

Prof. Ramesh Jain in 2016.
Please describe your journey into computing from your youth up to the present. What foundational lessons did you learn from this journey? Why you were initially attracted to multimedia?
I am luckier than most people in that I have been able to experience really diverse situations in my life. Computing was just being introduced at Indian Universities when I was a student, so I never had a chance to learn computing in a classroom setting. I took a few electronics courses as part of my undergraduate education, but nothing even close to computing. I first used computers during my doctoral studies at the Indian Institute of Technology, Kharagpur, in 1970. I was instantly fascinated and decided to use this emerging technology in the design of sophisticated control systems. The information I picked up along the way was driven by my interests and passion.
I grew up in a traditional Indian Ashram, with no facilities for childhood education, so this was not the first time I faced a lack of formal instruction. My father taught me basic reading, writing, and math skills and then I took a school placement exam. I started school at the age of nine in fifth grade.
During my doctoral days, two areas fascinated me: computing and cybernetics. I decided to do my research in digital control systems because it gave me a chance to combine computing and control. At the time, the use of computing was very basic—digitizing control signals and understanding the effect of digitalization. After my PhD, I became interested in artificial intelligence and entered AI through pattern recognition.
In my current research, I am applying cybernetics to health. Computing has finally matured enough that it can be applied in real control systems that play a critical role in our lives. And what is more important to our well-being than our health?
The main driver of my career has been realizing that ultimately I am responsible for my own learning. Teachers are important, but ultimately I learn what I find interesting. The most important attribute in learning is a person’s curiosity and desire to solve problems.
Something else significantly impacted my thinking in my early research days. I found that it is fundamental to accept ignorance about a problem and then examine concepts and techniques from multiple perspectives. One person’s or one research paper’s perspective is just that—an opinion. By examining multiple perspectives and relating those to your experiences, you can better understand a problem and its solutions.
Another important lesson is that problems or concepts are often independent of the academic and other organisational walls that exist. Interesting problems always require perspectives, concepts, and technologies from different academic disciplines. Over time, it’s then necessary to create to new disciplines, or as Thomas Kuhn called them new paradigms [Kuhn 62].
In the late 1980s, much of my research was addressing different aspects of computer vision. I was frustrated by the slow progress in computer vision. In fact, I coauthored a paper on this topic that became quite controversial [Jain 91]. It was clear that computer vision could be central to computing in the real world, such as in industry, medical imaging, and robotics, but it was unable to solve any real problems. Progress was slow.
While working on object recognition, it became increasingly obvious to me that images alone do not contain enough information to solve the vision problem. Projection of real-world images to a photograph results in a loss of information that can only be recovered by combining information from many other sources, including knowledge in many different forms, metadata, and other signals. I started thinking that our goal should be to understand the real world using sensors and other sources of knowledge, not just images. I felt that we were addressing the wrong problem—understanding the physical world using only images. The real problem is to understand the physical world. The physical world can only be understood by capturing correlated information. To me, this is multimedia: understand the physical world using multiple disparate sensors and other sources of information.
This is a very good definition of multimedia. In this context, what do you think is the future of multimedia research in general?
Different aspects of physical world must be captured using different types of sensors. In early days, multimedia concerned itself with the two most dominant human senses:vision and hearing. As the field is advancing, we must deal with every type of sensor that is developed to capture information in different applications. Multimedia must become the area that processes disparate data in context to convert it to information.
Taking into account that you are working with AI for such a long time, what do you think about the current trend of deep learning and how it will develop?
Every field has its trends. Learning is definitely a very important step in AI and has attracted attention from early days. However, it was known that reasoning and search play equally important role in AI. Ultimately problem solving depends on recognizing real world objects and patterns and here learning plays key role. To design successful deep systems, learning needs to be combined with search and reasoning.

Prof. Ramesh Jain at an early stage of his career (1975).
Please tell us more about your vision and objectives behind your current roles. What do you hope to accomplish, and how will you bring this about?
One thing that is of great interest to every human is their health. Ironically, technology utilization in healthcare is not as pervasive as in many other fields. Another intriguing fact about technology and health is that almost all progress in health is due to advances in technology, but barriers to using technology are also the most overwhelming in health. I experienced the terrifying state of healthcare first hand while going through treatment for gastro-esophageal cancer in 2004. It became clear to me during my fight with cancer that technology could revolutionize most aspects of treatment—from diagnosis to guidance and operationalization of patient care and engagement—but it was not being used. During that period, it became clear to me that multimodal data leading to information and knowledge is the key to success in this and many other fields. That experience changed my thinking and research.
Ancient civilizations observed that health is not the absence of disease; disease is a perturbation of a healthy state. This wisdom was based on empirical observations and resulted in guidelines for healthy living that includes diet, sleep, and whole-body exercise, such as yoga or tai chi. Now is the time to develop scientific guidelines based on the latest evolving knowledge and technology to maximize periods of overall health and minimize suffering during diseases in human lives. It seems possible to raise life expectancy to 100+ years for most people. I want to cross the 100-year threshold myself and live an active life until my last day. I am working toward making that happen.
Technology for healthcare is increasingly a popular topic. Data is at the center of healthcare, and new areas like precision health and wellness are becoming increasingly popular. At the University of California, Irvine (UCI), we’ve created a major effort to bring together researchers from Information and Computer Sciences, Health Sciences, Engineering, Public Health, Nursing, Biology, and others fields who are adopting a novel perspective in an effort to build technology that empowers people. From this perspective, we adopt a cybernetics approach to health. This work is being done at the UCI’s Institute for Future Health, of which I am the founding director.
At the Institute for Future Health, currently we are building a community that will do academic research as well as work closely with industry, local communities, hospitals, and start-up companies. We will also collaborate with global researchers and practitioners interested in this approach. There is significant interest from several institutions in several countries to collaborate and pursue this approach.
This is very interesting and relevant! Do you think that the multimedia community will be open for such a direction or since it is so important and societal relevant would it be good to built a new research community around this idea?
As you said, this is the most important research direction I have been involved in and most challenging. And this is an important direction in itself — this needs to happen using all tech and other resources.
Since I can not wait for any community to be ready to address this, I started building a community to address Future Health. But, I believe that this could be the most relevant application for multimedia technology as well as the techniques from multimedia are very relevant to this area.
Exciting problem because the time is right to address this area.
Do you think that the multimedia community has the right skills to address medical multimedia problems and how could the community be encouraged into that direction?
Multimedia community is better equipped than any other community to deal with diverse types of data. New tools will be required for new challenges, but we already have enough tools and techniques to address many current challenges. To do this, however, the community has to become an open forward looking community going beyond visual information to consider all other modes that are currently ignored under ‘meta data’. All data is data and contributes to information.
Can you profile your current research and its challenges, opportunities, and implications?
I am involved in a research area that is one of the most challenging and that has implications for every human.
The most exciting aspect of health is that it is truly a multimodal data-intensive operation. As discussed by Norbert Wiener in his book Cybernetics [Wiener 48] about 75 years ago, control and communication processes in machines and animals are similar and are based on information. Until recently, these principles formed the basis for understanding health, but they can now be used to control health as well. This is exciting for everybody, and it motivates me to work hard and make something happen. For others, but also for me.
We can discuss some fundamental components of this area from a cybernetics/information perspective:
Creating individual health model: Each person is unique. Our bodies and lives are determined by two major factors: genetics and lifestyle. Until recently, personal genome information was difficult to obtain, and personal lifestyle information was only anecdotally collected. This century is different. Personal genomic, in fact all Omics, data is becoming easier to get and more precise and informative. And mobile phones, wearables, the Internet of Things (IoTs) around us, and social media are all coming together to quantitatively determine different aspects of our lifestyles as well as many bio-markers.
This requires combining multimodal data from different sources, which is a challenge. By collecting all such lifestyle data, we can start assembling a log of information—a kind of multimodal lifelog on turbo charge—that could be used to build a model of a person using event mining tools. By combining genomic and lifestyle data, we can form a complete model of a person that contains all detailed health-related information.
Aggregating individual health models to population disease models: Current disease models rely on limited data from real people. Until recently, it was not possible to gather all such data. As discussed earlier, the situation is rapidly changing. Once data is available for individual health models, it could be sliced and diced to formulate disease models for different populations and demographics. This will be revolutionary.
Correlating health and related knowledge to actions for each individual and for society: Cybernetics underlies most complex engineering real-time systems. The concept of feedback used generate a correct signal to be applied to a system to take it from the current state to a desired state is essential in all real-time control systems. Even for the human body, homeostasis uses similar principles. Can we use this to guide people in their lifestyle choices and medical compliance?
Navigation systems are a good example of how an old, tedious problem can become extremely easy to use. Only 15 years ago, we needed maps and a lot of planning to visit new places. Now, mobile navigation systems can anticipate upcoming actions and even help you correct your mistakes gracefully, in real time. They can also identify traffic conditions and suggest the best routes.
If technology can do this for navigation in the physical world, can we develop technology to help us select appropriate lifestyle decisions and do so perpetually? The answer is obviously yes. By compiling all health and related knowledge, determining your current personal health situation and surrounding environmental situations, and using your past chronicle to log your preferences, it can provide you with suggestions that will make your life not only more healthy but also more enjoyable.
This is our dream at the Institute for Future Health.
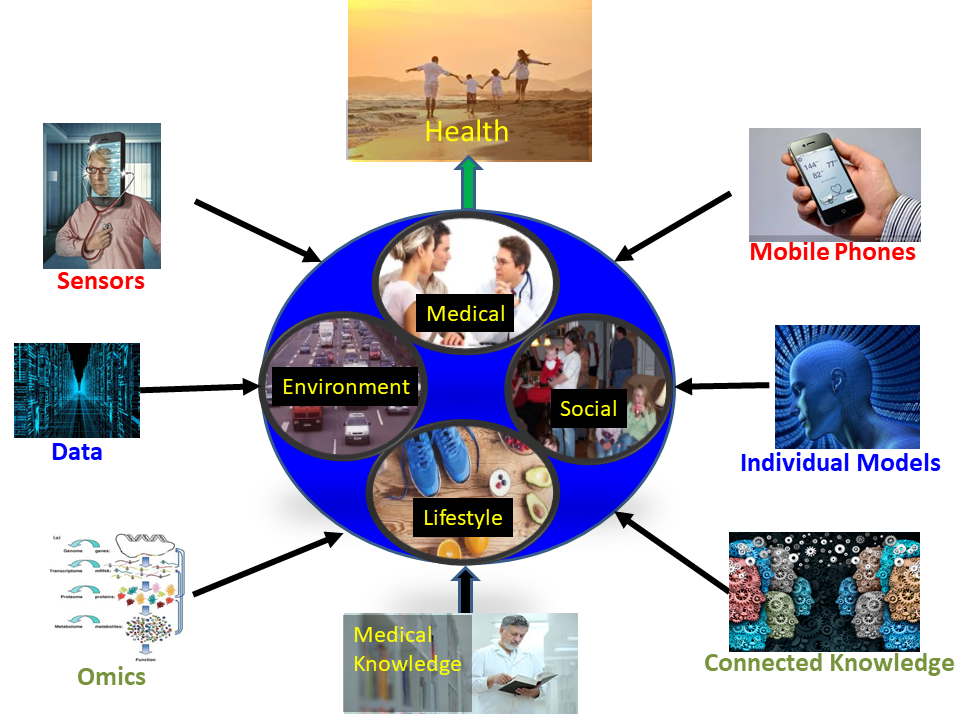
Future Health: Perpetual enhancement of health by managing lifestyle and environment.
4) How would you describe your top innovative achievements in terms of the problems you were trying to solve, your solutions, and the impact it has today and into the future?
I am lucky to have been active for more than four decades and to have had the opportunity to participate in research and entrepreneurial activities in multiple countries at the best organizations. This gave me a chance to interact with the brightest young people as well as seasoned creative visionaries and researchers. Thus, it is difficult for me to decide what to list. I will adopt a chronological approach to answer your question.
Working in H.H. Nagel’s research group in Hamburg Germany, I got involved in developing an approach to motion detection and analysis in 1976. We wrote the first papers on video analysis that worked with traffic video sequences and detected and analyzed the motion of cars, pedestrians, and other objects. Our paper at IJCAI 1977 [Jain 77] was remarkable in showing these results at a time when digitizing a picture was a chore lasting minutes and the most powerful computer could not store a full video frame in its memory. Even today, the first step in many video analysis systems is differencing, as proposed in that work.
Many bright people contributed powerful ideas in computer vision from my groups. E. North Coleman was possibly the first person to propose Photometric Stereo in 1981 [Coleman]. Paul Besl’s work on segmentation using surface characteristics and 3D object recognition made a significant impact [Besl]. Tom Knoll did some exciting research on feature-indexed hypotheses for object recognition. But Tom’s major contribution to current computer technology was his development of Photoshop when he was doing his PhD in my research group. As we all know, Photoshop revolutionized how we view photos. Working with Kurt Skifstad at my first company Imageware, we demonstrated the first version of capturing a 3D shape of a person’s face and reproducing it using a machine in the next room at the Autofact Conference in 1994. I guess that was a primitive version of 3D printing. At the time, we called it 3D fax.
The idea of designing a content-based organization to build a large database of images was considered crazy in 1990, but it bugged me so much that I started first a project and later a company, Virage, working with several people. In fact, Bradley Horowitz left his research at MIT to join me in building Virage and later he managed the project that brought Google Photos to its current form. That process building video databases resulted in my realizing that photos and videos are a lot more than just intensity values. And that realization lead me to champion the idea that information about the physical world can be recovered more effectively and efficiently by combining correlated, but incomplete, information from several sources, including metadata. This was the thinking that encouraged me to start building the multimedia community.
Since computing and camera technology had advanced enough by 1994, my research group at the University of California, San Diego (UCSD), particularly Koji Wakimoto[Jain 95] and then Arun Katkere and Saeed Moezzi [Moezzi 96] helped in developing initially Multiple Perspective Interactive Video and later Immersive video to realize compelling telepresence. That research area in various forms attracted people from the movie industry as well as people interested in different art forms and collaborative spaces. By licensing our patents from UCSD, we started a company Praja to bring immersive video technology to sports. I left academia to be the CEO of Praja.
While developing technology for indexing sporting events, it became obvious that events are as important as objects, if not more, when indexing multimedia data. Information about events comes from separate sources, and events combine different dimensions that play a key role in our understanding of the world. This realization resulted in Westermann and I working on a general computational model for events. Later we realized that by aggregating events over space and time, we could detect situations. Vivek Singh and Mingyan Gao helped prototype an EventShop platform [Singh 2010], which was later converted to an open source platform under the leadership of Siripen Pongpaichet.
One of the most fundamental problems in society is connecting people’s needs to appropriate resources effectively, efficiently, and promptly in a given situation. To understand people’s needs, it is essential to build objective models that could be used to recommend correct resources in given situations. Laleh Jalali started building an event-mining framework that could be used to build an objective self model using the different types of data streams related to people that have now become easily available [Jalali 2015].
All this work is leading to a framework that is behind my current thinking related to health intelligence. In health intelligence, our goal is to perpetually measure a person’s activities, lifestyle, environment, and bio-markers to understand his/her current state as well as continuously build his/her model. Using that model, current state, and medical knowledge, it is possible to provide perpetual guidance to help people take the right action in a given situation.
Over your distinguished career, what are the top lessons you want to share with the audience?
I have been lucky to get a chance to work on several fun projects. More importantly, I have worked closely on an equal number of successful and not so successful projects. I consider a project successful if it accomplishes its goal and the people working on the project enjoy it. Although each project is unique, I’ve noticed that some common themes make for a project successful.
Passion for the Project: Time and again, I’ve seen that passion for the project makes a huge difference. When people are passionate, they don’t consider it work and will literally do whatever is required to make it successful. In my own case, I find that the ideas that I find compelling, both in terms of their goals and implications, are the ones that motivate me to do my best. I am focused, driven, and willing to work hard. I learned long ago to work only on problems that I find important and compelling. Some ideas are just not for me. Otherwise, it is better for the project and for me if I dissociate with it at the first opportunity to do so.
Open Mind: Departmental or similar boundaries in both academia and industry severely restrict how a problem is addressed. Solving a problem should be the goal, not using the resources or technology of a specific department. In academia, I often hear things like “this is not a multimedia problem” or “this is database problem.” Usually, the goal of a project is to solve a problem, so we should use the best technique or resource available to solve the problem.
Most of the boundaries for academic disciplines are artificial, and because they keep changing, the departments based on any specific factor will likely also change over time. By addressing challenging problems using appropriate technology and resources, we push boundaries and either expand older boundaries or create new disciplines.
Another manifestation of an open mind is the ability to see the same problem from multiple perspectives. This is not easy—we all have our biases. The best thing to do is to form a group of researchers from diverse cultural and disciplinary backgrounds. Diversity naturally results in diverse perspectives.
Persistence: Good research is usually the result of sustained efforts to understand and solve a challenge. Many intrinsic and extrinsic issues must be handled during a successful research journey. By definition, an important research challenge requires navigating unchartered territories. Many people get frustrated in an unmapped area and when there is no easy way to evaluate progress. In my experience, even some of my brightest students are comfortable only when they can say I am better than X approach by N%. In most novel problems, there is no X and no metrics to judge performance. Only a few people are comfortable in such situations where incremental progress may not be computable. We require both kinds of people: those who can improve given approaches and those who can pioneer new areas. The second group requires people that can be confident about their research directions without having concrete external evaluation measures. The ability to work confidently without external affirmation is essential in important deep challenges.
In the current culture, a researcher’s persistence is also tested by “publish or perish” oriented colleagues who determine the quality of research by acceptance rates at the so-called top conferences. When your papers are rejected, you are dejected and sometimes feel that you are doing the wrong research. Not always true. The best thing about these conferences is that they test your self-confidence.
We have all read the stories about the research that ultimately resulted in the WWW and the paper on PageRank that later became the foundation of Google search. Both were initially rejected. Yet, the authors were confident in their work so they persevered. When one of my papers gets rejected (which is more often the case than with my much inferior papers), much of the time the reviewers are looking for incremental work—the trendy topics—and don’t have time, openness, and energy to think beyond what they and their friends have been doing. I read and analyze reviewers’ comments to see whether they understood my work and then decide whether to take them seriously or ignore them. In other words, you have to be confident of your own ideas and review the reviews to decide your next steps.
I noticed that one of your favourite quotes is “Imagination is more important than knowledge.” In this regard, do you think there is enough “imagination” in today’s research, or are researchers mainly driven/constrained by grants, metrics, and trends?
The complete quote by Albert Einstein is “Imagination is more important than knowledge. For knowledge is limited, whereas imagination embraces the entire world, stimulating progress, giving birth to evolution.” So knowledge begins with imagination. Imagination is the beginning of a hypothesis. When the hypothesis is validated, that results in knowledge.
People often seek short-term rewards. It is easier to follow trends and established paradigms than to go against them or create new paradigms. This is nothing new; it has always happened. At one time scientists, like Galileo Galilei, were persecuted for opposing the established beliefs. Today, I only have to worry about my papers and grant proposals getting rejected. The most engaged researchers are driven by their passion and the long-term rewards that may (or may not) come with it.

Albert Einstein (Source: Planet Science)
References:
- Kuhn, T. S. The Structure of Scientific Revolutions. Chicago: University of Chicago Press, 1962. ISBN 0-226-45808-3
- R. Jain and T. O. Binford, “Ignorance, Myopia, and Naiveté in Computer Vision Systems,” CVGIP, Image Understanding, 53(1), 112-117. 1991.
- Norbert Wiener, Cybernetics: Or Control and Communication in the Animal and the Machine. Paris, (Hermann & Cie) & Camb. Mass. (MIT Press) ISBN 978-0-262-73009-9; 2nd revised ed. 1961.
- R. Jain, D. Militzer and H. Nagel, “Separating a Stationary Form from Nonstationary Scene Components in a Sequence of Real World TV Frames,” Proceedings of IJCAI 77, Cambridge, Massachusetts, 612-618. 1977.
- E. N. Coleman and R. Jain, “Shape from Shading for Surfaces with Texture and Specularity,” Proceedings of IJCAI. 1981.
- P. Besl, and R. Jain, “Invariant Surface Characteristics for 3-D Object Recognition in Depth Maps,” Computer Vision, Graphics and Image Processing, 33, 33-80. 1986.
- R. Jain and K. Wakimoto, “Multiple Perspective Interactive Video,” Proceedings of IEEE Conference on Multimedia Systems. May 1995.
- S. Moezzi, Arun Katkere, D. Kuramura, and R. Jain, “Reality Modeling and Visualization from Multiple Video Sequences,” IEEE Computer Graphics and Applications, 58-63. November 1996.
- Vivek Singh, Mingyan Gao, and Ramesh Jain,”Social Pixels: Genesis and evaluation”, Proc. ACM Multimedia, 2010.
- Laleh Jalali, Ramesh Jain: Bringing Deep Causality to Multimedia Data Streams. ACM Multimedia 2015: 221-230
Bios
About Prof. Ramesh Jain:
Ramesh Jain is an entrepreneur, researcher, and educator. He is a Donald Bren Professor in Information & Computer Sciences at University of California, Irvine. Earlier he has been at Georgia Tech, University of California, San Diego, University of Michigan, and some other universities in many countries. He was educated at Nagpur University (B.E.) and Indian Institute of Technology, Kharagpur (Ph.D.) in India. His current research is in Social Life Networks including EventShop and Objective Self, and Health Intelligence. He has been an active member of professional community serving in various positions and contributing more than 400 research papers and coauthoring several books including text books in Machine Vision and Multimedia Computing. He is a Fellow of AAAI, AAAS, ACM, IEEE, IAPR, and SPIE.
Ramesh co-founded several companies, managed them in initial stages, and then turned them over to professional management. He also advised major companies in multimedia and search technology. He still enjoys the thrill of start-up environment.
His research and entrepreneurial interests have been in computer vision, AI, multimedia, and social computing. He is the founding director of Institute for Future Health at UCI.
Michael Alexander Riegler:
Michael is a scientific researcher at Simula Research Laboratory. He received his Master’s degree from Klagenfurt University with distinction and finished his PhD at the University of Oslo in two and a half years. His PhD thesis topic was efficient processing of medical multimedia workloads.
His research interests are medical multimedia data analysis and understanding, image processing, image retrieval, parallel processing, gamification and serious games, crowdsourcing, social computing and user intentions. Furthermore, he is involved in several initiatives like the MediaEval Benchmarking initiative for Multimedia Evaluation, which runs this year the Medico task (automatic analysis of colonoscopy videos)footnote{http://www.multimediaeval.org/mediaeval2017/medico/}.
Since 1997 Alan Smeaton has been a Professor of Computing at Dublin City University. He joined DCU (then NIHED) in 1987 having completed his PhD in UCD under the supervision of Prof. Keith van Rijsbergen. He also completed an M.Sc. and B.Sc. at UCD.
In 1994 Alan was chair of the ACM SIGIR Conference which he hosted in Dublin, program co-chair of SIGIR in Toronto in 2003 and general chair of the Conference on Image and Video Retrieval (CIVR) which he hosted in Dublin in 2004. In 2005 he was program co-chair of the International Conference on Multimedia and Expo in Amsterdam, in 2009 he was program co-chair of ACM MultiMedia Modeling conference in Sophia Antipolis, France and in 2010 co-chair of the program for CLEF-2010 in Padova, Italy.
Alan has published over 600 book chapters, journal and refereed conference papers as well as dozens of other presentations, seminars and posters and he has a Google Scholar h-index of 58. He was an Associate Editor of the ACM Transactions on Information Systems for 8 years, and has been a member of the editorial board of four other journals. He is presently a member of the Editorial Board of Information Processing and Management.
Alan has graduated 50 research students since 1991, the vast majority at PhD level. He has acted as examiner for PhD theses in other Universities on more than 30 occasions, and has assisted the European Commission since 1990 in dozens of advisory and consultative roles, both as an evaluator or reviewer of project proposals and as a reviewer of ongoing projects. He has also carried out project proposal reviews for more than 20 different research councils and funding agencies in the last 10 years.
More recently Alan is a Founding Director of the Insight Centre for Data Analytics, Dublin City University (2013-2019), the largest single non-capital research award given by a research funding agency in Ireland. He is Chair of ACM SIGMM (Special Interest Group in Multimedia), (2017-) and a member of the Scientific Committee of COST (European Cooperation in Science and Technology), an EU funding program with a budget of €300m in Horizon 2020.
In 2001 he was joint (and founding) coordinator of TRECVid – the largest worldwide benchmarking evaluation on content-based analysis of multimedia (digital video) which runs annually since then and way back in 1991 he was a member of the founding steering group of TREC, the annual Text Retrieval Evaluation Conference carried out at the US National Institute for Standards and Technology, US, 1991-1996.
Alan was awarded the Royal Irish Academy Gold Medal for Engineering Sciences in 2015. Awarded once every 3 years, the RIA Gold Medals were established in 2005 “to acclaim Ireland’s foremost thinkers in the humanities, social sciences, physical & mathematical sciences, life sciences, engineering sciences and the environment & geosciences”.
He was jointly awarded the Niwa-Takayanagi Prize by the Institute of Image Information and Television Engineers, Japan for outstanding achievements in the field of video information media and in promoting basic research in this field. He is a member of the Irish Research Council (2012-2015, 2015-2018), an appointment by the Irish Government and winner of Tony Kent Strix award (2011) from the UK e-Information Society for “sustained contributions to the field of … indexing and retrieval of image, audio and video data”.
Alan is a member of the ACM, a Fellow of the IEEE and is a Fellow of the Irish Computer Society.
Michael Alexander Riegler:
Michael is a scientific researcher at Simula Research Laboratory. He received his Master’s degree from Klagenfurt University with distinction and finished his PhD at the University of Oslo in two and a half years. His PhD thesis topic was efficient processing of medical multimedia workloads.
His research interests are medical multimedia data analysis and understanding, image processing, image retrieval, parallel processing, crowdsourcing, social computing and user intent. Furthermore, he is involved in several initiatives like the MediaEval Benchmarking initiative for Multimedia Evaluation, which runs this year the Medico task (automatic analysis of colonoscopy videos)footnote{http://www.multimediaeval.org/mediaeval2017/medico/}.























 The Joint Photographic Experts Group (JPEG) is a Working Group of ISO/IEC, the International Organisation for Standardization / International Electrotechnical Commission, (ISO/IEC JTC 1/SC 29/WG 1) and of the Interna
The Joint Photographic Experts Group (JPEG) is a Working Group of ISO/IEC, the International Organisation for Standardization / International Electrotechnical Commission, (ISO/IEC JTC 1/SC 29/WG 1) and of the Interna





{kind=link}