


Overview
The SIVA Suite is an open source framework for the creation, playback, and administration of hypervideos. Allowing the definition of complex navigational structures, our hypervideos are well suited for different scenarios. Compared to traditional linear videos, they especially excel in e-learning and training situations (see [1] and [2]), where fitting the teaching material to the needs of the viewer can be crucial. Other fields of application include virtual tours through buildings or cities, sports events, and interactive video stories. The SIVA Suite consists of an authoring tool (SIVA Producer), an HTML5 hypervideo player (SIVA Player), and a Web server (SIVA Server) for user and video management. It has been evaluated in various scenarios with several usability tests and has been improved step-by-step since 2008.
Introduction
The viewer of a traditional video takes a mostly passive role. Traditional videos are linear and cannot provide additional information about objects or scenes. In contrast to traditional linear videos, hypervideos are not only made of a sequence of video scenes. Their essence are alternative storylines, user choices, and additional materials which can be viewed in parallel with the main content as well as a navigational structure facilitating these features. Therefore, special players with extended controls and areas to present the additional information beyond the original content are necessary. The user choices in the video can be made at the selection of the follow-up scene on a button panel, a table of contents, as well as a keyword search.
One of the most advanced tools in this area is Hyper-Hitchcock [3] which can be used for the creation of detail-on-demand hypervideos with one main storyline and entry points for more detailed video explanations. However, an open source version of the software is not available. With new technologies like HTML5, CSS 3, and JavaScript, web-based tools like Klynt [4] emerged. Klynt allows the creation of hypervideos with focus on different media types and provides many useful features but can not be extended or customized due to the proprietary licensing. Finally, with the SIVA Suite we now offer the first customizable open source framework for the creation of hypervideos.
To simplify the creation process, our work focuses on videos as the main content. In the SIVA Producer, video scenes and navigational elements are arranged in a graph, called scene graph, to define the navigational structure of a hypervideo. Annotations offering additional information can be added to single scenes as well as to the whole video. For this purpose, images, texts, pdfs, audios, and even videos may be used. As a supplement to the video structure defined by the scene graph, further navigational elements like a table of contents and a keyword search enable the viewer to easily jump to points of interest.
Hypervideos are created in the SIVA Producer and then uploaded to the SIVA Server. Registered users can then download the video from the server or watch it online. If logging is enabled, user interactions during playback are logged by the player and sent to the database on the SIVA Server. Video administrators can access the logging data and watch different diagrams or export the data for further analysis in a statistics tool. An overview of the system is shown in Figure 1.

Figure 1. SIVA Suite – Overview.
SIVA Producer
| Reqirements (recommended): | Windows 7 or higher |
| Installation: | executable setup file |
| License: | Eclipse Public License (EPL) |
Installation files of the SIVA Producer can be found at https://github.com/SIVAteam/SIVA-Suite/tree/master/producer, an installer of the latest release can be found at https://github.com/SIVAteam/SIVA-Suite/releases.
The SIVA Producer is used for the creation of hypervideos where main video scenes are linked with each other in a scene graph. Each of the scenes may have one or more multimedia annotations. Further navigational structures are a table of contents as well as the definition of keywords which can then be searched for in the player. The GUI was implemented and improved step-by-step since 2008 [5]
First Steps
- Create a new project: A new project is created with a wizard. The author can set the appearance of the player as well as functions the player will provide. It is, for example, possible to select a primary and a secondary color, to determine the width of the annotation panel, etc.
- Add media files to the project: Media files are imported into the media repository. These may be videos, audios, images, or html files. The Producer uses each media file in its original format during the creation process and only transforms it during the export.
- Create scenes: From videos in the media repository, scenes can be extracted. Those will be added to the scene repository from where they can be dragged to the scene graph to create the hypervideo structure.
- Create a scene graph: A scene graph (see Figure 2) consists of a defined start and an end, as well as several scenes and connection/branching elements allowing advanced navigation options during playback of the video. Scenes and navigation elements are added to the scene graph via drag and drop. These elements are linked with the connection tool from the scene graph tool bar. In order to produce a valid and exportable scene graph, two conditions have to be met. First, only one start scene is allowed. Second, every scene has to be connected by some path to the start and to the end of the video. The validity of the scene graph can be checked with a validation function.
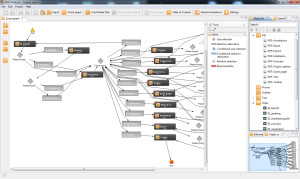
Figure 2. Scene graph of the SIVA Producer.
- Add annotations to scenes: Each scene in the scene graph may have one or more multimedia annotations. To add an annotation, a media file can either be dragged from the media repository and dropped on a scene, or an annotation editor (see Figure 3) can be used to customize its timing and appearance. Additionally, a hotspot can be added to the scene which invokes the display of the annotation only after a viewer clicks the marked area.

Figure 3. Annotation editor of the SIVA Producer.
- Export video project: In a last step, finished hypervideo projects with valid scene graphs are exported for the player. The structure of the hypervideo with all possible actions is converted into a JSON file. The media files are transformed and transcoded for the desired target platform.


Further Features
- Global annotations: Besides annotations which are displayed with scenes, global annotations which are displayed during the whole hypervideo (and do not have timing information as a consequence) can be added with a separate editor. The editor is opened from the main menu or the quick access toolbar.
- Keywords: Keywords can be added to scenes and annotations in the respective editors. They are added in whitespace-separated lists at the lower left part of the editors. Currently, only keywords added by the author are exported to the player and searchable with the search function, no automated analysis of the media files is performed.
- Table of contents: The table of contents editor (see Figure 4) is used to create a tree structure of entries with meaningful headlines. A scene from the scene graph can be linked with one of the entries in the table of contents. A scene is added to an entry in the table of contents via drag and drop. The editor is opened from the main menu or the quick access toolbar.
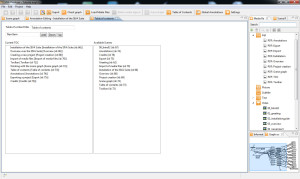
Figure 4. Table of contents editor of the SIVA Producer.
- Advanced navigation: Besides a standard selection element where the user may select one of the attached paths to continue playback in the player, more advanced elements are available as well:
- Forward button: A single button with only one label. It can be used to interrupt a linear sequence of scenes.
- Random selection: One of the attached paths will be selected at random without user interaction.
- Conditional selection: For attached paths, conditions can be defined which have to be fulfilled before the path is unlocked for playback.
- Project handover: The SIVA Producer provides a function for handing over a project to another computer. Using this function, all media files as well as the project file are copied into a given file structure where they can easily be copied from.
- Help: A help for the SIVA Producer can be found in the menu under “Help -> Help Contents“.

SIVA Player
| Reqirements (recommended): | Firefox 42.0, Chrome 46.0, Opera 33, Internet Explorer 11, Safari 10.10 |
| Installation: | use HTML export profile in SIVA Producer, then integrate it into a website via copying the body part of the exported HTML file and adapting the paths – or use as local stand-alone player |
| License: | GPLv3 |
Installation files are contained in the SIVA Producer at https://github.com/SIVAteam/SIVA-Suite/tree/master/producer/org.iviPro.ui/libs-native/HTML5player.
The SIVA Player is used to play the hypervideo created in the SIVA Producer. The structure and media elements of the hypervideo are described in a JSON file which conforms to the XML structure described in [6]. A previous versions of the player can be found in [7].

Figure 5. SIVA Player with video view and annotation area.
The playback of the described videos requires special players which are capable of providing navigational elements like selection panels for follow-up scenes, a table of contents, or a search function. Furthermore, areas for displaying additional information are necessary. Figure 5 shows a user interface of the player (with contents of a medical training scenario) with the following elements:
- (1) standard controls like pause/play
- (2) a progress bar (for the current video)
- (3) a settings button
- (4) a volume control
- (5) entry point to the table of contents
- (6) a button to jump to the previous scene
- (7) title of the currently displayed scene
- (8) a button to jump to the next scene (or to a selection panel)
- (9) a search button (performs a live search and refines the search results with every keystroke)
- (10) a button for the full-screen mode
- (11) a foldout panel on the right shows additional information (here, an additional video (12) and two image galleries (13); the additional video provides standard controls and can be displayed in full-screen mode (14))
A click on one of the annotations opens its contents in full screen mode for additional interactions (like browsing an image gallery or watching a video), while the player pauses the main video in the background. If a fork is reached in the scene graph, a button panel is provided at the left side of the main video area where the viewer has to select the next scene. The player also provides multiple language support if the author provides translations for all text and media elements (note: this functionality is not yet implemented in the SIVA Producer, the translations have to be made manually in the JSON file). Besides clicking or tapping the buttons, the basic functions of the player can also be controlled using the keyboard, namely with space bar, ESC button, and left and right arrow button.
All actions of the user can be recorded if logging is enabled by the author. The player transmits the actions to the server every 60 seconds as well as when the player starts or the video ends, if it is used in online mode. If the player is used in offline mode, logging data is collected and transmitted to the server when a connection can be established.
Configurations in HTML are possible. Using a responsive design, the player cannot only be used on desktop PCs having varying screen sizes but also on mobile devices in landscape and portrait mode. The player can be used online over the internet or in offline mode when all files are stored at the end user device.
SIVA Server
Main server application:
| Reqirements (recommended): | Apache Tomcat 7, PostgreSQL 9.1 or newer, credentials to an SMTP account |
| Installation: | deploy WAR file into the Tomcat’s webapp folder, open URL in browser, finish installation by filling all fields |
| License: | GPLv3 |
Player Stats:
| Reqirements (recommended): | Apache 2 webserver, PHP in version 5.4, enabled Apache module mod_rewrite |
| Installation: | put back-end files into virtual host’s folder, open in browser, complete the installation |
| License: | GPLv3 |
Installation files for the server application and the player stats can be found at https://github.com/SIVAteam/SIVA-Suite/tree/master/server. Additionally, a WAR file for the main server application can be found at https://github.com/SIVAteam/SIVA-Suite/releases.
The SIVA Server provides a platform for hypervideos and evaluations based on logging data. Furthermore, it provides user and rights management for copyright protected videos.
Videos exported by the producer are uploaded in the Web interface, extracted by the server, and can then be viewed on the server. It is furthermore possible to provide a link to a video, for example when the video is also available as a Chrome App, or a download for a zip file. The latter can be extracted locally on the end user device and watched without internet connection.
Users may have different roles (like user, administrator, etc.) and rights according to their roles. Furthermore, each user may be member of one or more groups. The accessibility of videos can be assigned at group level. This ensures that the visibility of videos is satisfied according to the demands of the author or copyright limitations. A help for the SIVA Server can be found on its start page.

Figure 6. SIVA Server – player stats with usage view.
The server furthermore provides the SIVA Player Stats, the back end for the logging functionality of the player. This part of the application facilitates analyzing and evaluating the logged usage data. Watching, searching, exporting, or visualizing these data can be done video based. One of the currently available diagram views is the Sunburst diagram (see Figure 6), which shows how often certain paths were taken in a video by the viewers. Another diagram is a Treemap which shows the different scenes of the video and the events in these scenes. Thereby, the sizes of the boxes are representing the frequency of occurrence of one single event. This part of the application is only accessible for administrators registered in the front-end.
Implementation
For information about implementation details please refer to the documentation on GitHub https://github.com/SIVAteam/SIVA-Suite or [8].
Conclusion and Future Work
In this column we present the SIVA Suite, an open source framework for the creation, playback, and administration of hypervideos. The authoring tool, the SIVA Producer, provides several editors like a scene graph or annotation editors, as well as an export function. The hypervideo player, the SIVA Player, has extended controls and display areas as well as an intuitive design. The Web server, the SIVA Server, provides functions for user, group, and video management. This framework, especially the authoring tool and the player, were successfully used for the creation and playback of several hypervideos, most noteworthy a medical hypervideo training (see [1] and [2]). Both were evaluated in several usability tests and improved step-by-step since 2008.
While the framework already provides all necessary functions for the creation, playback, and management of hypervideos, several additional functions might be desirable. For now, video conversion is done in the producer during the export of a hypervideo. Especially when several video versions (regarding resolution, quality, or video format) are needed, this task can block the production site for a long period. To improve productivity, video conversion could be moved to the server component. Furthermore, a player preview in the producer is preferable, which avoids the necessity to export the hypervideo to watch it. While currently a created hypervideo can only be translated by manually copying its structure to a new project, input forms for multilingualism in the producer would make this task easier. Pushing the interaction part to a new level, viewers could benefit from a collaborative editing function in the player, allowing them to add comments or additional materials to a video. Additionally, splitting the contents of the player into a second screen could allow for easier interaction and perception of hypervideos, especially in sports or medical training scenarios. The implementation of a download and cache management as described in [9] and [10] in the player may help to reduce waiting time at scene changes.
References
[1] Katrin Tonndorf, Christian Handschigl, Julian Windscheid, Harald Kosch & Michael Granitzer. The effect of non-linear structures on the usage of hypervideo for physical training. In: 2015 IEEE International Conference on Multimedia and Expo (ICME), pp.1-6, 2015.
[2] Britta Meixner, Katrin Tonndorf, Stefan John, Christian Handschigl, Kai Hofmann, Michael Granitzer, Michael Langbauer & Harald Kosch. A Multimedia Help System for a Medical Scenario in a Rehabilitation Clinic. In: Proceedings of I-Know, 14th International Conference on Knowledge Management and Knowledge Technologies (i-KNOW ’14). ACM, New York, NY, USA, 25:1-25:8, 2014.
[3] Frank Shipman, Andreas Girgensohn & Lynn Wilcox. Authoring, Viewing, and Generating Hypervideo: An Overview of Hyper-Hitchcock. In: ACM Trans. Multimedia Comput. Commun. Appl., ACM, 5, 15:1-15:19, 2008.
[4] Honkytonk Films Klynt, http://www.klynt.net/, Website (accessed May 18, 2015), 2015.
[5] Britta Meixner, Katarzyna Matusik, Christoph Grill & Harald Kosch. Towards an easy to use authoring tool for interactive non-linear video. In: Multimedia Tools and Applications, Volume 70, Number 2, Springer Netherlands, pp. 1251-1276, ISSN 1380-7501, 2014.
[6] Britta Meixner & Harald Kosch. Interactive non-linear video: definition and XML structure. In: Proceedings of the 2012 ACM symposium on Document engineering (DocEng ’12). ACM, New York, NY, USA, 49-58, 2012.
[7] Britta Meixner, Beate Siegel, Peter Schultes, Franz Lehner & Harald Kosch. An HTML5 Player for Interactive Non-linear Video Time-based Collaborative Annotations. In: Proceedings of the 10th International Conference on Advances in Mobile Computing & Multimedia, MoMM ’13, ACM, New York, NY, USA, pp. 490-499, 2013.
[8] Britta Meixner, Stefan John & Christian Handschigl. SIVA Suite: Framework for Hypervideo Creation, Playback and Management. In: Proceedings of the 23rd Annual ACM Conference on Multimedia Conference (MM ’15). ACM, New York, NY, USA, 713-716, 2015.
[9] Britta Meixner & Jürgen Hoffmann. Intelligent Download and Cache Management for Interactive Non-Linear Video. In: Multimedia Tools and Applications, Volume 70, Number 2, SpringerNetherlands, pp. 905-948, ISSN 1380-7501, 2014.
[10] Britta Meixner Annotated Interactive Non-linear Video – Software Suite, Download and Cache Management Doctoral Thesis, University of Passau, 2014.


















