. The objective is to bring recent advances from the field of computer vision, neural networks, and also multimedia to part from the way medical imaging is currently performed while providing solutions to detect cancer at the earliest possible stage of the disease and help identify the best treatment for each patient. Concretely, we are currently working on the identification of biomarkers for Hepatocellular Carcinoma (HCC) which is the most common type of primary liver cancer and which is known to be a difficult organ for medical imaging solutions.
Can you profile your current research, its challenges, opportunities, and implications?
To answer this very broad question concisely, I will limit myself to one challenge, one opportunity, and one implication. For the challenge, I will mention one key challenge which I have encountered many times in many projects: Interdisciplinary communication. In most projects, whether small or large and involving multiple domains of expertise, the communication between people of different backgrounds is not as straightforward as one would assume. It is important to address this challenge proactively. For the opportunity, medical imaging is nowadays still mostly employing “traditional” machine learning on top of man-made features (Grey-Level Co-occurrence Matrices, Gabor, etc). The “end to end” paradigm shift brought in by the recent developments in the field of deep neural nets is still to take place in the medical domain at large. This is what we aim to achieve for medical imaging for Oncology. The implication, a significant improvement in the detection of cancer, such as the early detection of tumors. Such early detection allows for therapy to take place at the earliest possible stage hence drastically increasing the patient chance of survival. Saving lives in short.
How would you describe your top innovative achievements in terms of the problems you were trying to solve, your solutions, and the impact it has today and into the future?
There is a
number of research work originating from my team that would be worth mentioning
here; EventEnricher for collecting media illustrating event, the Hyper Video Browser,
an interactive tool for searching and hyperlinking in broadcast media, or the
work resulting from the collaborative project NexGen-TV:
Providing real-time insight during political debates in a second screen
application… to name just a few.
But the one with the highest impact is the work performed while on sabbatical at IBM T.J. Watson research center. As I onboarded, the research group received a request from the 20th Century Fox, regarding the possibility for some AI to help generate the trailer of a sci-fi horror movie that was about to be released. The project was both challenging and interesting as I had previously addressed video summarization and multimedia emotion recognition as part of previous research projects. The challenge was the limited amount of time available to deliver the shots which using state of the art machine learning were identified as the best suited to be part of the trailer. The team worked hard and hard work was rewarded multiple times. First because the hard deadline was met, having the “AI Trailer” on time for the screening of the movie in the US. Second because Fox sent a whole video crew to shoot the making of the trailer behind the scene. The video was posted on YouTube and got about 2 million views in about a week. This was the level of impact this scientific research work had. And if that was not enough, the work got another reward at the ACM Multimedia 2017 conference for being the Best Brave New Ideas paper that year.
Over your distinguished career, what are your top lessons you want to share with the audience?
Over the years I have observed that as a researcher, one needs to be curious while being able to find a good compromise between being focused and exploring new or alternative options/approaches. I feel that it is easy for today’s young researchers to be overwhelmed with the pace at which high-quality publications are becoming available. Social media (i.e. Twitter) and online repositories (i.e. Arxiv) are no stranger to this situation. There will always be a new paper reporting something potentially interesting with respect to your research, yet it doesn’t mean you should keep reading and reading at the cost of making slow or no progress on your own work! Reading and being aware of the state of the art is one thing, contributing and being innovative is another and the latter is the key to a successful PhD. Life as a researcher whether in academia or in the industry is made of choices, directions to follow, etc. While more senior people may sometimes rely on their experience, I believe it is important to listen to your inner self and follow what motivates you whenever possible. I have always believed and often witnessed that it is easier to work toward something of interest (to yourself) and in most cases the outcome exceeds expectations.
What is the best joke you know?
I have a very bad memory for jokes. Tell me one and I will laugh because I have a good sense of humor. But ask me to tell the story the next day and I will not be able to. So I looked jokes on the internet and here is the first one that made me laugh (I did read quite a few before!!!):
Two men
meet on opposite sides of a river. One shouts to the other, “I need
you to help me get to the other side!” The other guy replies,
“You’re on the
other side!”
Not the best, but it will do for now!
If you were conducting this interview, what questions would you ask, and then what would be your answers?
The COVID-19 pandemic is affecting people’s lives on an international scale, do you think this will have an influence on research and in particular multimedia research?
Indeed, the situation is forcing us to change the way we collaborate and interact. As a researcher, one regularly travels for project meetings, conferences, PhD presentations, etc. in addition to local activities and events such as teaching, labs, group meetings, etc. With current travel restrictions and social distancing recommendations, remote work relying heavily on high bandwidth internet has developed to an unprecedented level, exposing both its limitations and advantages. Similarly, scientific conferences where a lot of interaction takes place have been forced to adapt. At first, organizers postponed the events, hoping the situation will quickly return to normal. However, with the extended duration of the pandemic, the shift from physical to remote or virtual conferencing, using online tools and systems, had to be performed. This clearly demonstrated not only the possibility of organizing such events online but also showed some limitations regarding interaction. On this topic, this could be a great opportunity for the multimedia community to have an impact at large. Indeed, who would be better suited to contribute to the next generation of tools for effective interactive remote work and conferencing than the multimedia community. I believe we have a role to play and look forward to seeing and using such tools. I didn’t touch on the health aspect of this question but that is also something multimedia researchers, usually well acquainted with the state of the art machine learning, can contribute to. On that note, if Medical Imaging is a topic that attracts you and that you are motivated by, do not hesitate to reach out.
Disclaimer:
All views expressed in this interview are my own and do not represent the
opinions of any entity with which I have been or am now affiliated.
A recent photo of Benoit.
Bio: Benoit Huet heads the data science team at MEDIAN Technologies. His research interests include computer vision, machine learning, and large-scale multimedia data mining and indexing.
The 88th JPEG meeting initially planned to be held in Geneva, Switzerland, was held online because of the Covid-19 outbreak.
JPEG experts organised a large number of sessions spread over day and night to allow the remote participation of multiple time zones. A very intense activity has resulted in multiple outputs and initiatives. In particular two new explorations activities were initiated. The first explores possible standardisation needs to address the growing emergence of fake media by introducing appropriate security features to prevent the misuse of media content. The latest, considers the use of DNA for media content archival.
Furthermore, JPEG has started the work on the new part 8 of the JPEG Systems standard, called JPEG snack, for interoperable rich image experiences, and it is holding two Call
for Evidence, JPEG AI and JPEG Pleno Point cloud
coding.
Despite travel restrictions, JPEG Committee has managed to keep up with the majority of its plans, defined prior to the COVID-19 outbreak. An overview of the different activities is represented in Fig. 1.
Figure 1 – JPEG Planned Timeline.
The 88th JPEG meeting had the following highlights:
JPEG explores standardization needs to address fake media
JPEG Pleno Point Cloud call for evidence
JPEG DNA – based archival of media content using DNA
JPEG AI call for evidence
JPEG XL standard evolves to a final specification
JPEG Systems part 8, named JPEG Snack progress
JPEG XS Part-1 2nd Edition first ballot.
JPEG explores standardization
needs to address fake media
Recent advances in media manipulation, particularly
deep learning-based approaches, can produce near realistic media content that
is almost indistinguishable from authentic content to the human eye. These
developments open opportunities for production of new types of media contents
that are useful for the entertainment industry and other business usage, e.g.,
creation of special effects or artificial natural scene production with actors
in the studio. However, this also leads to issues relating to fake media
generation undermining the integrity of the media (e.g., deepfakes), copyright
infringements and defamation to mention a few examples. Misuse of manipulated
media can cause social unrest, spread rumours for political gain or encourage
hate crimes. In this context, the term ‘fake’ is used here to refer to any
manipulated media, independently of its ‘good’ or ‘bad’ intention.
In many application domains, fake media producers may
want or may be required to declare the type of manipulations performed, in
opposition to other situations where the intention is to ‘hide’ the mere existence
of such manipulations. This is already leading various Governmental
organizations to plan new legislation or companies (especially social media
platforms or news outlets) to develop mechanisms that would clearly detect and
annotate manipulated media contents when they are shared. While growing efforts
are noticeable in developing technologies, there is a need to have a standard
for the media/metadata format, e.g., a JPEG standard that facilitates a secure
and reliable annotation of fake media, both in good faith and malicious usage
scenarios. To better understand the fake media ecosystem and needs in terms of
standardization, the JPEG Committee has initiated an in-depth
analysis of fake media use cases, naturally independently of the “intentions”.
More information on the initiative is available on the
JPEG website. Interested parties are invited to join the above AHG through
the following URL: http://listregistration.jpeg.org.
JPEG Pleno Point Cloud
JPEG Pleno is working towards the integration of various modalities of plenoptic content under a single and seamless framework. Efficient and powerful point cloud representation is a key feature within this vision. Point cloud data supports a wide range of applications including computer-aided manufacturing, entertainment, cultural heritage preservation, scientific research and advanced sensing and analysis. During the 88th JPEG meeting, the JPEG Committee released a Final Call for Evidence on JPEG Pleno Point Cloud Coding that focuses specifically on point cloud coding solutions supporting scalability and random access of decoded point clouds. Between the 88th and 89th meetings, the JPEG Committee will be actively promoting this activity and collecting registrations to participate in the Call for Evidence.
JPEG DNA
In digital media information, notably images, the relevant representation symbols, e.g. quantized DCT coefficients, are expressed in bits (i.e., binary units) but they could be expressed in any other units, for example the DNA units which follow a 4-ary representation basis. This would mean that DNA molecules may be created with a specific DNA units’ configuration which stores some media representation symbols, e.g. the symbols of a JPEG image, thus leading to DNA-based media storage as a form of molecular data storage. JPEG standards have been used in storage and archival of digital pictures as well as moving images. While the legacy JPEG format is widely used for photo storage in SD cards, as well as archival of pictures by consumers, JPEG 2000 as described in ISO/IEC 15444 is used in many archival applications, notably for preservation of cultural heritage in form of visual data as pictures and video in digital format. This puts the JPEG Committee in a unique position to address the challenges in DNA-based storage by creating a standard image representation and coding for such applications. To explore the latter, an AHG has been established. Interested parties are invited to join the above AHG through the following URL: http://listregistration.jpeg.org.
JPEG AI
At the 88th meeting, the submissions to the Call for Evidence were reported and analysed. Six submissions were received in response to the Call for Evidence made in coordination with the IEEE MMSP 2020 Challenge. The submissions along with the anchors were already evaluated using objective quality metrics. Following this initial process, subjective experiments have been designed to compare the performance of all submissions. Thus, during this meeting, the main focus of JPEG AI was on the presentation and discussion of the objective performance evaluation of all submissions as well as the definition of the methodology for the subjective evaluation that will be made next.
JPEG XL
The standardization of
the JPEG XL image coding system is nearing completion. Final technical comments
by national bodies have been received for the codestream (Part 1); the DIS has
been approved and an FDIS text is under preparation. The container file format
(Part 2) is progressing to the DIS stage. A white paper summarizing key
features of JPEG XL is available at http://ds.jpeg.org/whitepapers/jpeg-xl-whitepaper.pdf.
JPEG Systems
ISO/IEC has approved the JPEG Snack initiative to deliver interoperable rich image experiences. As a result, the JPEG Systems Part 8 (ISO/IEC 19566-8) has been created to define the file format construction and the metadata signalling and descriptions which enable animation with transition effects. A Call for Participation and updated use cases and requirements have been issued. The CfP and the use cases and requirements documents are available at http://ds.jpeg.org/documents/wg1n87035-REQ-JPEG_Snack_Use_Cases_and_Requirements_v2_2.pdf and http://ds.jpeg.org/documents/wg1n88032-SI-CfP_JPEG_Snack.pdf respectively.
The JPEG committee is
pleased to announce a significant step in the standardization of an efficient
Bayer image compression scheme, with the first ballot of the 2nd Edition of
JPEG XS Part-1.
The new edition of this visually lossless low-latency and lightweight compression scheme now includes image sensor coding tools allowing efficient compression of Color-Filtered Array (CFA) data. This compression enables better quality and lower complexity than the corresponding compression in the RGB domain. It can be used as a mezzanine codec in various markets such as real-time video storage in and outside of cameras, and data compression onboard autonomous cars.
Final Quote
“Fake Media has become a challenge with the wide-spread manipulated contents in the news. JPEG is determined to mitigate this problem by providing standards that can securely identify manipulated contents.” said Prof. Touradj Ebrahimi, the Convenor of the JPEG Committee.
Future JPEG meetings are planned as
follows:
No 89, will be held online from October 5 to 9, 2020.
Telepresence robots (TPRs) are remote-controlled, wheeled devices with an internet connection. A TPR can “teleport” you to a remote location, let you drive around and interact with people. A TPR user can feel present in the remote location by being able to control the robot position, movements, actions, voice and video. A TPR facilitates human-to-human interaction, wherever you want and whenever you want. The human user sends commands to the TPR by pressing buttons or keys from a keyboard, mouse, or joystick.
A Robotic Telepresence Environment
In recent years, people from different environments and backgrounds have started to adopt TPRs for private and business purposes such as attending a class, roaming around the office and visiting patients. Due to the COVID-19 pandemic, adoption in healthcare has increased in order to facilitate social distancing and staff safety [Ackerman 2020, Tavakoli et al. 2020].
Robotic Telepresence Sample Use Cases
Despite such increase in adoption, a research gap remains from a QoE
perspective, as TPRs offer interaction beyond the well understood QoE issues in
traditional static audio-visual conferencing. TPRs, as remote-controlled
vehicles, enable users with some form of physical presence at the remote
location. Furthermore, for those people interacting with the TPR at the remote
location, the robot is a physical representation or proxy agent of its remote
operator. The operator can physically interact with the remote location by
driving over an object or pushing an object forward. These aspects of
teleoperation and navigation represent an additional dimension in terms of functionality,
complexity and experience.
Navigating a TPR may pose challenges to end-users and influence their
perceived quality of the system. For instance, when a TPR operator is driving
the robot, he/she expects an instantaneous reaction from the robot. An
increased delay in sending commands to the robot may thus negatively impact
robot mobility and the user’s satisfaction, even if the audio-visual
communication functionality itself is not affected.
In a recent paper published at QoMEX 2020 [Jahromi et al. 2020], we addressed this gap in research by means of a subjective QoE experiment that focused on the QoE aspects of live TPR teleoperation over the internet. We were interested in understanding how network QoS-related factors influence the operator’s QoE when using a TPR in an office context.
TPR QoE User
Study and Experimental Findings
In our study, we investigated the QoE of TPR navigation along three
research questions: 1) impact of network factors including bandwidth, delay and
packet loss on the TPR navigation QoE, 2) discrimination between navigation QoE
and video QoE, 3) impact of task on TPR QoE sensitivity.
The QoE study participants were situated in a laboratory setting in Dublin, Ireland, where they navigated a Beam Plus TPR via keyboard input on a desktop computer. The TPR was placed in a real office setting of California Telecom in California, USA. Bandwidth, delay and packet loss rate were manipulated on the operator’s PC.
A User Participating in the Robotic Telepresence QoE Study
A total of 23 subjects participated in our QoE lab study: 8 subjects
were female and 15 male and the average test duration was 30 minutes per
participant. We followed ITU-T
Recommendation BT.500 and detected three participants as outliers which were
excluded from subsequent analysis. A post-test survey shows that none of the
participants reported task boredom as a factor. In fact, many reported that
they enjoyed the experience!
The influence
of network factors on Navigation QoE
All three network influence factors exhibited a significant impact on navigation QoE but in different ways. Above a threshold of 0.9 Mbps, bandwidth showed no influence on navigation QoE, while 1% packet loss already showed a noticeable impact on the navigation QoE. A mixed-model ANOVA confirms that the impact of the different network factors on navigation quality ratings is statistically significant (see [Jahromi et al. 2020] for details). From the figure below, one can see that the levels of navigation QoE MOS, as well as their sensitivity to network impairment level, depend on the actual impairment type.
The bar plots illustrate the influence of network QoS factors on the navigation quality (left) and the video quality (right).
Discrimination
between navigation QoE and video QoE
Our study results show that the subjects were capable of discriminating between video quality and navigation quality, as they treated them as separate concepts when it comes to experience assessment. Based on ANOVA analysis [Jahromi et al. 2020], we see that the impact of bandwidth and packet loss on TPR video quality ratings were statistically significant. However, for the delay, this was not the case (in contrast to navigation quality). A comparison of navigation quality and video quality subplots shows that changes in MOS across different impairment levels diverge between the two in terms of amplitude. To quantify this divergence, we performed a Spearman Rank Ordered Correlation Coefficient (SROCC) analysis, revealing only a weak correlation between video and navigation quality (SROCC =0.47).
Impact of
task on TPR QoE sensitivity
Our study showed that the type of TPR task had more impact on
navigation QoE than streaming video QoE. Statistical analysis reveals that the
actual task at hand significantly affects QoE impairment sensitivity, depending
on the network impairment type. For example, the interaction between bandwidth
and task is statistically significant for navigation QoE, which means that
changes in bandwidth were rated differently depending on the task type. On the
other hand, this was not the case for delay and packet loss. Regarding video
quality, we do not see a significant impact of task on QoE sensitivity to
network impairments, except for the borderline case for packet loss rate.
Conclusion:
Towards a TPR QoE Research Agenda
There were three key findings from this study. First, we understand
that users can differentiate between visual and navigation aspects of TPR
operation. Secondly, all three network factors have a significant impact on TPR
navigation QoE. Thirdly, visual and
navigation QoE sensitivity to specific impairments strongly depends on the
actual task at hand. We also found the initial training phase to be essential
in order to ensure familiarity of participants with the system and to avoid
bias caused by novelty effects. We observed that participants were highly
engaged when navigating the TPR, as was also reflected in the positive feedback
received during the debriefing interviews. We believe that our study
methodology and design, including task types, worked very well and can serve as
a solid basis for future TPR QoE studies.
We also see the necessity of developing a more generic, empirically validated, TPR experience framework that allows for systematic assessment and modelling of QoE and UX in the context of TPR usage. Beyond integrating concepts and constructs that have been already developed in other related domains such as (multi-party) telepresence, XR, gaming, embodiment and human-robot interaction, the development of such a framework must take into account the unique properties that distinguish the TPR experience from other technologies:
Asymmetric conditions The factors influencing QoE for TPR users are not only bidirectional, they are also different on both sides of TPR, i.e., the experience is asymmetric. Considering the differences between the local and the remote location, a TPR setup features a noticeable number of asymmetric conditions as regards the number of users, content, context, and even stimuli: while the robot is typically controlled by a single operator, the remote location may host a number of users (asymmetry in the number of users). An asymmetry also exists in the number of stimuli. For instance, the remote users perceive the physical movement and presence of the operator by the actual movement of the TPR. The experience of encountering a TPR rolling into an office is a hybrid kind of intrusion, somewhere between a robot and a physical person. However, from the operator’s perspective, the experience is a rather virtual one, as he/she only becomes conscious of physical impact at the remote location only by means of technically mediated feedback.
Social Dimensions According to [Haans et al. 2012], the experience of telepresence is defined as “a consequence of the way in which we are embodied, and that the capability to feel as if one is actually there in a technologically mediated or simulated environment is a natural consequence of the same ability that allows us to adjust to, for example, a slippery surface or the weight of a hammer”. The experience of being present in a TPR-mediated context goes beyond AR and VR. It is a blended physical reality. The sense of ownership of a wheeled TPR by means of mobility and remote navigation of using a “physical” object, allows the users to feel as if they are physically present in the remote environment (e.g. a physical avatar). This allows the TPR users to get involved in social activities, such as accompanying people and participating in discussions while navigating, sharing the same visual scenes, visiting a place and getting involved in social discussions, parties and celebrations. In healthcare, a doctor can use TPR for visiting patients as well as dispensing and administering medication remotely.
TPR Mobility and Physical Environment Mobility is a key dimension of telepresence frameworks [Rae et al. 2015]. TPR mobility and navigation features introduce new interactions between the operators and the physical environment. The environmental aspect becomes an integral part of the interaction experience [Hammer et al. 2018]. During a TPR usage, the navigation path and the number of obstacles that a remote user may face can influence the user’s experience. The ease or complexity of navigation can change the operator’s focus and attention from one influence factor to another (e.g., video quality to navigation quality). In Paloski et al’s, 2008 study, it was found that cognitive impairment as a result of fatigue can influence user performance concerning robot operation [Paloski et al. 2008]. This raises the question of how driving and interaction through TPR impacts the user’s cognitive load and results in fatigue compared to physical presence. The mobility aspects of TPRs can also influence the perception of spatial configurations of the physical environment. This allows the TPR user to manipulate and interact with the environment from a spatial configuration aspect [Narbutt et al. 2017]. For example, the ambient noise of the environment can be perceived at different levels. The TPR operator can move the robot closer to the source of the noise or keep a distance from it. This can enhance his/her feelings of being present [Rae et al. 2015].
Above distinctive characteristics of a TPR-mediated context illustrate the complexity and the broad range of aspects that potentially have a significant influence on the TPR quality of user experience. Consideration of these features and factors provides a useful basis for the development of a comprehensive TPR experience framework.
References
[Tavakoli et al. 2020] Tavakoli, Mahdi, Carriere, Jay and Torabi, Ali. (2020). Robotics For COVID-19: How Can Robots Help Health Care in the Fight Against Coronavirus.
[Jahromi et al. 2020] H. Z. Jahromi, I. Bartolec, E. Gamboa, A. Hines, and R. Schatz, “You Drive Me Crazy! Interactive QoE Assessment for Telepresence Robot Control,” in 12th International Conference on Quality of Multimedia Experience (QoMEX 2020), Athlone, Ireland, 2020.
[Hammer et al. 2018] F. Hammer, S. Egger-Lampl, and S. Möller, “Quality-of-user-experience: a position paper,” Quality and User Experience, vol. 3, no. 1, Dec. 2018, doi: 10.1007/s41233-018-0022-0.
[Haans et al. 2012] A. Haans & W. A. Ijsselsteijn (2012). Embodiment and telepresence: Toward a comprehensive theoretical framework✩. Interacting with Computers, 24(4), 211-218.
[Rae et al. 2015] I. Rae, G. Venolia, JC. Tang, D. Molnar (2015, February). A framework for understanding and designing telepresence. In Proceedings of the 18th ACM conference on computer supported cooperative work & social computing (pp. 1552-1566).
[Narbutt et al. 2017] M. Narbutt, S. O’Leary, A. Allen, J. Skoglund, & A. Hines, (2017, October). Streaming VR for immersion: Quality aspects of compressed spatial audio. In 2017 23rd International Conference on Virtual System & Multimedia (VSMM) (pp. 1-6). IEEE.
[Paloski et al. 2008] W. H. Paloski, C. M. Oman, J. J. Bloomberg, M. F. Reschke, S. J. Wood, D. L. Harm, … & L. S. Stone (2008). Risk of sensory-motor performance failures affecting vehicle control during space missions: a review of the evidence. Journal of Gravitational Physiology, 15(2), 1-29.
Information retrieval and multimedia content access have a long history of comparative evaluation, and many of the advances in the area over the past decade can be attributed to the availability of open datasets that support comparative and repeatable experimentation. Hence, sharing data and code to allow other researchers to replicate research results is needed in the multimedia modeling field, as it helps to improve the performance of systems and the reproducibility of published papers.
This report summarizes the special session on Multimedia Datasets for Repeatable Experimentation (MDRE 2020), which was organized at the 26th International Conference on MultiMedia Modeling (MMM 2020), held in January 2020 in Daejeon, South Korea.
The intent of these special sessions is to be a venue for releasing datasets to the multimedia community and discussing dataset related issues. The presentation mode in 2020 was to have short presentations (approximately 8 minutes), followed by a panel discussion moderated by Aaron Duane. In the following we summarize the special session, including its talks, questions, and discussions.
The session began with a presentation on ‘GLENDA: Gynecologic Laparoscopy Endometriosis Dataset’ [1], given by Andreas Leibetseder from the University of Klagenfurt. The researchers worked with experts on gynecologic laparoscopy, a type of minimally invasive surgery (MIS), that is performed via a live feed of a patient’s abdomen to survey the insertion and handling of various instruments for conducting medical treatments. Adopting this kind of surgical intervention not only facilitates a great variety of treatments but also the possibility of recording such video streams is essential for numerous post-surgical activities, such as treatment planning, case documentation and education. The process of manually analyzing these surgical recordings, as it is carried out in current practice, usually proves tediously time-consuming. In order to improve upon this situation, more sophisticated computer vision as well as machine learning approaches are actively being developed. Since most of these approaches rely heavily on sample data that, especially in the medical field, is only sparsely available, the researchers published the Gynecologic Laparoscopy ENdometriosis DAtaset (GLENDA) – an image dataset containing region-based annotations of a common medical condition called endometriosis.
Endometriosis is a disorder involving the dislocation of uterine-like tissue. Andreas explained that this dataset is the first of its kind and was created in collaboration with leading medical experts in the field. GLENDA contains over 25K images, about half of which are pathological, i.e., showing endometriosis, and the other half non-pathological, i.e., containing no visible endometriosis. The accompanying paper thoroughly described the data collection process, the dataset’s properties and structure, while also discussing its limitations. The authors plan on continuously extending GLENDA, including the addition of other relevant categories and ultimately lesion severities. Furthermore, they are in the process of collecting specific ”endometriosis suspicion” class annotations in all categories for capturing a common situation where at times it proves difficult, even for endometriosis specialists, to classify the anomaly without further inspection. The difficulty in classification may be due to several reasons, such as visible video artifacts. Including such challenging examples in the dataset may greatly improve the quality of endometriosis classifiers.
Kvasir-SEG: A Segmented Polyp Dataset
The second presentation was given by Debesh Jha from the Simula Research Laboratory, who introduced the work entitled ‘Kvasir-SEG: A Segmented Polyp Dataset’ [2]. Debesh explained that pixel-wise image segmentation is a highly demanding task in medical image analysis. Similar to the aforementioned GLENDA dataset, it is difficult to find annotated medical images with corresponding segmentation masks in practice. The Kvasir-SEG dataset is an open-access corpus of gastrointestinal polyp images and corresponding segmentation masks, which has been further manually annotated and verified by an experienced gastroenterologist. The researchers demonstrated the use of their dataset with both a traditional segmentation approach and a modern deep learning-based CNN approach. In addition to presenting the Kvasir-SEG dataset, Debesh also discussed the FCM clustering algorithm and the ResUNet-based approach for automatic polyp segmentation they presented in their paper. The results show that the ResUNet model was superior to FCM clustering.
The researchers released the Kvasir-SEG dataset as an open-source dataset to the multimedia and medical research communities, in the hope that it can help evaluate and compare existing and future computer vision methods. By adding segmentation masks to the Kvasir dataset, which until today only consisted of framewise annotations, the authors have enabled multimedia and computer vision researchers to contribute in the field of polyp segmentation and automatic analysis of colonoscopy videos. This could boost the performance of other computer vision methods and may be an important step towards building clinically acceptable CAI methods for improved patient care.
Rethinking the Test Collection Methodology for Personal Self-Tracking Data
The third presentation was given by Cathal Gurrin from Dublin City University and was titled ‘Rethinking the Test Collection Methodology for Personal Self-Tracking Data’ [3]. Cathal argued that, although vast volumes of personal data are being gathered daily by individuals, the MMM community has not really been tackling the challenge of developing novel retrieval algorithms for this data, due to the challenges of getting access to the data in the first place. While initial efforts have taken place on a small scale, it is their conjecture that a new evaluation paradigm is required in order to make progress in analysing, modeling and retrieving from personal data archives. In their position paper, the researchers proposed a new model of Evaluation-as-a-Service that re-imagines the test collection methodology for personal multimedia data in order to address the many challenges of releasing test collections of personal multimedia data.
After providing a detailed overview of prior research on the creation and use of self-tracking data for research, the authors identified issues that emerge when creating test collections of self-tracking data as commonly used by shared evaluation campaigns. This includes in particular the challenge of finding self-trackers willing to share their data, legal constraints that require expensive data preparation and cleaning before a potential release to the public, as well as ethical considerations. The Evaluation-as-a-Service model is a novel evaluation paradigm meant to address these challenges by enabling collaborative research on personal self-tracking data. The model relies on the idea of a central data infrastructure that guarantees full protection of the data, while at the same time allowing algorithms to operate on this protected data. Cathal highlighted the importance of data banks in this scenario. Finally, he briefly outlined technical aspects that would allow setting up a shared evaluation campaign on self-tracking data.
Experiences and Insights from the Collection of a Novel Multimedia EEG Dataset
The final presentation of the session was also provided by Cathal Gurrin from Dublin City University in which he introduced the topic ‘Experiences and Insights from the Collection of a Novel Multimedia EEG Dataset’ [4]. This work described how there is a growing interest in utilising novel signal sources such as EEG (Electroencephalography) in multimedia research. When using such signals, subtle limitations are often not readily apparent without significant domain expertise. Multimedia research outputs incorporating EEG signals can fail to be replicated when only minor modifications have been made to an experiment or seemingly unimportant (or unstated) details are changed. Cathal claimed that this can lead to over-optimistic or over-pessimistic viewpoints on the potential real-world utility of these signals in multimedia research activities.
In their paper, the researchers described the EEG/MM dataset and presented a summary of distilled experiences and knowledge gained during the preparation (and utilisation) of the dataset that supported a collaborative neural-image labelling benchmarking task. They stated that the goal of this task was to collaboratively identify machine learning approaches that would support the use of EEG signals in areas such as image labelling and multimedia modeling or retrieval. The researchers stressed that this research is relevant for the multimedia community as it suggests a template experimental paradigm (along with datasets and a baseline system) upon which researchers can explore multimedia image labelling using a brain-computer interface. In addition, the paper provided insights and experience of commonly encountered issues (and useful signals) when conducting research that utilises EEG in multimedia contexts. Finally, this work provided insight on how an EEG dataset can be used to support a collaborative neural-image labelling benchmarking task.
Discussion
After the presentations, Aaron Duane moderated a panel discussion in which all presenters participated, as well as Björn Þór Jónsson who joined the panel as one of the special session chairs.
The panel began with a question about how the research community should address data anonymity in large multimedia datasets and how, even if the dataset is isolated and anonymised, data analysis techniques can be utilised to reverse this process either partially or completely. The panel agreed this was an important question and acknowledged that there is no simple answer. Cathal Gurrin stated that there is less of a restrictive onus on the datasets used for such research because the owners of the dataset often provide it with full knowledge of how it will be used.
As a follow up, the questioner asked the panel about GDPR compliancy in this context and the fact that uploaders could potentially change their minds about allowing their datasets to be used in research several years after it was released. The panel acknowledged this remains an open concern and even expanded on such concerns by presenting an additional concern, namely the malicious uploading of data without the consent of the owner. One solution to this which was provided by the panel was the introduction of an additional layer of security in the form of a human curator who could review the security and privacy concerns of a dataset during its generation, as is the case with some datasets of personal data currently under release to the community.
The discussion continued with much interest continuing to be directed toward effective privacy in datasets, especially when dealing with personal data, such as those generated by lifeloggers. One audience member recalled a story where a personal dataset was publicly released and individuals were able to garner personal information about individuals who were not the original uploader of the dataset and who did not consent to their face or personal information being publicly released. Cathal and Björn acknowledged that this remains an issue but drew attention to advanced censoring techniques such as automatic face blurring which is rapidly maturing in the domain. Furthermore, they claimed that the proposed model of Evaluation-as-a-Service discussed in Cathal’s earlier presentation could help to further alleviate some of these concerns.
Steering the conversation away from exclusively dealing with data privacy concerns, Aaron directed a question at Debesh and Andreas regarding the challenges and limitations associated with working directly with medical professionals to generate their datasets related to medical disorders. Debesh stated that there were numerous challenges such as the medical professionals being unfamiliar with the tools used in the generation of this work and that in many cases circumstances required multiple medical professionals and their opinion as they would often disagree. This generated significant technical and administrative overhead for the researchers and their work which resulted in a tedious speed of progress. Andreas stated that such issues were identical for him and his colleagues and highlighted the importance of effective communication between the medical experts and the technical researchers.
Towards the end of the discussion, the panel discussed the concept of encouraging the release of more large-scale multimedia datasets for experimentation and what challenges are currently associated with that. The panel responded that the process remains difficult but having special sessions such as this are very helpful. The recognition of papers associated with multimedia datasets is becoming increasingly apparent with many exceptional papers earning hundreds of citations within the community. The panel also stated that we should be mindful of the nature of each dataset as releasing the same type of dataset, again and again, is not beneficial and has the potential to do more harm than good.
Conclusions
The MDRE special session, in its second incarnation at MMM 2020, was organised to facilitate the publication of high-quality datasets, and for community discussions on the methodology of dataset creation. The creation of reliable and shareable research artifacts, such as datasets with reliable ground truths, usually represents tremendous effort; effort that is rarely valued by publication venues, funding agencies or research institutions. In turn, this leads many researchers to focus on short-term research goals, with an emphasis on improving results on existing and often outdated datasets by small margins, rather than boldly venturing where no researchers have gone before. Overall, we believe that more emphasis on reliable and reproducible results would serve our community well, and the MDRE special session is a small effort towards that goal.
Acknowledgements
The session was organized by the authors of the report, in collaboration with Duc-Tien Dang-Nguyen (Dublin City University), who could not attend MMM. The panel format of the special session made the discussions much more engaging than that of a traditional special session. We would like to thank the presenters, and their co-authors for their excellent contributions, as well as the members of the audience who contributed greatly to the session.
References
[1] Leibetseder A., Kletz S., Schoeffmann K., Keckstein S., and Keckstein J. “GLENDA: Gynecologic Laparoscopy Endometriosis Dataset.” In: Cheng WH. et al. (eds) MultiMedia Modeling. MMM 2020. Lecture Notes in Computer Science, vol. 11962, 2020. Springer, Cham. https://doi.org/10.1007/978-3-030-37734-2_36.
[2] Jha D., Smedsrud P.H., Riegler M.A., Halvorsen P., De Lange T., Johansen D., and Johansen H.D. “Kvasir-SEG: A Segmented Polyp Dataset.” In: Cheng WH. et al. (eds) MultiMedia Modeling. MMM 2020. Lecture Notes in Computer Science, vol. 11962, 2020. Springer, Cham. https://doi.org/10.1007/978-3-030-37734-2_37.
[3] Hopfgartner F., Gurrin C., and Joho H. “Rethinking the Test Collection Methodology for Personal Self-tracking Data.” In: Cheng WH. et al. (eds) MultiMedia Modeling. MMM 2020. Lecture Notes in Computer Science, vol. 11962, 2020. Springer, Cham. https://doi.org/10.1007/978-3-030-37734-2_38.
[4] Healy G., Wang Z., Ward T., Smeaton A., and Gurrin C. “Experiences and Insights from the Collection of a Novel Multimedia EEG Dataset.” In: Cheng WH. et al. (eds) MultiMedia Modeling. MMM 2020. Lecture Notes in Computer Science, vol. 11962, 2020. Springer, Cham. https://doi.org/10.1007/978-3-030-37734-2_39.
The original blog post can be found at the Bitmovin Techblog and has been modified/updated here to focus on and highlight research aspects.
The 131st MPEG meeting concluded on July 3, 2020, online, again but with a press release comprising an impressive list of news items which is led by “MPEG Announces VVC – the Versatile Video Coding Standard”. Just in the middle of the SC 29 (i.e., MPEG’s parent body within ISO) restructuring process, MPEG successfully ratified — jointly with ITU-T’s VCEG within JVET — its next-generation video codec among other interesting results from the 131st MPEG meeting:
Standards progressing to final approval ballot (FDIS)
MPEG Announces VVC – the Versatile Video Coding Standard
Point Cloud Compression – MPEG promotes a Video-based Point Cloud Compression Technology to the FDIS stage
MPEG-H 3D Audio – MPEG promotes Baseline Profile for 3D Audio to the final stage
Call for Proposals
Call for Proposals on Technologies for MPEG-21 Contracts to Smart Contracts Conversion
MPEG issues a Call for Proposals on extension and improvements to ISO/IEC 23092 standard series
Standards progressing to the first milestone of the ISO standard development process
Widening support for storage and delivery of MPEG-5 EVC
Multi-Image Application Format adds support of HDR
Carriage of Geometry-based Point Cloud Data progresses to Committee Draft
MPEG Immersive Video (MIV) progresses to Committee Draft
Neural Network Compression for Multimedia Applications – MPEG progresses to Committee Draft
MPEG issues Committee Draft of Conformance and Reference Software for Essential Video Coding (EVC)
The corresponding press release of the 131st MPEG meeting can be found here: https://mpeg-standards.com/meetings/mpeg-131/. This report focused on video coding featuring VVC as well as PCC and systems aspects (i.e., file format, DASH).
MPEG Announces VVC – the Versatile Video Coding Standard
MPEG is pleased to announce the completion of the new Versatile Video Coding (VVC) standard at its 131st meeting. The document has been progressed to its final approval ballot as ISO/IEC 23090-3 and will also be known as H.266 in the ITU-T.
VVC Architecture (from IEEE ICME 2020 tutorial of Mathias Wien and Benjamin Bross)
VVC is the latest in a series of very successful standards for video coding that have been jointly developed with ITU-T, and it is the direct successor to the well-known and widely used High Efficiency Video Coding (HEVC) and Advanced Video Coding (AVC) standards (see architecture in the figure above). VVC provides a major benefit in compression over HEVC. Plans are underway to conduct a verification test with formal subjective testing to confirm that VVC achieves an estimated 50% bit rate reduction versus HEVC for equal subjective video quality. Test results have already demonstrated that VVC typically provides about a 40%-bit rate reduction for 4K/UHD video sequences in tests using objective metrics (i.e., PSNR, VMAF, MS-SSIM). Application areas especially targeted for the use of VVC include:
ultra-high definition 4K and 8K video,
video with a high dynamic range and wide colour gamut, and
video for immersive media applications such as 360° omnidirectional video.
Furthermore, VVC is designed for a wide variety of types of video such as camera captured, computer-generated, and mixed content for screen sharing, adaptive streaming, game streaming, video with scrolling text, etc. Conventional standard-definition and high-definition video content are also supported with similar gains in compression. In addition to improving coding efficiency, VVC also provides highly flexible syntax supporting such use cases as (i) subpicture bitstream extraction, (ii) bitstream merging, (iii) temporal sub-layering, and (iv) layered coding scalability.
The current performance of VVC compared to HEVC-HM is shown in the figure below which confirms the statement above but also highlights the increased complexity. Please note that VTM9 is not optimized for speed but functionality (i.e., compression efficiency).
MPEG also announces completion of ISO/IEC 23002-7 “Versatile supplemental enhancement information for coded video bitstreams” (VSEI), developed jointly with ITU-T as Rec. ITU-T H.274. The new VSEI standard specifies the syntax and semantics of video usability information (VUI) parameters and supplemental enhancement information (SEI) messages for use with coded video bitstreams. VSEI is especially intended for use with VVC, although it is drafted to be generic and flexible so that it may also be used with other types of coded video bitstreams. Once specified in VSEI, different video coding standards and systems-environment specifications can re-use the same SEI messages without the need for defining special-purpose data customized to the specific usage context.
At the same time, the Media Coding Industry Forum (MC-IF) announces a VVC patent pool fostering with an initial meeting on September 1, 2020. The aim of this meeting is to identify tasks and to propose a schedule for VVC pool fostering with the goal to select a pool facilitator/administrator by the end of 2020. MC-IF is not facilitating or administering a patent pool.
At the time of writing this blog post, it is probably too early to make an assessment of whether VVC will share the fate of HEVC or AVC (w.r.t. patent pooling). AVC is still the most widely used video codec but with AVC, HEVC, EVC, VVC, LCEVC, AV1, (AV2), and probably also AVS3 — did I miss anything? — the competition and pressure are certainly increasing.
Research aspects: from a research perspective, reduction of time-complexity (for a variety of use cases) while maintaining quality and bitrate at acceptable levels is probably the most relevant aspect. Improvements in individual building blocks of VVC by using artificial neural networks (ANNs) are another area of interest but also end-to-end aspects of video coding using ANNs will probably pave the roads towards the/a next generation of video codec(s). Utilizing VVC and its features for HTTP adaptive streaming (HAS) is probably most interesting for me but maybe also for others…
MPEG promotes a Video-based Point Cloud Compression Technology to the FDIS stage
At its 131st meeting, MPEG promoted its Video-based Point Cloud Compression (V-PCC) standard to the Final Draft International Standard (FDIS) stage. V-PCC addresses lossless and lossy coding of 3D point clouds with associated attributes such as colors and reflectance. Point clouds are typically represented by extremely large amounts of data, which is a significant barrier for mass-market applications. However, the relative ease to capture and render spatial information as point clouds compared to other volumetric video representations makes point clouds increasingly popular to present immersive volumetric data. With the current V-PCC encoder implementation providing compression in the range of 100:1 to 300:1, a dynamic point cloud of one million points could be encoded at 8 Mbit/s with good perceptual quality. Real-time decoding and rendering of V-PCC bitstreams have also been demonstrated on current mobile hardware. The V-PCC standard leverages video compression technologies and the video ecosystem in general (hardware acceleration, transmission services, and infrastructure) while enabling new kinds of applications. The V-PCC standard contains several profiles that leverage existing AVC and HEVC implementations, which may make them suitable to run on existing and emerging platforms. The standard is also extensible to upcoming video specifications such as Versatile Video Coding (VVC) and Essential Video Coding (EVC).
The V-PCC standard is based on Visual Volumetric Video-based Coding (V3C), which is expected to be re-used by other MPEG-I volumetric codecs under development. MPEG is also developing a standard for the carriage of V-PCC and V3C data (ISO/IEC 23090-10) which has been promoted to DIS status at the 130th MPEG meeting.
By providing high-level immersiveness at currently available bandwidths, the V-PCC standard is expected to enable several types of applications and services such as six Degrees of Freedom (6 DoF) immersive media, virtual reality (VR) / augmented reality (AR), immersive real-time communication and cultural heritage.
Research aspects: as V-PCC is video-based, we can probably state similar research aspects as for video codecs such as improving efficiency both for encoding and rendering as well as reduction of time complexity. During the development of V-PCC mainly HEVC (and AVC) has/have been used but it is definitely interesting to use also VVC for PCC. Finally, the dynamic adaptive streaming of V-PCC data is still in its infancy despite some articles published here and there.
MPEG Systems related News
Finally, I’d like to share news related to MPEG systems and the carriage of video data as depicted in the figure below. In particular, the carriage of VVC (and also EVC) has been now enabled in MPEG-2 Systems (specifically within the transport stream) and in the various file formats (specifically within the NAL file format). The latter is used also in CMAF and DASH which makes VVC (and also EVC) ready for HTTP adaptive streaming (HAS).
CMAF maintains a so-called “technologies under consideration” document which contains — among other things — a proposed VVC CMAF profile. Additionally, there are two exploration activities related to CMAF, i.e., (i) multi-stream support and (ii) storage, archiving, and content management for CMAF files.
DASH works on potential improvement for the first amendment to ISO/IEC 23009-1 4th edition related to CMAF support, events processing model, and other extensions. Additionally, there’s a working draft for a second amendment to ISO/IEC 23009-1 4th edition enabling bandwidth change signalling track and other enhancements. Furthermore, ISO/IEC 23009-8 (Session-based DASH operations) has been advanced to Draft International Standard (see also my last report).
An overview of the current status of MPEG-DASH can be found in the figure below.
The next meeting will be again an online meeting in October 2020.
Finally, MPEG organized a Webinar presenting results from the 131st MPEG meeting. The slides and video recordings are available here: https://bit.ly/mpeg131.
Click here for more information about MPEG meetings and their developments.









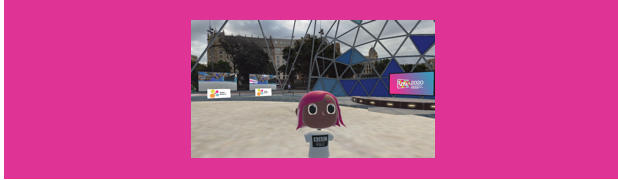
























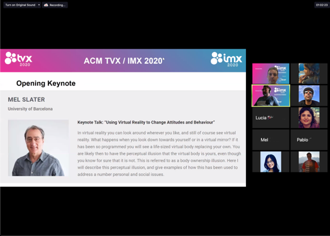


















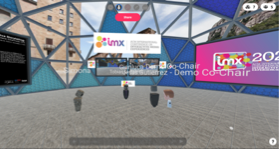



































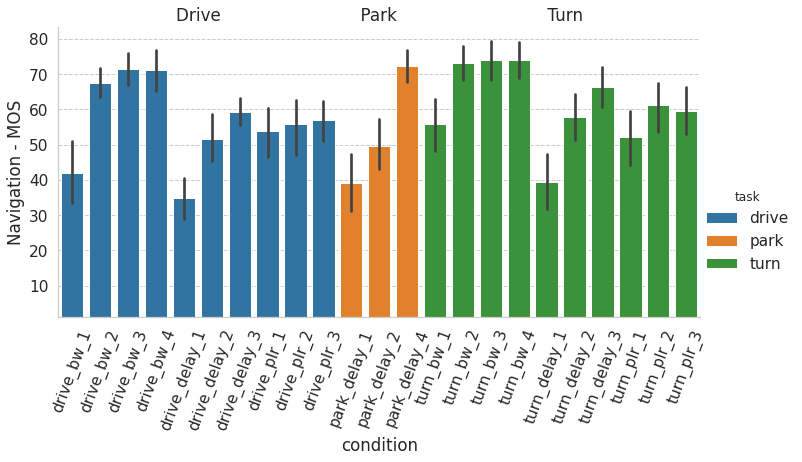




{kind=link}
{kind=link}
{kind=link}
{kind=link}