


Authors: Hayley Hung and Ekin Gedik
Affiliations: Socially Perceptive Computing Lab, Delft University of Technology
Introduction
We often find other collaborators by chance at a conference or by looking for them specifically through their papers. However, sometimes hidden potential social connections might exist between different researchers that cannot be immediately observed because the keywords we use might not always represent the entire space of similar research interests. As a community, Multimedia (MM) is so diverse that it is easy for community members to miss out on very useful expertise and potentially fruitful collaborations. There is a lot of latent knowledge and potential synergies that could exist if we were to offer conference attendees an alternative perspective on their similarities to other attendees. ConfFlow is an online application that offers an alternative perspective on finding new research connections. It is designed to help researchers find others at conferences with complementary research interests for collaboration. With ConfFlow we take a data-driven approach by using something similar to the Toronto Paper Matching System (TPMS), used to identify suitable reviewers for papers, to construct a similarity embedding space for researchers to find other researchers.
In this report, we discuss the follow up to the 2020 ConfFlow edition which was run at MMSys, MM, ICMR in 2021. We created separate editions of ConfFlow for each conference, processing 2642 (MM), 272 (MMSys), and 494 (ICMR) accepted authors from each conference.
Both the 2020 and 2021 editions of ConfFlow were funded by the SIGMM special initiatives fund.
New Functionality
In the 2020 edition of ConfFlow, we created an interface allowing authors at the MM 2020 conference to browse the research similarity space with others. Each user needs to claim their Google scholar account in the application before using it. We implemented a strict privacy-sensitive policy allowing data of individuals only to be shown if they consented to use the database; even public data was not shown as the processed public data might be considered a privacy invasion. Unfortunately, because of this strict policy, and very little uptake of the application, the full experience of the application was not possible for any user. In the 2021 edition, we updated the privacy policy to be more permissive, whilst still secure (see discussion in the Privacy and Ethical Considerations section below).
From our experiences from the 2020 edition, we identified some bottlenecks that could be improved upon. To that end, we made the following augmentations:
- Improved frontend design: We did an overhaul of the interface to make it more modern, visually appealing, and user-friendly. The design was also slightly changed to accommodate new functionalities
- New embedding options: We added two more options to choose how the similarity space is formed; word2vec (tf-idf weighted mean word2vec embeddings: w(eighted)-m(ean)o(f)w(ord)e(mbeddings)) and doc2vec (see Figure 1)
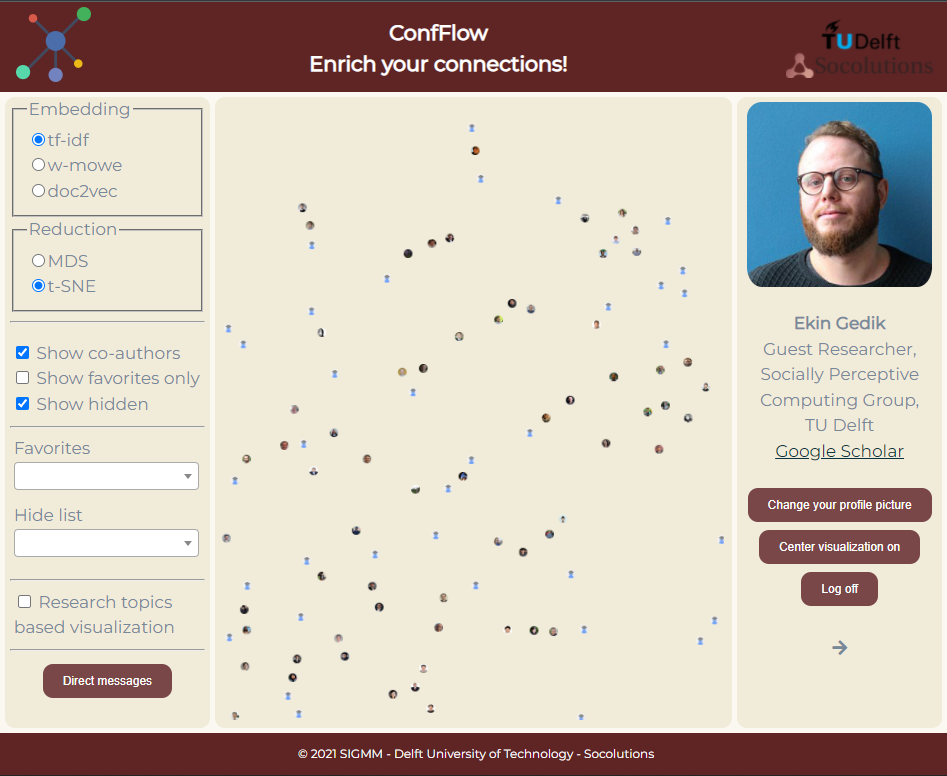
- Interactive tutorial for onboarding: We included an interactive tutorial that showcases the full range of functionalities to the users when they first log in (see Figure 2)
- Direct messaging functionality: We added direct messaging to ConfFlow, allowing direct communication between attendees (see Figure 3)
- Scaling ConfFlow and making it cheaper to run in the future: There is an economy of scale to only needing to update the ConfFlow database with conference newcomers. We made the following steps to make the process more efficient:
- Generating a database of verified authors from the lists of SIGMM conference attendees listed on the ACM website in the last 6 years.
- A helper tool for finding google scholar profiles of newcomers quicker as they needed to be manually verified for security reasons.

Figure 2. Screenshot example of the walkthrough/tutorial 
Figure 3. Screenshot of the direct messaging functionality
Deployment
Method
ConfFlow was rolled out to 3 conferences starting with MMSys 2021 (Istanbul, Turkey) in September, Multimedia 2021 (Chengdu, China) in October, and ICMR (Taipei, Taiwan) 2021 in November rather than just ACM MM in 2020. All MMSys and MM conferences were organized as hybrid events whilst ICMR was finally organized virtually after having to be rescheduled twice.
We asked all general and program chairs of each respective conference to provide the author lists of the accepted papers in the conference at least 1 month before the conference started. This was in the end a compromise between obtaining just the actual conference attendees (which would have made social connection easier if the conferences had been in-person only) and being able to get conference relevant participants sufficiently ahead of time in order to disambiguate identities and start the time-consuming computations of the embedding spaces. Given the added complication that MMSys and Multimedia were hybrid, the problem of waiting for the final conference registration list was that we would need to wait until very close to the conference itself to get the latest attendee list. In any case, even if we knew, the hybrid nature of the conference made virtual social connection still the more viable option. Use of the attendee list would also make it harder to pre-announce the application just before the conference started. Given also that the conference organizers were very occupied with handling the many uncertainties of conference organization during the pandemic, we decided that obtaining the author lists was the least risky approach.
Aside from getting the author lists, we also asked the conference organizers for support in disseminating the application to the conference attendees. A separate edition of ConfFlow needed to be generated for each conference. The following strategies were used for disseminating the application via the conference directly and from a personal account:
- MMSys: slack channel, Twitter (conference, personal, and sigmm), weixin, weibo, facebook, presentation slides during conference general announcements
- ACM MM: Twitter (conference and sigmm), whova, presentation slide during the conference banquet
- ICMR: Twitter (conference, personal, and sigmm).
We tried a different strategy compared to last year to catch people’s attention to the application by a more comprehensive dissemination strategy and also short catchy explanatory videos to communicate the functionalities of the application. These were embedded in our social media dissemination campaigns.
Following on from that, we issued an online survey to gauge how people in the community at large felt about social interaction and, if they had used ConfFlow, how was their experience of the app. This was sent shortly after the conference by email to all those that used the application and then also 1 week later as a reminder. Posts were also sent out on Twitter and Facebook to encourage people in the community to fill in the survey even if they had not used ConfFlow. The survey was divided into questions related to collaboration in general, their experience using ConfFlow, and questions about how the application experience could be changed. Further details about the questions are shown in the Appendix.
Privacy and Ethical Considerations
The first edition of ConfFlow (2020) had a very restrictive opt-in only policy. This made the visualization hard to use for interested users, thus severely hindering the user experience. Users unanimously asked for visualization of the other researchers in the community. Therefore, any already publicly available information from a user’s google scholar account or ACM website and derived visualizations were displayed to everyone. Information that is not available publicly online such as their individual usage behavior, their visualization options, whether their ConfFlow account is activated or not etc is not shown publicly.
Application Realization
For security reasons, each user cannot use ConfLab until they have claimed their account. This is needed because each account has preferences related to the ConfFlow interface – settings such as hiding particular researchers, having researchers marked as ‘favourites’ as well as the direct messaging functionality. We used very strict security procedures for the building of ConfFlow and this also meant that to retrieve a user’s preferences in the application, a user’s identity needed to be verified when a user claims their account. We do this by associating the author’s name and affiliation with a Google scholar profile and then a user needs to verify their identity with respect to their Google scholar account. In some cases, it is necessary to manually assign an author to a Google scholar profile because there are too many profiles with the same name; sometimes many author names can be associated with the same Google scholar account. To this end, one of the main new functionalities was the creation of a database of all SIGMM community members who had published at the MM conference recently. That way, their name and google scholar profile only needs to be associated once and can easily be re-used in future editions of ConfLab. This manual effort aspect of the process varied across the three different conferences in which ConfLab was created. We elaborate on this below. An additional helper function was created to allow faster manual verification in cases of ambiguity.
ConfFlow at ACM SIGMM
We describe some statistics for each edition of ConfFlow at the three conferences of SIGMM in 2021: MMSys, MM, and ICMR. We list them in chronological order of when the conference occurred in the calendar year.
ACM MMSys
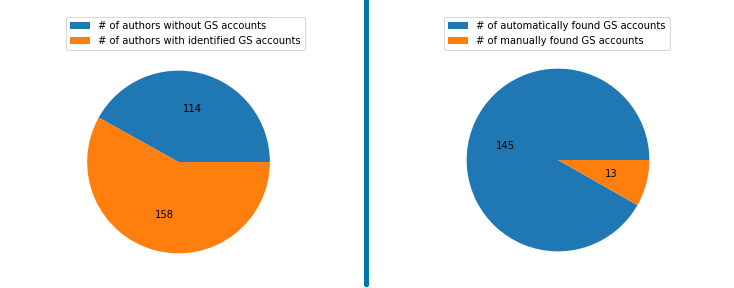
The author list provided by General Chairs of MMSys had 272 unique authors. As shown in Figure 4., we were able to identify Google Scholar accounts of 158 authors. 145 of these accounts were identified automatically using the provided author information: name, affiliation, and e-mail domain. 13 accounts identified by the automatic process were tagged as ambiguous and required manual validation.
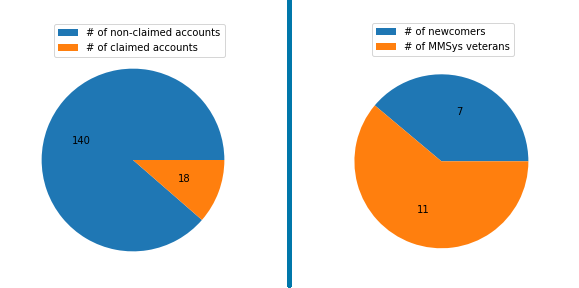
We created ConfFlow accounts for 145 identified authors. As shown in Figure 5, 18 users claimed their accounts and used ConfFlow during the conference. Further analysis showed that 7 out of 18 users were newcomers to MMSys i.e., it was their first publication at this conference.
After sending out the survey request to the 18 users after the conference, we obtained 1 survey response from a PhD student. Due to the low response rate, we do not report the responses.
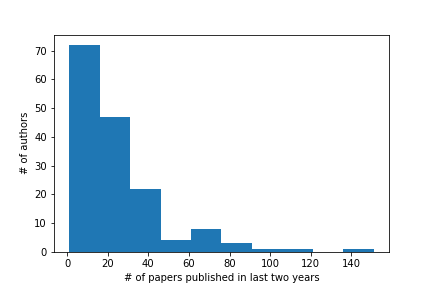
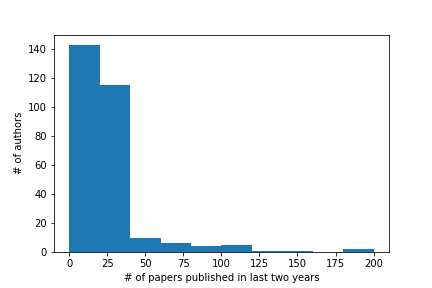
The similarity space visualized in ConfFlow is based on the publications of authors in the last two years. Figure 6 shows the distribution of the number of papers MMSys authors published in the last two years. We show this because for each identified author, we take all the papers they published in the last 2 years to generate the latent representation of their research interests. What was particularly interesting to see is how many researchers were publishing 30 or more papers in the last 2 years. They account for a significant proportion of the authors of the conference who may be too busy to find new research connections. However, there is also a significant proportion of researchers publishing less than 30 papers a year who could find Conf Lab useful.
ACM Multimedia
We realized that users without a Google scholar profile could not use ConfLab at all so for the Multimedia edition, we added a view-only (guest account) option of ConfLab and advertised it on social media accordingly. This view-only account also allowed researchers who did not want to claim their account to browse the embedding space. The disadvantage of this approach is that the application does not immediately centre on the user in the embedding space. Given the large number of authors at Multimedia, this made it extremely hard for view-only users to find themselves, which may have made it harder for them to appreciate the utility of the application.
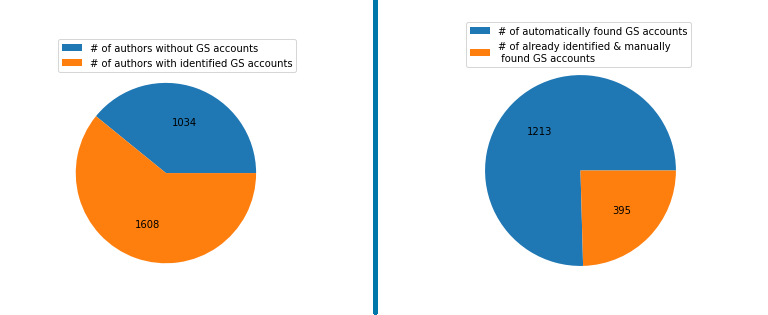
As shown in Figure 7, the author list provided by General Chairs of Multimedia had 2642 unique authors. We were able to identify Google Scholar accounts of 1608 authors. 1213 of these accounts were identified automatically using the provided author information: name, affiliation, and e-mail domain. 225 authors were already identified in the previous iterations of ConfFlow for ACM MMSys ‘21 and MM ‘20. We then manually analyzed the remaining 1204 authors that were either tagged as ambiguous matches by the automatic process or returned no matches at all. We were able to identify an additional 170 accounts with the manual search. This highlights how challenging it is to establish an online identity for all authors in order for them to use ConfFlow, despite manual intervention.
We created ConfFlow accounts for the identified authors. As shown in Figure 8, 16 users claimed their accounts and used ConfFlow during the conference. Further analysis showed that 9 out of 16 users were newcomers to MMSys i.e., it was their first publication at this conference. 5 attendees requested access to the guest account.
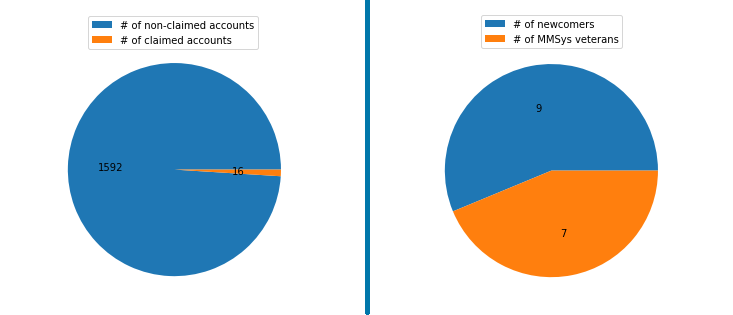
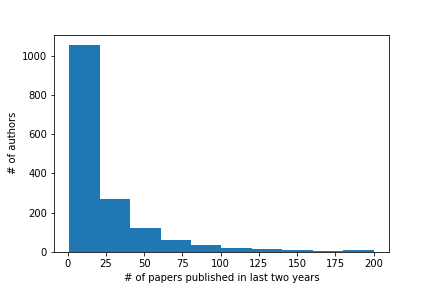
Figure 9 shows the distribution of the number of papers. Multimedia 2021 authors published in the last two years. It is interesting to see a more skewed distribution towards people with fewer publications compared to the MMSys edition. This would suggest that there are potentially more researchers who would find ConfFlow interesting as a social connection tool. However, both MMSys and Multimedia had very similar numbers of users despite Multimedia being almost 10 times bigger. This may be related to the fact that we were able to be in closer communication with the general chairs of MMSys who gave us access to more channels of communication (including a slide announcement during the conference opening). Meanwhile, at MM, the initial dissemination via Whova (which was the first line of attack) did not yield any new users at all and the Multimedia social media feed (Twitter) had very few followers – this could be explained by the fact that Twitter is not used by many of our colleagues in Asia and Multimedia was being run in Chengdu. We do not have statistics on the proportion of hybrid vs. in-person attendees which may also have affected usage.
ICMR
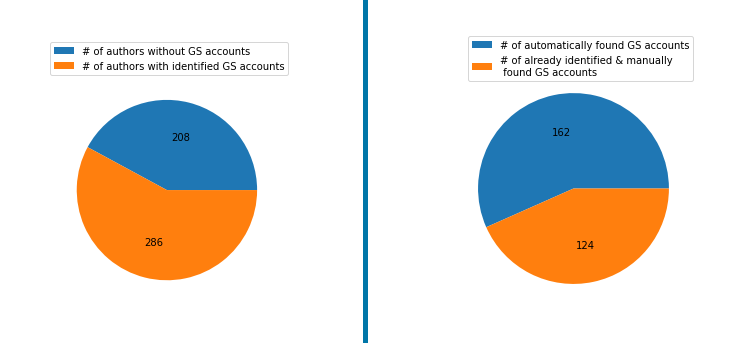
The author list provided by the General Chairs of Multimedia had 494 unique authors. As shown in Figure 10, we were able to identify Google Scholar accounts of 286 authors. 162 of these accounts were identified automatically using the provided author information: name, affiliation, and e-mail domain. 67 authors were already identified in the previous iterations of ConfFlow. We then manually analyzed the remaining 265 authors that were either tagged as ambiguous matches by the automatic process or returned no matches at all. We were able to identify an additional 57 accounts with the manual search.
None of the users claimed their ConfFlow account during ICMR’21. Figure 11 shows the distribution of the number of papers MMSys authors published in the last two years. It is interesting that despite being almost double the size of MMSys and 5 times smaller than Multimedia,
Discussion and Recommendations
This section describes some key points of reflection on the running of ConfFlow this year.
One of the main issues relates to the low number of users despite conference participants being aware of the application. The survey on collaboration and experience with ConfFlow did not yield sufficient responses.
It is interesting to see in all conferences that a significant proportion of the users of ConfFlow were newcomers. Unfortunately, without the statistics from the survey we put out, it is not clear if this reflects the distribution of the conference attendees in general or whether more newcomers are interested in using ConfFlow due to its promise of helping people to connect socially.
The reasons for this could be multiple: The hybrid format and virtual formats of the conferences made it difficult to provide time to think about collaborations whilst being in the middle of preparing to go to a conference or during the conference itself. For virtual participants, in particular, the benefit of not going physically means that one can continue with day to day duties in the person’s normal job. However, this does take away opportunities for social networking that one might have in the in-person setting. In addition, the challenges of running the conference in the hybrid format may also have led to fatigue for in-person as well as virtual participants. Another possible explanation is that in the general Multimedia community there is no obvious intrinsic value in changing the way collaboration is already carried out. The additional barrier of needing to claim their account due to privacy and ethical reasons may have been confusing (it could appear that an account needs to be created, which can be a barrier to usage).
We reflect that the fact that more users were obtained for MMSys could have been related to the closer access we had to social media channels e.g. the conference slack channel, which helped to keep a centralized reminder for participants of what was going on in the conference. It could also be a reflection of the openness of the community to finding social connections. On the other hand, the Whova app used for MM is a more complex interface with multiple purposes beyond just communication, which may have made it harder for attendees to see the ConfLab announcement, embedded in other announcements.
Finally, we also considered that the ConfFlow interface takes time to browse and reflect on. Given that the intrinsic value of the application is not immediately obvious to many (this is our interpretation of the low interest in application use). It could make more sense to have a SIGMM community-wide edition of ConfFlow that is available all year round, allowing for the dissemination of the application and its purpose to be made clear outside of the pre-conference rush. Then conference-specific editions could be generated. This, however, comes with its own logistic issues as every new identity added to the database would either require the entire embedding to be recomputed, or their latent research interest representation would need to be projected directly onto the existing embedding, which does not necessarily accurately represent their closeness to others in the existing database. The rate at which updates (new authors) are added would also require significant manual attention (and may not be easy to resolve as shown in the statistics in Table 1). Given also the popularity of the Influence Flowers (http://influencemap.ml/), a previously funded SIGMM initiative, we suspect that a more ego-based strategy may be more effective in encouraging researchers in the community to start engaging with the ConfFlow application.
| ConfLab Factors\ Conference: | MMSys | Multimedia | ICMR |
| #authors | 272 | 2642 | 494 |
| #previously identified authors | 0 | 225 | 286 |
| #authors with automatically identifiable Google scholar | 158 | 1213 | 67 |
| #authors without Google Scholar Match | 13 | 1204 | 265 |
| #authors with manually identified Google Scholar. | 13 | 170 | 57 |
| #users | 18 | 16 | 0 |
| #survey respondents | 1 | 0 | 0 |
Table 1. Summary statistics for each of the three conferences.
Conclusions
The ConfFlow 2021 edition generated new functionalities to allow researchers to browse their research interests with respect to others in a fun and novel way. More effort was given this year to improve the advertising of the application and to try and understand the community’s struggles with collaboration. Steps were also taken to make the running of ConfFlow less labour-intensive.
Our conclusions from the many efforts made in ConfFlow 2021, the surrounding social media presence, and the survey is that for the SIGMM population at large, encouraging more social connections outside of the normal routes is unfortunately not perceived to have significant value. It seems that for now, more immediate forms of social interaction encouragement e.g. initiatives during the conference to help newcomers to integrate may be a more effective route to enable social integration. Another option is to consider a hybrid approach where ConfFlow can be used to e.g. identify groups for going to dinner together during the conference or sitting at the same table during the conference banquet. However, this would still require a sufficient uptake of the application. Given the myriad of different motivations community members have to attend conferences, it remains an intriguing and open challenge to encourage more diverse research output from this highly interdisciplinary community.
Acknowledgements:
ConfFlow 2021 was supported in part by the SIGMM Special Initiatives Fund and the Dutch NWO-funded MINGLE project number 639.022.606. We thank users who gave feedback on the application during prototyping and implementation and the General Chairs of ACM MMSys, Multimedia, and ICMR 2021 for their support.
References:
Ekin Gedik and Hayley Hung. 2020. ConfFlow: A Tool to Encourage New Diverse Collaborations. Proceedings of the 28th ACM International Conference on Multimedia. Association for Computing Machinery, New York, NY, USA, 4562–4564. DOI:https://doi.org/10.1145/3394171.3414459
Appendix:
List of Survey Questions used for our google form:
https://docs.google.com/forms/d/e/1FAIpQLSdcj1B-fOFmEG8mFvcUbd91ysYkEapm_zVvNcJMaFS5ETgFkQ/viewform
- Context Questions
- I am attending these conferences in 2021
- I am publishing in these conferences in 2021
- Please indicate the job description that best describes you.
- General Questions about Scientific Collaboration
- I tend to initiate collaborations with people I already know well.
- I tend to initiate collaborations with people at the same experience level as me.
- I am very interested in finding collaborators from a different discipline.
- I find it very hard to identify relevant collaborators from a different discipline.
- I find it very hard to initiate interdisciplinary collaborations even when I know who I want to work with.
- What are the common problems you face when trying to initiate a collaboration?
- Do these problems influence how or whether you initiate collaborations?
- Initial contact with ConfFlow:
- I saw announcements encouraging me to try ConfFlow
- Did you have problems in getting in to ConfFlow? e.g. the system could not find your Google Scholar account?
- On how many separate occasions have you used ConfFlow?
- Motivation for using ConfFlow
- I did not use ConfFlow because I did not have time.
- I did not use ConfFlow because I did not find it interesting.
- I would be interested in trying ConfFlow in the weeks leading up to or following a conference.
- Despite not using ConfFlow, I could see how it might help advance my research work.
- We would be very grateful for any comments or feedback on your experience of ConfFlow so we can make it more useful. Please feel free to share any remarks you might have on this topic.
- Experience using ConfFlow
- The visualization matched who I would expect to be close to me.
- The visualization matched who I would expect to be far away from me.
- ConfFlow helped me to find interesting people that I did not know before.
- ConfFlow helped me to connect with interesting people that I did not know before.
- ConfFlow encouraged me to think more deliberately about making connections with researchers in a different discipline.
- I think that ConfFlow could help to advance my research work.