Organizer: Prof. Mohamed Daoudi, Institut Mines-Télécom Nord Europe (IMT Nord Europe), France.
Co-Organizers: Prof. Ahmed Tamtaoui Institut National des Postes et Télécommunications (INPT), Morocco, Prof. Mohamed Khalil (MorroccoAI), Morocco, Jamal Benhamou (Soft Center), Morocco.
In September 2025, it was held the second edition of the Summer School on Multimodal Foundation Models and Generative AI, which, with the support of SIGMM attracted more than 60 students and young researchers to learn, discuss and first-hand experiment in topics related to Generative AI. The event’s success calls for further editions in upcoming years.
The 2nd edition of the Summer School dedicated to Generative AI and Multimodal Foundation Models was held from September 8 to 12, 2025, in Rabat, Morocco. Over five days, 60 students, researchers, and professionals—selected from more than 1,300 applications—took part in an intensive program combining theoretical courses, hands-on workshops, keynote lectures, evening mentorship sessions, and a hackathon. Following the first edition in 2024, led by INPT, IMT Nord Europe, and the Soft Centre, this new edition was organized in partnership with MoroccoAI, an initiative led by AI experts in Morocco and abroad to promote the growth of AI across the country. This Summer School welcomed students and early-career researchers from Morocco, Germany, France, Italy, Tunisia, and other African countries, further strengthening its international reach. More than 50% of the participants were women.
We chose to offer a summer school with low registration fees (thanks to the additional support of SIGMM), so that as many students and young researchers from diverse backgrounds as possible could attend.
Invited speakers
The AI Summer School presents a distinguished lineup
of speakers who bridge the gap between academic research and industry
innovation. Our carefully selected experts combine theoretical expertise with
practical insights, offering participants a comprehensive understanding of AI’s
current landscape and future directions.
Pioneering the Future of AI in E-Commerce: Foundation Models and Generative AI at Amazon, Dr. Amin Mantrach, Applied Science Manager, Amazon, Luxembourg
Geometric Deep Learning for Non-Rigid Shapes: From Theory to Practice, Dr. Emery Pierson, Researcher LIX, Ecole Polytechnique, France
Towards Detailed Understanding of the Visual World in Generative AI Era, Dr. Fahad Shahbaz Khan, the MBZUAI, Abu Dhabi, United Arab Emirates
Design Thinking for Human-Centred AI Development, Dr. Houda Chakiri, Al Akhawayn University, Morocco
Leveraging AI for Sustainable Marine Ecosystems, Dr. Jihad Zahir, Cadi Ayyad University, Morocco
4D Human Generation: past, present and the future, Prof. Mohamed Daoudi, IMT Nord Europe, France
Training LLMs: Optimize and Scale Your Training, Nouamane Tazi, ML Research Engineer, Hugging Face, France
Generating Synthetic Face and Body Models, Prof. Stefano Berretti, Department of Information Engineering of University of Firenze, Italy
From Generative to Agentic: The Next Era of Computing, Dr. Kaoutar El Maghraoui, Principal Research Scientist and Manager, IBM T.J. Watson Research Center, USA
From documents to structure: Hands-on exploration of agentic document extraction, Prof. Omar Souissi, INPT, Morocco
Efficient Speech Generative Modeling with Little Tokenization, Dr. Tatiana Likhomanenko, Staff Research Scientist, Apple, USA
From VAE to Diffusion: probabilistic learning with audio-visual data, Dr. Xavier Alameda-Pineda, Research Director, INRIA, France
Program
The program explored the theoretical and practical Multimodal Foundation Models and Generative AI, large-scale pre-trained models, multimodality (text, image, audio, etc.), and their applications across sectors. Evening sessions were dedicated to intensive mentorship, where participants worked on real-world projects under expert guidance.
On Wednesday, participants visited the Technopark in Casablanca as part of the Morocco Accelerator Program, where they had the opportunity to engage with innovative AI startups and learn about their projects. More information about the summer school on Multimodal Foundation Models and Generative AI is available on the webpage https://ai-summer-school.inpt.ac.ma/.
The final day showcased the
teams’ talent with 15 project presentations from the hackathon, followed by the
closing ceremony and award announcements:
First
Prize – MyIris: A real-time multimodal navigation system for
visually impaired individuals, integrating voice control and video analysis for
safe guidance.
Second
Prize – LALLACare: An innovative platform offering a
low-cost alternative to mammography for early breast cancer screening,
combining thermal imaging with Google’s MedGemma model for fast, accurate, and
explainable assessments.
Special
Jury Prize – Moun9idoun (AiDex): A multimodal AI solution
dedicated to emergency management and community safety.
Acknowledgments:
The organizers extend their sincere thanks to the INPT
staff (reception, cafeteria, and accommodation), in particular Madame Leila
Karakchou, for their invaluable support in facilitating the successful
organization of this Summer School, to all the dedicated volunteers from the
MoroccoAI association, and to Fatih Hamza from the Soft Center for his work in
developing the event website.
From May 5th to 9th, 2025 Meta hosted the plenary meeting of the Video Quality Experts Group (VQEG) in their headquarters in Menlo Park (CA, United Sates). Around 150 participants registered to the meeting, coming from industry and academic institutions from 26 different countries worldwide.
The meeting was dedicated to present updates and discuss about topics related to the ongoing projects within VQEG. All the related information, minutes, and files from the meeting are available online in the VQEG meeting website, and video recordings of the meeting are available in Youtube.
All the topics mentioned bellow can be of interest for the SIGMM community working on quality assessment, but special attention can be devoted to the first activities of the group on Subjective and objective assessment of GenAI content (SOGAI) and to the advances on the contribution of the Immersive Media Group (IMG) group to the International Telecommunication Union (ITU) towards the Rec. ITU-T P.IXC for the evaluation of Quality of Experience (QoE) of immersive interactive communication systems.
Readers of these columns who are interested in VQEG’s ongoing projects are encouraged to subscribe to the corresponding mailing lists to stay informed and get involved.
Group picture of the meeting
Overview of VQEG Projects
Immersive Media Group (IMG)
The IMG group researches on the quality assessment of immersive media technologies. Currently, the main joint activity of the group is the development of a test plan to evaluate the QoE of immersive interactive communication systems, which is carried out in collaboration with ITU-T through the work item P.IXC. In this meeting, Pablo Pérez (Nokia XR Lab, Spain), Marta Orduna (Nokia XR Lab, Spain), and Jesús Gutiérrez (Universidad Politécnica de Madrid, Spain) presented the status of this recommendation and the next steps to be addressed towards a new contribution to ITU-T in its next meeting in September 2025. Also, in this meeting, it was decided that Marta Orduna will replace Pablo Pérez as vice-chair of IMG. In addition, the following presentations related to IMG topics were delivered:
Gareth Rendle (Bauhaus-Universität Weimar, Germany) and Felix Immohr (TU Ilmenau, Germany) presented a user study on the influence of audiovisual realism on communication behaviour in group-to-group telepresence, showing that avatar realism has positive effects on subjective ratings of perceived message understanding and group cohesion, and yields behavioural differences that indicate more interactivity and engagement. Also, Anton Lammert (Bauhaus-Universität Weimar, Germany), presented his work (in collaboration with Gareth and Felix) on a system designed for the comprehensive analysis of social Virtual Reality (VR) studies, called Immersive Study Analyzer (ISA), which records all user actions, speech, and the contextual environment.
Kamil Koniuch, Norbert Barczyk, Lucjan Janowski, and Mateusz Olszewski (AGH University of Krakow, Poland) presented their work on developing VR games based on circumplex model of group tasks for Quality of Experience (QoE) measurements.
The SAM group investigates on analysis methods both for the results of subjective experiments and for objective quality models and metrics. In relation with these topics, the following presentations were delivered during the meeting:
Dietmar Saupe (University of Konstanz, Germany) delivered two presentations. The first one covered the updates on the JPEG Assessment of Image Coding (AIC) project, especially the JPEG AIC-3, which is a standard (currently under review at ISO/IEC) for fine-grained subjective assessment of image quality in the high-fidelity range. The second one focused on the robustness and accuracy of Mean Opinion Scores (MOSs) with hard and soft outlier detection and proposed two new outlier detection methods with low complexity and excellent worst-case performance.
Mohsen Jenadeleh (University of Konstanz, Germany) and Jon Sneyers (Cloudinary, Belgium) presented their work on fine-grained High dynamic range (HDR) image quality assessment, introducing the AIC-HDR2025 dataset, comprising 100 test images generated from five sources with different encoding configurations and presenting the results of a subjective tests with it. In addition, Mohsen also presented his research on subjective visual quality assessment for high-fidelity learning-based image compression, which covered a comprehensive subjective visual quality assessment of JPEG AI-compressed images using the JPEG AIC-3 methodology, which quantifies differences in Just Noticeable Difference (JND) units.
Panagiotis Traganitis (Michigan State University, United States) presented a unified framework for learning from crowdsourced noisy labels, covering classical and modern methods for aggregating rankings while inferring annotator quality, as well as its application in ranking problems.
Joint Effort Group (JEG) – Hybrid
The group JEG addresses several areas of Video Quality Assessment (VQA), such as the creation of a large dataset for training such models using full-reference metrics instead of subjective metrics. The chair of this group, Enrico Masala (Politecnico di Torino, Italy) presented the updates on the latest activities of the group, including the current results of the Implementer’s Guide for Video Quality Metrics (IGVQM) project. In addition to this, the following presentations were delivered:
The ETG group focuses on various aspects of multimedia that, although they are not necessarily directly related to “video quality”, can indirectly impact the work carried out within VQEG and are not addressed by any of the existing VQEG groups. In particular, this group aims to provide a common platform for people to gather together and discuss new emerging topics, possible collaborations in the form of joint survey papers, funding proposals, etc. In this sense, the following topics were presented and discussed in the meeting:
Avinab Saha (UT Austin, United States) presented the dataset of perceived expression differences, FaceExpressions-70k, which contains 70,500 subjective expression comparisons rated by over 1,000 study participants obtained via crowdsourcing.
David Ronca (Meta Platforms Inc. United States) presented the Video Codec Acid Test (VCAT), which is a benchmarking tool for hardware and software decoders on Android devices.
Subjective and objective assessment of GenAI content (SOGAI)
The SOGAI group seeks to standardize both subjective testingmethodologies and objective metrics for assessing the quality of GenAI-generated content. In this first meeting of the group since its foundation, the following topics were presented and discussed:
Ryan Lei and Qi Cai (Meta Platforms Inc., United states) presented their work on learning from subjective evaluation of Super Resolution (SR) in production use cases at scale, which included extensive benchmarking tests and subjective evaluation with external crowdsource vendors.
Ioannis Katsavounidis, Qi Cai, Elias Kokkinis, Shankar Regunathan (Meta Platforms Inc., United States) presented their work on learning from synergistic subjective/objective evaluation of auto dubbing in production use cases.
Kamil Koniuch (AGH University of Krakow, Poland) presented his research on cognitive perspective on Absolute Category Rating (ACR) scale tests
Patrick Le Callet (Nantes Universite, France) presented his work, in collaboration with researchers from SJTU (China) on perceptual quality assessment of AI-generated omnidirectional images, including the annotated dataset called AIGCOIQA2024.
Multimedia Experience and Human Factors (MEHF)
The MEHF group focuses on the human factors influencing audiovisual and multimedia experiences, facilitating a comprehensive understanding of how human factors impact the perceived quality of multimedia content. In this meeting, the following presentations were given:
Dawid Juszka (AGH University of Krakow, Oland) presented his study on the impact of valence and arousal of video content on subjective QoE assessment scores.
Tomasz Konaszyński (AGH University of Krakow, Poland) presented his research on human and contextual bias in QoE, addressing the impact of testers’ psychophysical condition, declared at the beginning of the research process.
The 5GKPI group studies the relationship between key performance indicators of new 5G networks and QoE of video services on top of them. In this meeting, Pablo Pérez (Nokia XR Lab, Spain) and the rest of the team presented a first draft of the VQEG Whitepaper on QoE management in telecommunication networks, which shares insights and recommendations on actionable controls and performance metrics that the Content Application Providers (CAPs) and Network Service Providers (NSPs) can use to infer, measure and manage QoE.
In addition, Pablo Perez (Nokia
XR Lab, Spain), Marta Orduna (Nokia XR Lab, Spain), and Kamil Koniuch (AGH University of Krakow, Poland) presented design guidelines
and a proposal of a simple but practical QoE model for communication networks,
with a focus on 5G/6G compatibility.
Quality Assessment for Health Applications (QAH)
The QAH group is focused on the quality assessment of health applications. It addresses subjective evaluation, generation of datasets, development of objective metrics, and task-based approaches. In this meeting, Lumi Xia (INSA Rennes, France) presented her research on task-based medical image quality assessment by numerical observer.
Other updates
Apart from this, Ajit Ninan (Meta Platforms Inc., United States) delivered a keynote on rethinking visual quality for perceptual display; a panel was organized with Christos Bampis (Netflix, United States), Denise Noyes (Meta Platforms Inc., United States), and Yilin Wang (Google, United States) addressing what more is left to do on optimizing video quality for adaptive streaming applications, which was moderated by Narciso García (Universidad Politécnica de Madrid, Spain); and there was a co-located ITU-T Q19 interim meeting. In addition, although no progresses were presented in this meeting, the groups on No Reference Metrics (NORM) and on Quality Assessment for Computer Vision Applications (QACoViA) are still active.
Finally, as already announced in the VQEG website, the next VQEG plenary meeting will be online or hybrid online/in-person, probably in November or December 2025.
The 16th ACM Multimedia Systems Conference (with the associated workshops: NOSSDAV 2025 and MMVE 2025) was held from March 31st to April 4th 2025, in Stellenbosch, South Africa. By choosing this location, the steering committee marked a milestone for SIGMM: MMSys became the very first SIGMM conference to take place on the African continent. This perfectly aligns with the SIGMM ongoing mission to build an inclusive and globally representative multimedia‑systems community.
The MMSys conference brings together researchers in multimedia systems to showcase and exchange their cutting-edge research findings. Once again, there were technical talks spanning various multimedia domains and inspiring keynote presentations.
Recognising the importance of in‑person exchange—especially for early‑career researchers—SIGMM once again funded Student Travel Grants. This support enabled a group of doctoral students to attend the conference, present their work and start building their international peer networks. In this column, the recipients of the travel grants share their experiences at MMSys 2025.
Guodong Chen – PhD student, Northeastern University, USA
What an incredible experience attending ACM MMSys 2025 in South Africa! Huge thanks to SIGMM for the travel grant that made this possible.
It was an honour to present our paper, “TVMC: Time-Varying Mesh Compression Using Volume-Tracked Reference Meshes”, and I’m so happy that it received the Best Reproducible Paper Award!
MMSys is not that huge, but it’s truly great. It’s exceptionally well-organized, and what impressed me the most was the openness and enthusiasm of the community. Everyone is eager to communicate, exchange ideas, and dive deep into cutting-edge multimedia systems research. I made many new friends and discovered exciting overlaps between my research and the work of other groups. I believe many collaborations are on the way and that, to me, is the true mark of a successful conference.
Besides the conference, South Africa was amazing, don’t miss the wonderful wines of Stellenbosch and the unforgettable experience of a safari tour.
Lea Brzica – PhD student, University of Zagreb, Croatia
Attending MMSys’25 in Stellenbosch, South Africa was an unforgettable and inspiring experience. As a new PhD student and early-career researcher, this was not only my first in-person conference but also my first time presenting. I was honoured to share my work, “Analysis of User Experience and Task Performance in a Multi-User Cross-Reality Virtual Object Manipulation Task,” and excited to see genuine interest from other attendees. Beyond the workshop and technical sessions, I thoroughly enjoyed the keynotes and panel discussions. The poster sessions and demos were great opportunities to explore new ideas and engage with people from all over the world. One of the most meaningful aspects of the conference was the opportunity to meet fellow PhD students and researchers face-to-face. The coffee breaks and social activities created a welcoming atmosphere that made it easy to form new connections.
I am truly grateful to SIGMM for supporting my participation. The travel grant helped alleviate the financial burden of international travel and made this experience possible. I’m already hoping for the chance to come back and be part of it all over again!
My time at MMSys 2025 was an incredibly rewarding experience. It was great meeting so many interesting and passionate people in the field, and the reception was both enthusiastic and exceptionally well organized. I want to sincerely thank SIGMM for the travel grant, as their support made it possible for me to attend and present my work. South Africa was an amazing destination, and the entire experience was both professionally and personally unforgettable. MMSys was also the perfect environment for networking, offering countless opportunities to connect with researchers and industry experts. It was truly exciting to see so much interest in my work and to engage in meaningful conversations with others in the multimedia systems community.
The 3rd edition of the Spring School on Social XR organised by Distributed and Interactive Systems group (DIS) at CWI in Amsterdam took place from 7 to 10 April 2025. The event attracted 30 students from different disciplines (technology, social sciences, and humanities) and countries from the world (Europe but also Canada and USA). The event was organized by Silvia Rossi, Irene Viola, Thomas Röggla, and Pablo Cesar from CWI; and Omar Niamut from TNO. Also this year, it was co-sponsored by ACM SIGMM, thanks to the founding for Special initiatives, and for the first time has been recognised as an ACM Europe Council Seasonal School.
Students and organisers of the 3rd Spring School on Social XR
Across 9 lectures (4 of them open to public) and three hands‑on workshops led by 14 international instructors, participants had the possibility to have cross-domain interactions on Social XR. Sessions ranged from photorealistic avatar capture and behaviour modelling, through AI‑driven volumetric‑video production, low‑latency streaming and novel rendering techniques, to rigorous QoE evaluation frameworks and open immersive‑media datasets. A new thematic topic this year tackled the privacy, security and UX challenges that arise when immersive systems move from lab prototypes to real‑world communication platforms. Together, they provided a holistic perspective, helping participants to better understand the area and to initiate a network of collaboration to overcome current limitations of current real-time conferencing systems. A unique feature of the school is its Open Days, where selected keynotes are made publicly accessible both in person and via live streaming, ensuring broader engagement with the XR research community. In addition to theoretical and hands-on sessions, the school supports networking and discussions through dedicated events, including a poster presentation where participants can receive feedback from peers and experts in the field of Social XR.
“The Multiple Dimensions of Social in Social XR” by Sun Joo (Grace) Ahn (University of Georgia, USA)
“Shaping VR Experiences: Designing Applications and Experiences for Quality of Experience Assessment” by Marco Carli (Universitá degli Studi Roma TRE, Italy)
“Making a Virtual Reality” by Elmar Eisemann (TU Delft, The Netherlands)
“Robotic Avatar Mediated Social Interaction” by Jan van Erp (TNO & University of Twente, The Netherlands)
“Novel Opportunities and Emerging Risks of Social Virtual Reality Spaces for Online Interactions” by Guo Freeman (Clemson University, USA)
“Privacy, Security and UX Challenges in (Social) XR: an Overview” by Katrien de Moor (NTNU, Norway)
“AI-based Volumetric Content Creation for Immersive XR Experiences and Production Workflows” by Aljosa Smolic (Hochschule Luzern, Switzerland)
“Changing Habits, One Experience at a Time” by Funda Yildirim (University of Twente, The Netherlands)
“Challenge-Driven Quality Evaluation and Dataset Development for Immersive Visual Experiences” by Emin Zerman (Mid Sweden University, Sweden)
The list of Workshops were:
“Cooperative Development of Social XR Evaluation Methods” by Jesús Gutiérrez (Universidad Politecnica de Madrid, Spain) and Pablo Pérez (Nokia XR Labs, Spain)
“From Principle to Practice: Public Values in Action” by Mariëtte van Huijstee (Rathenau Institute, The Netherlands) and Paulien Dresscher (PublicSpaces, The Netherlands)
“Interoperability: What is a Visual Positioning System and Why an Open Source One and Interoperability Between These Systems Need to be Established” by Alina Kadlubsky (Open AR Cloud Europe, Germany)
JPEG assesses responses to its Call for Proposals on Lossless Coding of Visual Events
The 107th JPEG meeting was held in Brussels, Belgium, from April 12 to 18, 2025. During this meeting, the JPEG Committee assessed the responses to its call for proposals on JPEG XE, an International Standard for lossless coding of visual events. JPEG XE is being developed under the auspices of three major standardisation organisations: ISO, IEC, and ITU. It will be the first codec developed by the JPEG committee targeting lossless representation and coding of visual events.
The JPEG Committee is also working on various standardisation projects, such as JPEG AI, which uses learning technology to achieve high compression, JPEG Trust, which sets standards to combat fake media and misinformation while rebuilding trust in multimedia, and JPEG DNA, which represents digital images using DNA sequences for long-term storage.
The following sections summarise the main highlights of the 107th JPEG meeting:
JPEG XE
JPEG AI
JPEG Trust
JPEG AIC
JPEG Pleno
JPEG DNA
JPEG XS
JPEG RF
JPEG XE
This initiative focuses on a new imaging modality produced by event-based visual sensors. This effort aims to establish a standard that efficiently represents and codes events, thereby enhancing interoperability in sensing, storage, and processing for machine vision and related applications.
As a response to the JPEG XE Final Call for Proposals on lossless coding of events, the JPEG Committee received five innovative proposals for consideration. Their evaluation indicated that two among them meet the stringent requirements of the constrained case, where resources, power, and complexity are severely limited. The remaining three proposals can cater to the unconstrained case. During the 107th JPEG meeting, the JPEG Committee launched a series of Core Experiments to define a path forward based on the received proposals as a starting point for the development of the JPEG XE standard.
To streamline the standardisation process, the JPEG Committee will proceed with the JPEG XE initiative in three distinct phases. Phase 1 will concentrate on lossless coding for the constrained case, while Phase 2 will address the unconstrained case. Both phases will commence simultaneously, although Phase 1 will follow a faster timeline to enable a timely publication of the first edition of the standard. The JPEG Committee recognises the urgent industry demand for a standardised solution for the constrained case, aiming to produce a Committee Draft by as early as July 2025. The third phase will focus on lossy compression of event sequences. The discussions and preparations will be initiated soon.
In a significant collaborative effort between ISO/IEC JTC 1/SC 29/WG1 and ITU-T SG21, the JPEG Committee will proceed to specify a joint JPEG XE standard. This partnership will ensure that JPEG XE becomes a shared standard under ISO, IEC, and ITU-T, reflecting their mutual commitment to developing standards for event-based systems.
Additionally, the JPEG Committee is actively discussing and exploring lossy coding of visual events, exploring future evaluation methods for such advanced technologies. Stakeholders interested in JPEG XE are encouraged to access public documents available at jpeg.org. Moreover, a joint Ad-hoc Group on event-based vision has been formed between ITU-T Q7/21 and ISO/IEC JTC1 SC29/WG1, paving the way for continued collaboration leading up to the 108th JPEG meeting.
JPEG AI
At the 107th JPEG meeting, JPEG AI discussions focused around conformance (JPEG AI Part 4), which has now advanced to the Draft International Standard (DIS) stage. The specification defines three conformance points — namely, the decoded residual tensor, the decoded latent space tensor (also referred to as feature space), and the decoded image. Strict conformance for the residual tensor is evaluated immediately after entropy decoding, while soft conformance for the latent space tensor is assessed after tensor decoding. The decoded image conformance is measured after converting the image to the output picture format, but before any post-processing filters are applied. Regarding the decoded image, two types have been defined: conformance Type A, which implies low tolerance, and conformance Type B, which allows for moderate tolerance.
During the 107th JPEG meeting, the results of several subjective quality assessment experiments were also presented and discussed, using different methodologies and for different test conditions, from low to very high qualities, including both SDR and HDR images. The results of these evaluations have shown that JPEG AI is highly competitive and, in many cases, outperforms existing state-of-the-art codecs such as VVC Intra, AVIF, and JPEG XL. A demonstration of an JPEG AI encoder running on a Huawei Mate50 Pro smartphone with a Qualcomm Snapdragon 8+ Gen1 chipset was also presented. This implementation supports tiling, high-resolution (4K) support, and a base profile with level 20. Finally, the implementation status of all mandatory and desirable JPEG AI requirements was discussed, assessing whether each requirement had been fully met, partially addressed, or remained unaddressed. This helped to clarify the current maturity of the standard and identify areas for further refinements.
JPEG Trust
Building on the publication of JPEG Trust (ISO/IEC 21617) Part 1 – Core Foundation in January 2025, the JPEG Committee approved a Draft International Standard (DIS) for a 2nd edition of Part 1 – Core Foundation during the 107th JPEG meeting. This Part 1 – Core Foundation 2nd edition incorporates the signalling of identity and intellectual property rights to address three particular challenges:
achieving transparency, through the signaling of content provenance
identifying content that has been generated either by humans, machines or AI systems, and
enabling interoperability, for example, by standardising machine-readable terms of use of intellectual property, especially AI-related rights reservations.
Additionally, the JPEG Committee is currently developing Part 2 – Trust Profiles Catalogue. Part 2 provides a catalogue of trust profile snippets that can be used either on their own or in combination for the purpose of constructing trust profiles, which can then be used for assessing the trustworthiness of media assets in given usage scenarios. The Trust Profiles Catalogue also defines a collection of conformance points, which enables interoperability across usage scenarios through the use of associated trust profiles.
The Committee continues to develop JPEG Trust Part 3 – Media asset watermarking to build out additional requirements for identified use cases, including the emerging need to identify AIGC content.
Finally, during the 107th meeting, the JPEG Committee initiated a Part 4 – Reference software, which will provide reference implementations of JPEG Trust to which implementers can refer to in developing trust solutions based on the JPEG Trust framework.
JPEG AIC
The JPEG AIC Part 3 standard (ISO/IEC CD 29170-3), has received a revised title “Information technology — JPEG AIC Assessment of image coding — Part 3: Subjective quality assessment of high-fidelity images”. At the 107th JPEG meeting, the results of the last Core Experiments for the standard and the comments on the Committee Draft of the standard were addressed. The draft text was thoroughly revised and clarified, and has now advanced to the Draft International Standard (DIS) stage.
Furthermore, Part 4 of JPEG AIC deals with objective quality metrics, also of high-fidelity images, and at the 107th JPEG meeting, the technical details regarding anchor metrics as well as the testing and evaluation of proposed methods were discussed and finalised. The results have been compiled in the document “Common Test Conditions on Objective Image Quality Assessment”, available on the JPEG website. Moreover, the corresponding Final Call for Proposals on Objective Image Quality Assessment (AIC-4) has been issued. Proposals are expected at the end of Summer 2025. The first Working Draft for Objective Image Quality Assessment (AIC-4) is planned for April 2026.
JPEG Pleno
The JPEG Pleno Light Field activity discussed the DoCR for the submitted Committee Draft (CD) of the 2nd edition of ISO/IEC 21794-2 (“Plenoptic image coding system (JPEG Pleno) Part 2: Light field coding”). This 2nd edition integrates AMD1 of ISO/IEC 21794-2 (“Profiles and levels for JPEG Pleno Light Field Coding”) and includes the specification of a third coding mode entitled Slanted 4D Transform Mode and its associated profile. It is expected that at the 108th JPEG meeting this new edition will advance to the Draft International Standard (DIS) stage.
Software tools have been created and tested to be added as Common Test Condition Tools to a reference software implementation for the standardized technologies within the JPEG Pleno framework, including the JPEG Pleno Part 2 (ISO/IEC 21794-2).
In the framework of the ongoing standardisation effort on quality assessment methodologies for light fields, significant progress was achieved during the 107th JPEG meeting. The JPEG Committee finalised the Committee Draft (CD) of the forthcoming standard ISO/IEC 21794-7 entitled JPEG Pleno Quality Assessment – Light Fields, representing an important step toward the establishment of reliable tools for evaluating the perceptual quality of light fields. This CD incorporates recent refinements to the subjective light field assessment framework and integrates insights from the latest core experiments.
The Committee also approved the Final Call for Proposals (CfP) on Objective Metrics for JPEG Pleno Quality Assessment – Light Fields. This initiative invites proposals of novel objective metrics capable of accurately predicting perceived quality of compressed light field content. The detailed submission timeline and required proposal components are outlined in the released final CfP document. To support this process, updated versions of the Use Cases and Requirements (v6.0) and Common Test Conditions (v2.0) related to this CfP were reviewed and made available. Moreover, several task forces have been established to address key proposal elements, including dataset preparation, codec configuration, objective metric evaluation, and the subjective experiments.
At this meeting, ISO/IEC 21794-6 (“Plenoptic image coding system (JPEG Pleno) Part 6: Learning-based point cloud coding”) progressed to the balloting of the Final Draft International Standard (FDIS) stage. Balloting will end on the 12th of June 2025 with the publication of the International Standard expected for August 2025.
The JPEG Committee held a workshop on Future Challenges in Compression of Holograms for XR Applications organised on April 16th, covering major applications from holographic cameras to holographic displays. The 2nd workshop for Future Challenges in Compression of Holograms for Metrology Applications is planned for July.
JPEG DNA
The JPEG Committee continues to develop JPEG DNA, an ambitious initiative to standardize the representation of digital images using DNA sequences for long-term storage. Following a Call for Proposals launched at its 99th JPEG meeting, a Verification Model was established during the 102nd JPEG meeting, then refined through core experiments that led to the first Working Draft at the 103rd JPEG meeting.
New JPEG DNA logo.
At its 105th JPEG meeting, JPEG DNA was officially approved as a new ISO/IEC project (ISO/IEC 25508), structured into four parts: Core Coding System, Profiles and Levels, Reference Software, and Conformance. The Committee Draft (CD) of Part 1 was produced at the 106th JPEG meeting.
During the 107th JPEG meeting, the JPEG Committee reviewed the comments received on the CD of JPEG DNA standard and prepared a Disposition of Comments Report (DoCR). The goal remains to reach International Standard (IS) status for Part 1 by April 2026.
On this occasion, the official JPEG DNA logo was also unveiled, marking a new milestone in the visibility and identity of the project.
JPEG XS
The development of the third edition of the JPEG XS standard is nearing its final stages, marking significant progress for the standardisation of high-performance video coding. Notably, Part 4, focusing on conformance testing, has been officially accepted by ISO and IEC for publication. Meanwhile, Part 5, which provides reference software, is presently at Draft International Standard (DIS) ballot stage.
In a move that underscores the commitment to accessibility and innovation in media technology, both Part 4 and Part 5 will be made publicly available as free standards. This decision is expected to facilitate widespread adoption and integration of JPEG XS in relevant industries and applications.
Looking to the future, the JPEG Committee is exploring enhancements to the JPEG XS standard, particularly in supporting a master-proxy stream feature. This feature enables a high-fidelity master video stream to be accompanied by a lower-resolution proxy stream, ensuring minimal overhead. Such functionalities are crucial in optimising broadcast and content production workflows.
JPEG RF
The JPEG RF activity issued the proceedings of the Joint JPEG/MPEG Workshop on Radiance Fields which was held on the 31st of January and featured world-renowned speakers discussing Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) from the perspective of both academia, industry, and standardisation groups. Video recordings and all related material were made publicly available on the JPEG website. Moreover, an improved version of the JPEG RF State of the Art and Challenges document was proposed, including an updated review of coding techniques for radiance fields as well as newly identified use cases and requirements. The group also defined an exploration study to investigate protocols for subjective and objective quality assessment, which are considered to be crucial to advance this activity towards a coding standard for radiance fields.
Final Quote
“A cost-effective and interoperable event-based vision ecosystem requires an efficient coding standard. The JPEG Committee embraces this new challenge by initiating a new standardisation project to achieve this objective.” said Prof. Touradj Ebrahimi, the Convenor of the JPEG Committee.
The 16th ACM Multimedia Systems Conference and its associated workshops (MMVE 2025 and NOSSDAV’25) were held from March 31st to April 4th 2025, in Stellenbosch, South Africa. With the intention to create a diverse and inclusive community for multimedia systems, several activities were followed. In this column, we provide a brief overview of different Diversity and Inclusion activities taken before and during the 16th ACM MMSys’25.
Student Travel Grant: ACM SIGMM offered travel grants for students in order to promote participation and diversity of students in the conference. ACM SIGMM has centralised support for standard student travel for in-person participation, and any student member of SIGMM, and those who were the first author of an accepted paper, were eligible and encouraged to apply. Female and minority students’ applications were also encouraged.
Young African Researcher Travel Awards: Travel grants were awarded specifically aimed to support young African researchers to attend the ACM MMSys’25 Conference and its co-located workshops. These awards targeted to foster diversity, promote knowledge exchange, and strengthen the multimedia systems research community across Africa. One of the eligibility criteria was to be affiliated with an African institution or to be an enrolled PhD student at an African higher learning institution.
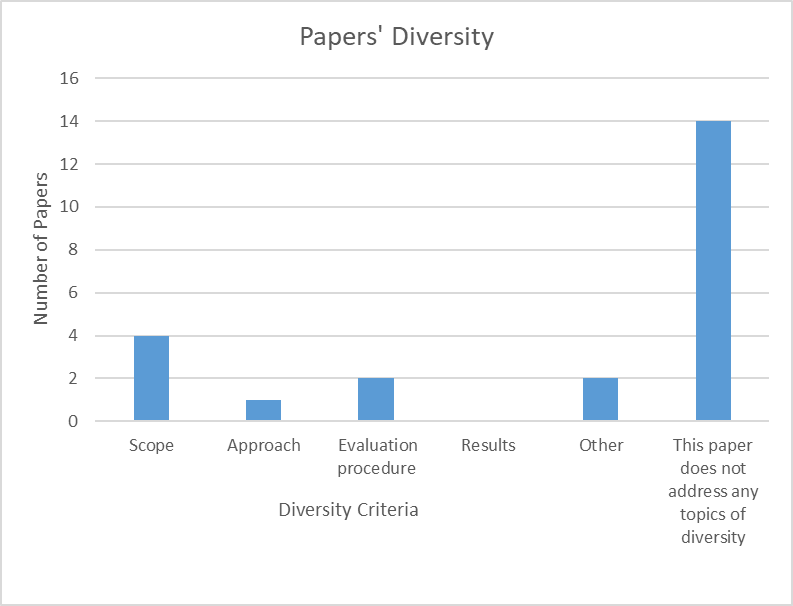
Diversity in Papers
Previous to the conference, a brief analysis was done to understand how diverse and inclusive are the submitted papers. During the review process, paper reviewers indicated weather a paper tackled any aspect of diversity and inclusion by considering the following diversity criteria:
Scope
Approach
Evaluation procedure
Results
Other
This paper does not address any topics of diversity
It was found that the majority of papers did not address any topic of diversity, as shown in the diagram below. With these results in mind, we decided to organise a pabel about how to increase diversity and inclusion in future submissions to the conference.
Activities at the Conference: The Diversity Panel
Fuelled by the
results of the study about diversity in MMSys’25 papers, the conference featured
a panel discussion with the purpose to understand how
diverse and inclusive are the topics, methodologies and evaluations in the
papers submitted to the conference. In particular, the topics of discussion
were (i) Implementing Diversity
and Inclusion in research; (ii) Challenges in implementing Diversity and
Inclusion; (iii) Inclusive and Diverse Practices; and (iv) Monitoring
implementation progress.
Diversity and Inclusion panel discussion in this
context targeted to explore how researchers/academia accommodate or work
together with their relevant stakeholders or communities during their research
activities, and during results dissemination such as in conferences.
To enable the discussion, we invited 4 panellists with different expertise both from academia and industry. These were:
Professor Vali Lalioti University of the Arts London (United Kingdom)
Vali Lalioti is a pioneering designer, computer scientist, and innovator. She is Professor of Creative XR and Robotics and Director of Programmes at the Creative Computing Institute (CCI), University of the Arts London (UAL). She played a key role in developing the world’s first Virtual Reality (VR) systems in Germany. Her research focuses on human-robot interaction, robotic movement design, and XR for societal impact, spanning well-being, healthy aging, performance art, and the future of work. She pioneered BBC’s first Augmented Reality production (2003). As Founder-Director at CCI, she founded the Creative XR and Robotics Research Hub, that led the Institute’s expansion.
Associate Professor. Ketan Mayer-Patel University of North Carolina at Chapel Hill
Ketan Mayer-Patel is an associate professor in the Department of Computer Science at the University of North Carolina. His research generally focuses on multimedia systems, networking, and multicast applications. Currently, he is investigating model-based video coding, dynamic media coding models, and networking problems associated with multiple independent, but semantically related, media streams.
Dr. Marta Orduna Nokia XR Lab; Madrid,Spain
Marta Orduna is a Telecommunication Engineer, Bachelor of Engineering in Telecommunication Technologies and Services in 2016 and Master in Telecommunication Engineering in 2018 both from Universidad Politécnica de Madrid (UPM). In 2023, she received her PhD from UPM entitled “Understanding and Assessing Quality of Experience in Immersive Communications”, reaching Cum Laude. In 2023, she joined Nokia Extended Reality Lab team in Spain, where she continues her research line of the PhD in the area of quality of experience in extended reality
Professor Gregor Schiele University Duisburg-Essen, Germany
GregorSchiele is leading the research lab on Intelligent Embedded Systems at the University of Duisburg-Essen in Germany. Professor Gregor’s goal is to make deep learning algorithms so efficient that they can be executed efficiently on every computer device, including tiny embedded sensors and wearable XR devices. He is a big fan of the MMSys community and its constructive discussion culture.
Below, we provide a summary of the main findings on the four presented topics:
(1) Implementing Diversity and Inclusion in research
The panel discussion revealed that all panellists
have worked or collaborated successfully with stakeholders outside their
workplaces. Diversity and inclusion were mainly implemented via data collection
for research work, co-creation, stakeholders’ workshops or seminars, and in
research methodologies such as working with community in participatory action.
The discussion highlighted the experience of our panellists with diversity
measures as well as helped rising awareness in the audience as to what could
they apply as diversity measures to their own work.
(2) Challenges in implementing the Diversity and Inclusion
The following were mentioned as challenges in implementing diversity and inclusion in research and research dissemination activities:
Financial and time constraints,
Different organizational culture,
Difficulty to find a common time for collaboration due to different priorities,
Differences in language, organizational priorities and objectives.
(3) Inclusive and Diverse Practices
The panel discussed how to build a diverse and an inclusive conference in terms of topics, methodology (variety of approaches in pre-conference, during the conference and post conference). The following are some of the proposed practices:
In a conference, invite at least three best papers and three best demos from other related conferences to present their work and showcase their demos respectively.
Co-location of at least two conferences or workshop with related or complementing themes.
Focus on relevant related conferences to find a match which will lead to run a common workshop, this will build relation that can lead to conferences co-location hence diversity and inclusion.
Invite University graduates employers and equipment vendors or manufacturers to participate and exhibit their products in conferences.
Provide avenue in conferences for stakeholders to interact with academia such as in roundtable discussion or debates between academia vs industry and keynote presentation from industry/stakeholders.
Run a flagship workshops or conferences with switching roles, for example this year the conference is for academia while industry/stakeholders are invited and assigned minor roles, next year the conference is dominated by industry/stakeholders and academia are invited with minor roles in the conference
Run a conference with tracks of diverse and inclusive themes
In order to accommodate policy makers in conferences, suggestions were as follows:
Invite high profile Government officials such as Ministers or Presidents to officiate or close a conference where they will spend few hours listening to policy brief aligned to the conference theme or to the major conference resolutions during conference opening or closing respectively.
Seek audience with the officials to briefly discuss conference resolutions or issues raised during the conference relevant to their offices.
(4)Monitoring implementation progress
Panellists were required to discuss how to track and measure progress in implementing diversity and inclusion in future ACM MMSys conferences. Generally, this point appeared difficult or it was not well understood by the panellists. It received very few and short responses. Most of the responses were kind of recommendation to:
First set performance
criteria which will be used as benchmarks for tracking and measuring
implementation progress on diversity and inclusion.
Develop stages of diverse
and inclusive such as early/infant stage, medium/growing stage and
premium/mature stage to guide a monitoring process, performance parameters and
monitoring tools for paper evaluation process and in pre, during and post
conference.
Concluding Remarks
Diversity and Inclusion activities done at the ACM MMSys 2025 served as important steps in nurturing diverse and inclusive multimedia system community. The activities comprised of travel grants supporting underrepresented and young African researchers, together with panel discussion at the conference. Although paper review analysis discovered that diversity topics remain underrepresented in paper submissions, this finding served as a catalyst for a rigorous panel discussion, that leads to concrete recommendations. Going forward, the multimedia systems community is encouraged to adopt a smart framework with progress stages and performance parameters to monitor and track progress of diversity and inclusion in the ACM MMSys conference series.
The last plenary meeting of the Video Quality Experts Group (VQEG) was held online by the Institute for Telecommunication Sciences (ITS) of the National Telecommunications and Information Adminsitration (NTIA) from November 18th to 22nd, 2024. The meeting was attended by 70 participants from industry and academic institutions from 17 different countries worldwide.
The meeting was dedicated to present updates and discuss about topics related to the ongoing projects within VQEG. All the related information, minutes, and files from the meeting are available online in the VQEG meeting website, and video recordings of the meeting are available in Youtube.
All the topics mentioned bellow can be of interest for the SIGMM community working on quality assessment, but special attention can be devoted to the creation of a new group focused on Subjective and objective assessment of GenAI content (SOGAI) and to the recent contribution of the Immersive Media Group (IMG) group to the International Telecommunication Union (ITU) towards the Rec. ITU-T P.IXC for the evaluation of Quality of Experience (QoE) of immersive interactive communication systems. Finally, it is worth noting that Ioannis Katsavounidis (Meta, US) joins Kjell Brunnström (RISE, Sweden) as co-chairs of VQEG, substituting Margaret Pinson (NTIA(ITS).
Readers of these columns interested in the ongoing projects of VQEG are encouraged to subscribe to their corresponding reflectors to follow the activities going on and to get involved in them.
Group picture of the online meeting
Overview of VQEG Projects
Audiovisual HD (AVHD)
The AVHD group works on developing and validating subjective and objective methods to analyze commonly available video systems. In this meeting, Lucjan Janowski (AGH University of Krakow, Poland) and Margaret Pinson (NTIA/ITS) presented their proposal to fix wording related to an experiment realism and validity, based on the experience in the psychology domain that addresses the important concept of describing how much results from lab experiment can be used outside a laboratory.
In addition, given that there are no current joint activities of the group, the AVHD project will become dormant, with the possibility to be activated when new activities are planned.
Statistical Analysis Methods (SAM)
The group SAM investigates on analysis methods both for the results of subjective experiments and for objective quality models and metrics. In addition to a discussion on the future activities of the group lead by its chairs Ioannis Katsavounidis (Meta, US), Zhi Li (Netflix, US), and Lucjan Janowski (AGH University of Krakow, Poland), the following presentations were delivered during the meeting:
Dietmar Saupe (University of Konstanz, Germany) delivered two presentations. The first one focused on maximum entropy and quantized metric models for absolute category ratings, based on the investigation of families of multinomial probability distributions parameterized by mean and variance that are used to fit the empirical rating distributions. To validate the proposed models, a comparison of the performance of these models and the state-of-the-art (given by the generalized score distribution) was done on two large datasets (KonIQ-10k and VQEG HDTV). The second presentation proposed a fine-grained subjective visual quality assessment method for high-fidelity compressed images, which is based on the current activities of the JPEG standardization project Advanced Image Coding (AIC). In addition to the assessment method, a dataset of high-quality compressed images and their corresponding crowdsourced visual quality ratings was presented.
The ETG group focuses on various aspects of multimedia that, although they are not necessarily directly related to “video quality”, can indirectly impact the work carried out within VQEG and are not addressed by any of the existing VQEG groups. In particular, this group aims to provide a common platform for people to gather together and discuss new emerging topics, possible collaborations in the form of joint survey papers, funding proposals, etc. During this meeting, Abhijay Ghildyal (Portland State University, US), Saman Zadtootaghaj (Sony Interactive Entertainment, Germany), and Nabajeet Barman (Sony Interactive Entertainment, UK) presented their work on quality assessment of AI generated content and AI enhanced content. In addition, Matthias Wien (RWTH Aachen University, Germany) presented the approach, design and methodology for the evaluation of AI-based Point Cloud Compression in the corresponding Call for Proposals in MPEG. Finally, Abhijay Ghildyal (Portland State University, US) presented his work on how foundation models boost low-level perceptual similarity metrics, investigating the potential of using intermediate features or activations from these models for low-level image quality assessment, and showing that such metrics can outperform existing ones without requiring additional training.
Joint Effort Group (JEG) – Hybrid
The group JEG addresses several areas of Video Quality Assessment (VQA), such as the creation of a large dataset for training such models using full-reference metrics instead of subjective metrics. In addition, the group includes the VQEG project Implementer’s Guide for Video Quality Metrics (IGVQM). The chair of this group, Enrico Masala (Politecnico di Torino, Italy) presented the updates on the latest activities going on, including the plans for experiments within the IGVMQ project to get feedback from other VQEG members.
The IMG group researches on the quality assessment of immersive media technologies. Currently, the main joint activity of the group is the development of a test plan to evaluate the QoE of immersive interactive communication systems, which is carried out in collaboration with ITU-T through the work item P.IXC. In this meeting, Pablo Pérez (Nokia XR Lab, Spain), Marta Orduna (Nokia XR Lab, Spain), and Jesús Gutiérrez (Universidad Politécnica de Madrid, Spain) presented the status of the Rec. ITU-T P.IXC that the group was writing based on the joint test plan developed in the last months and that was submitted to ITU and discussed in its meeting in January 2025.
Also, in relation with this test plan, Lucjan Janowski (AGH University of Krakow, Poland) and Margaret Pinson (NTIA/ITS) presented an overview of ITU recommendations for interactive experiments that can be used in the IMG context.
In relation with other topics addressed by IMG, Emin Zerman (Mid Sweden University, Sweden) delivered two presentations. The first one presented the BASICS dataset, which contains a representative range of nearly 1500 point clouds assessed by thousands of participants to enable robust quality assessments for 3D scenes. The approach involved a careful selection of diverse source scenes and the application of specific “distortions” to simulate real-world compression impacts, including traditional and learning-based methods. The second presentation described a spherical light field database (SLFDB) for immersive telecommunication and telepresence applications, which comprises 60-view omnidirectional captures across 20 scenes, providing a comprehensive basis for telepresence research.
Quality Assessment for Computer Vision Applications (QACoViA)
The group QACoViA addresses the study the visual quality requirements for computer vision methods, where the final user is an algorithm. In this meeting, Mehr un Nisa (AGH University of Krakow, Poland) presented a comparative performance analysis of deep learning architectures in underwater image classification. In particular, the study assessed the performance of the VGG-16, EfficientNetB0, and SimCLR models in classifying 5,000 underwater images. The results reveal each model’s strengths and weaknesses, providing insights for future improvements in underwater image analysis
5G Key Performance Indicators (5GKPI)
The 5GKPI group studies relationship between key performance indicators of new 5G networks and QoE of video services on top of them. In this meeting, Pablo Perez (Nokia XR Lab, Spain) and Francois Blouin (Meta, US) and others presented the progress on the 5G-KPI White Paper, sharing some of the ideas on QoS-to-QoE modeling that the group has been working on to get feedback from other VQEG members.
Multimedia Experience and Human Factors (MEHF)
The MEHF group focuses on the human factors influencing audiovisual and multimedia experiences, facilitating a comprehensive understanding of how human factors impact the perceived quality of multimedia content. In this meeting, Dominika Wanat (AGH University of Krakow, Poland) presented MANIANA (Mobile Appliance for Network Interrupting, Analysis & Notorious Annoyance), an IoT device for testing QoS and QoE applications in home network conditions that is made based on Raspberry Pi 4 minicomputer and open source solutions and allows safe, robust, and universal testing applications.
Other updates
Apart from this, it is worth noting that, although no progresses were presented in this meeting, the Quality Assessment for Health Applications (QAH) group is still active and focused on the quality assessment of health applications. It addresses subjective evaluation, generation of datasets, development of objective metrics, and task-based approaches.
In addition, the Computer Generated Imagery (CGI) project became dormant, since it recent activities can be covered by other existing groups such as ETG and SOGAI.
Also, in this meeting Margaret
Pinson (NTIA/ITS) stepped down as co-chair of VQEG and Ioannis Katsavounidis (Meta,
US) is the new co-chair together with Kjell Brunnström (RISE, Sweden).
The 106th JPEG meeting was held online from January 6 to 10, 2025. During this meeting, the first image coding standard based on machine learning technology, JPEG AI, was sent for publication as an International Standard. This is a major achievement as it leverages JPEG with major trends in imaging technologies and provides an efficient standardized solution for image coding, with nearly 30% improvement over the most advanced solutions in the state-of-the-art. JPEG AI has been developed under the auspices of three major standardization organizations: ISO, IEC and ITU.
The following sections summarize the main highlights of the 106th JPEG meeting.
JPEG AI – the first International Standard for end-to-end learning-based image coding
JPEG Trust – a framework for establishing trust in digital media
JPEG XE – lossless coding of event-based vision
JPEG AIC – assessment of the visual quality of high-fidelity images
JPEG Pleno – standard framework for representing plenoptic data
At its 106th meeting, the JPEG Committee approved publication of the text of JPEG AI, the first International Standard for end-to-end learning-based image coding. This achievement marks a significant milestone in the field of digital imaging and compression, offering a new approach for efficient, high-quality image storage and transmission.
The scope of JPEG AI is the creation of a learning-based image coding standard offering a single-stream, compact compressed domain representation, targeting both human visualization with significant compression efficiency improvement over image coding standards in common use at equivalent subjective quality, and effective performance for image processing and computer vision tasks, with the goal of supporting a royalty-free baseline.
The JPEG AI standard leverages deep learning algorithms that learn from vast amounts of image data the best way to compress images, allowing it to adapt to a wide range of content and offering enhanced perceptual visual quality and faster compression capabilities. The key benefits of JPEG AI are:
Superior compression efficiency: JPEG AI offers higher compression efficiency, leading to reduced storage requirements and faster transmission times compared to other state-of-the-art image coding solutions.
Implementation-friendly encoding and decoding: JPEG AI codec supports a wide array of devices with different characteristics, including mobile platforms, through optimized encoding and decoding processes.
Compressed-domain image processing and computer vision tasks: JPEG AI’s architecture enables multi-purpose optimization for both human visualization and machine-driven tasks.
By creating the JPEG AI International Standard, the JPEG Committee has opened the door to more efficient and versatile image compression solutions that will benefit industries ranging from digital media and telecommunications to cloud storage and visual surveillance. This standard provides a framework for image compression in the face of rapidly growing visual data demands, enabling more efficient storage, faster transmission, and higher-quality visual experiences.
As JPEG AI establishes itself as the new benchmark in image compression, its potential to reshape the future of digital imaging is undeniable, promising groundbreaking advancements in efficiency and versatility.
JPEG Trust
The first part of JPEG Trust, the “Core Foundation” (ISO/IEC 21617-1) was approved for publication in late 2024 and is in the process of being published as an International Standard by ISO. The JPEG Trust standard provides a proactive approach to trust management by defining a framework for establishing trust in digital media. The Core Foundation specifies three main pillars: annotating provenance, extracting and evaluating Trust Indicators, and handling privacy and security concerns.
At the 106th JPEG Meeting, the JPEG Committee produced a Committee Draft (CD) for a 2nd edition of the Core Foundation. The 2nd edition further extends and improves the standard with new functionalities, including important specifications for Intellectual Property Rights (IPR) management such as authorship and rights declarations. In addition, this new edition will align the specification with the upcoming ISO 22144 standard, which is a standard for Content Credentials based on the C2PA 2.1 specification.
In parallel with the work on the 2nd edition of the Core Foundation (Part 1), the JPEG Committee continues to work on Part 2 and Part 3, “Trust Profiles Catalogue” and “Media Asset Watermarking”, respectively.
JPEG XE
The JPEG XE initiative is currently awaiting the conclusion of the open Final Call for Proposals on lossless coding of events, which will close on March 31, 2025. This initiative focuses on a new and emerging image modality introduced by event-based visual sensors. JPEG aims to establish a standard that efficiently represents events, facilitating interoperability in sensing, storage, and processing for machine vision and other relevant applications.
To ensure the success of this emerging standard, the JPEG Committee has reached out to other standardization organizations. The JPEG Committee, already a collaborative group under ISO/IEC and ITU-T, is engaged in discussions with ITU-T’s SG21 to develop JPEG XE as a joint standard. This collaboration aligns perfectly with the objectives of both organizations, as SG21 is also dedicated to creating standards around event-based systems.
Additionally, the JPEG Committee continues its discussions and research on lossy coding of events, focusing on future evaluation methods for these technologies. Those interested in the JPEG XE initiative are encouraged to review the public documents available at jpeg.org. Furthermore, the Ad-hoc Group on event-based vision has been re-established to advance work leading up to the 107th JPEG meeting in Brussels. To stay informed about this activity, please join the event-based vision Ad-hoc Group mailing list.
JPEG AIC
Part 3 of JPEG AIC (AIC-3) defines a methodology for subjective assessment of the visual quality of high-fidelity images, and the forthcoming Part 4 of JPEG AIC deals with objective quality metrics, also of high-fidelity images. In this JPEG meeting, the document on Use Cases and Requirements that refers to both AIC-3 and AIC-4, was revised. It defines the scope of both anticipated standards and sets it into relation to the previous specifications for AIC-1 and AIC-2. While AIC-1 covers a broad quality range including low quality, it does not allow fine-grained quality assessment in the high-fidelity range. AIC-2 entails methods that determine a threshold separating visually lossless coded images from lossy ones. The quality range addressed by AIC-3 and AIC-4 is an interval that contains the AIC-2 threshold, reaching from high quality up to the numerically lossless case. The JPEG Committee is preparing the DIS text for AIC-3 and has launched the Second Draft Call for Proposals on Objective Image Quality Assessment (AIC-4) which includes the timeline for this JPEG activity. Proposals are expected at the end of Summer 2025. The first Working Draft for Objective Image Quality Assessment (AIC-4) is planned for April 2026.
JPEG Pleno
The 106th meeting marked a major milestone for the JPEG Pleno Point Cloud activity with the release of the Final Draft International Standard (FDIS) for ISO/IEC DIS 21794-6:2024 Information technology — Plenoptic image coding system (JPEG Pleno) — Part 6: Learning-based point cloud coding. Point cloud data supports a wide range of applications, including computer-aided manufacturing, entertainment, cultural heritage preservation, scientific research, and advanced sensing and analysis. The JPEG Committee considers this learning-based standard to be a powerful and efficient solution for point cloud coding. This standard is applicable to interactive human visualization, with competitive compression efficiency compared to state-of-the-art point cloud coding solutions in common use, and effective performance for 3D processing and machine-related computer vision tasks and has the goal of supporting a royalty-free baseline. This standard specifies a codestream format for storage of point clouds. The standard also provides information on the coding tools and defines extensions to the JPEG Pleno File Format and associated metadata descriptors that are specific to point cloud modalities. With the release of the FDIS at the 106th JPEG meeting, it is expected that the International Standard will be published in July 2025.
The JPEG Pleno Light Field activity discussed the Committee Draft (CD) of the 2nd edition of ISO/IEC 21794-2 (“Plenoptic image coding system (JPEG Pleno) Part 2: Light field coding”) that integrates AMD1 of ISO/IEC 21794-2 (“Profiles and levels for JPEG Pleno Light Field Coding”) and includes the specification of a third coding mode entitled Slanted 4D Transform Mode and its associated profile.
A White Paper on JPEG Pleno Light Field Coding has been released, providing the architecture of the current two JPEG Pleno Part-2 coding modes, as well as the coding architecture of its third coding mode, to be included in the 2nd edition of the standard. The White Paper also presents applications and use cases and briefly describes the JPEG Pleno Model (JPLM). The JPLM provides a reference implementation for the standardized technologies within the JPEG Pleno framework, including the JPEG Pleno Part 2 (ISO/IEC 21794-2). Improvements to JPLM have been implemented and tested, including a user-friendly interface that relies on well-documented JSON configuration files.
During the JPEG meeting week, significant progress was made in the JPEG Pleno Quality Assessment activity, which focuses on developing methodologies for subjective and objective quality assessment of plenoptic modalities. A Working Draft on subjective quality assessment, incorporating insights from extensive experiments conducted by JPEG experts, was discussed.
JPEG Systems
The reference software of JPEG Systems (ISO/IEC 19566-10) is now published as an International Standard and is available as open source on the JPEG website. This first edition implements the JPEG Universal Metadata Box Format (ISO/IEC 19566-5) and provides a reference dataset. An extended version of the reference software with support for additional Parts of JPEG Systems is currently under development. This new edition will add support for JPEG Privacy and Security, JPEG 360, JLINK, and JPEG Snack.
At its 106th meeting, the JPEG Committee also initiated a 3rd edition of the JPEG Universal Metadata Box Format (ISO/IEC 19566-5). This new edition will integrate the latest amendment that allows JUMBF boxes to exist as stand-alone files and adds support for payload compression. In addition, the 3rd edition will add a JUMBF validator and a scheme for JUMBF box retainment while transcoding from one JPEG format to another.
JPEG DNA
JPEG DNA is an initiative aimed at developing a standard capable of representing bi-level, continuous-tone grayscale, continuous-tone color, or multichannel digital samples in a format using nucleotide sequences to support DNA storage. The JPEG DNA Verification Model (VM) was created during the 102nd JPEG meeting based on performance assessments and descriptive analyses of the submitted solutions to a Call for Proposals, issued at the 99th JPEG meeting. Since then, several core experiments have been continuously conducted to validate and enhance this Verification Model. Such efforts led to the creation of the first Working Draft of JPEG DNA during the 103rd JPEG meeting. At the 105th JPEG meeting, the JPEG Committee officially introduced a New Work Item Proposal (NWIP) for JPEG DNA, elevating it to an officially sanctioned ISO/IEC Project. The proposal defined JPEG DNA as a multi-part standard: Part 1: Core Coding System, Part 2: Profiles and Levels, Part 3: Reference Software, Part 4: Conformance.
The JPEG Committee is targeting the International Standard (IS) stage for Part 1 by April 2026.
At its 106th meeting, the JPEG Committee made significant progress toward achieving this goal. Efforts were focused on producing the Committee Draft (CD) for Part 1, a crucial milestone in the standardization process. Additionally, JPEG DNA Part 1 has now been assigned the Project identification ISO/IEC 25508-01.
JPEG XS
The JPEG XS activity focussed primarily on finalization of the third editions of JPEG XS Part 4 – Conformance testing, and Part 5 – Reference software. Recall that the 3rd editions of Parts 1, 2, and 3 are published and available for purchase. Part 4 is now at FDIS stage and is expected to be approved as International Standard around April of 2025. For Part 5, work on the reference software was completed to implement TDC profile encoding functionality, making it feature complete and fully compliant with the 3rd edition of JPEG XS. As such, Part 5 is ready to be balloted as a DIS. However, work on the reference software will continue to bring further improvements. The reference software and Part 5 will become publicly and freely available, similar to Part 4.
JPEG XL
The second edition of Part 3 (conformance testing) of JPEG XL proceeded to publication as International Standard. Regarding Part 2 (file format), a third edition has been prepared, and it reached the DIS stage. The new edition will include support for embedding gain maps in JPEG XL files.
JPEG 2000
The JPEG Committee has begun work on adding support for the HTTP/3 transport to the JPIP protocol, which allows the interactive browsing of JPEG 2000 images over networks. HTTP/3 is the third major version of the Hypertext Transfer Protocol (HTTP) and allows for significantly lower latency operations compared to earlier versions. A Committee Draft ballot of the 3rd edition of the JPIP specifications (Rec. ITU-T T.808 | ISO/IEC 15444-9) is expected to start shortly, with the project completed sometime in 2026.
Separately, the 3rd edition of Rec. ITU-T T.815 | ISO/IEC 15444-16, which specifies the carriage of JPEG 2000 imagery in the ISOBMFF and HEIF file formats, has been approved for publication. This new edition adds support for more flexible color signaling and JPEG 2000 video tracks.
JPEG RF
The JPEG RF exploration issued at this meeting the “JPEG Radiance Fields State of the Art and Challenges”, a public document that describes the latest developments on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) technologies and defines a scope for the activity focusing on the creation of a coding standard. The JPEG Committee is also organizing a workshop on Radiance Fields jointly with MPEG, which will take place on January 31st, featuring key experts in the field presenting various aspects of this exciting new emerging technology.
Final Quote
“The newly approved JPEG AI, developed under the auspices of ISO, IEC and ITU, is the first image coding standard based on machine learning and is a breakthrough in image coding providing 30% compression gains over the most advanced solutions in state-of-the-art.” said Prof. Touradj Ebrahimi, the Convenor of the JPEG Committee.
The 150th MPEG meeting was held online from 31 March to 04 April 2025. The official press release can be found here. This column provides the following highlights:
Requirements: MPEG-AI strategy and white paper on MPEG technologies for metaverse
JVET: Draft Joint Call for Evidence on video compression with capability beyond Versatile Video Coding (VVC)
Video: Gaussian splat coding and video coding for machines
Audio: Audio coding for machines
3DGH: 3D Gaussian splat coding
MPEG-AI Strategy
The MPEG-AI strategy envisions a future where AI and neural networks are deeply integrated into multimedia coding and processing, enabling transformative improvements in how digital content is created, compressed, analyzed, and delivered. By positioning AI at the core of multimedia systems, MPEG-AI seeks to enhance both content representation and intelligent analysis. This approach supports applications ranging from adaptive streaming and immersive media to machine-centric use cases like autonomous vehicles and smart cities. AI is employed to optimize coding efficiency, generate intelligent descriptors, and facilitate seamless interaction between content and AI systems. The strategy builds on foundational standards such as ISO/IEC 15938-13 (CDVS), 15938-15 (CDVA), and 15938-17 (Neural Network Coding), which collectively laid the groundwork for integrating AI into multimedia frameworks.
Currently, MPEG is developing a family of standards under the ISO/IEC 23888 series that includes a vision document, machine-oriented video coding, and encoder optimization for AI analysis. Future work focuses on feature coding for machines and AI-based point cloud compression to support high-efficiency 3D and visual data handling. These efforts reflect a paradigm shift from human-centric media consumption to systems that also serve intelligent machine agents. MPEG-AI maintains compatibility with traditional media processing while enabling scalable, secure, and privacy-conscious AI deployments. Through this initiative, MPEG aims to define the future of multimedia as an intelligent, adaptable ecosystem capable of supporting complex, real-time, and immersive digital experiences.
MPEG White Paper on Metaverse Technologies
The MPEG white paper on metaverse technologies (cf. MPEG white papers) outlines the pivotal role of MPEG standards in enabling immersive, interoperable, and high-quality virtual experiences that define the emerging metaverse. It identifies core metaverse parameters – real-time operation, 3D experience, interactivity, persistence, and social engagement – and maps them to MPEG’s longstanding and evolving technical contributions. From early efforts like MPEG-4’s Binary Format for Scenes (BIFS) and Animation Framework eXtension (AFX) to MPEG-V’s sensory integration, and the advanced MPEG-I suite, these standards underpin critical features such as scene representation, dynamic 3D asset compression, immersive audio, avatar animation, and real-time streaming. Key technologies like point cloud compression (V-PCC, G-PCC), immersive video (MIV), and dynamic mesh coding (V-DMC) demonstrate MPEG’s capacity to support realistic, responsive, and adaptive virtual environments. Recent efforts include neural network compression for learned scene representations (e.g., NeRFs), haptic coding formats, and scene description enhancements, all geared toward richer user engagement and broader device interoperability.
The document highlights five major metaverse use cases – virtual environments, immersive entertainment, virtual commerce, remote collaboration, and digital twins – all supported by MPEG innovations. It emphasizes the foundational role of MPEG-I standards (e.g., Parts 12, 14, 29, 39) for synchronizing immersive content, representing avatars, and orchestrating complex 3D scenes across platforms. Future challenges identified include ensuring interoperability across systems, advancing compression methods for AI-assisted scenarios, and embedding security and privacy protections. With decades of multimedia expertise and a future-focused standards roadmap, MPEG positions itself as a key enabler of the metaverse – ensuring that emerging virtual ecosystems are scalable, immersive, and universally accessible.
The MPEG white paper on metaverse technologies highlights several research opportunities, including efficient compression of dynamic 3D content (e.g., point clouds, meshes, neural representations), synchronization of immersive audio and haptics, real-time adaptive streaming, and scene orchestration. It also points to challenges in standardizing interoperable avatar formats, AI-enhanced media representation, and ensuring seamless user experiences across devices. Additional research directions include neural network compression, cross-platform media rendering, and developing perceptual metrics for immersive Quality of Experience (QoE).
Draft Joint Call for Evidence (CfE) on Video Compression beyond Versatile Video Coding (VVC)
The latest JVET AHG report on ECM software development (AHG6), documented as JVET-AL0006, shows promising results. Specifically, in the “Overall” row and “Y” column, there is a 27.06% improvement in coding efficiency compared to VVC, as shown in the figure below.
The Draft Joint Call for Evidence (CfE) on video compression beyond VVC (Versatile Video Coding), identified as document JVET-AL2026 | N 355, is being developed to explore new advancements in video compression. The CfE seeks evidence in three main areas: (a) improved compression efficiency and associated trade-offs, (b) encoding under runtime constraints, and (c) enhanced performance in additional functionalities. This initiative aims to evaluate whether new techniques can significantly outperform the current state-of-the-art VVC standard in both compression and practical deployment aspects.
The visual testing will be carried out across seven categories, including various combinations of resolution, dynamic range, and use cases: SDR Random Access UHD/4K, SDR Random Access HD, SDR Low Bitrate HD, HDR Random Access 4K, HDR Random Access Cropped 8K, Gaming Low Bitrate HD, and UGC (User-Generated Content) Random Access HD. Sequences and rate points for testing have already been defined and agreed upon. For a fair comparison, rate-matched anchors using VTM (VVC Test Model) and ECM (Enhanced Compression Model) will be generated, with new configurations to enable reduced run-time evaluations. A dry-run of the visual tests is planned during the upcoming Daejeon meeting, with ECM and VTM as reference anchors, and the CfE welcomes additional submissions. Following this dry-run, the final Call for Evidence is expected to be issued in July, with responses due in October.
The Draft Joint Call for Evidence (CfE) on video compression beyond VVC invites research into next-generation video coding techniques that offer improved compression efficiency, reduced encoding complexity under runtime constraints, and enhanced functionalities such as scalability or perceptual quality. Key research aspects include optimizing the trade-off between bitrate and visual fidelity, developing fast encoding methods suitable for constrained devices, and advancing performance in emerging use cases like HDR, 8K, gaming, and user-generated content.
3D Gaussian Splat Coding
Gaussian splatting is a real-time radiance field rendering method that represents a scene using 3D Gaussians. Each Gaussian has parameters like position, scale, color, opacity, and orientation, and together they approximate how light interacts with surfaces in a scene. Instead of ray marching (as in NeRF), it renders images by splatting the Gaussians onto a 2D image plane and blending them using a rasterization pipeline, which is GPU-friendly and much faster. Developed by Kerbl et al. (2023) it is capable of real-time rendering (60+ fps) and outperforms previous NeRF-based methods in speed and visual quality. Gaussian splat coding refers to the compression and streaming of 3D Gaussian representations for efficient storage and transmission. It’s an active research area and under standardization consideration in MPEG.
MPEG technical requirements working group together with MPEG video working group started an exploration on Gaussian splat coding and the MPEG coding of 3D graphics and haptics (3DGH) working group addresses 3D Gaussian splat coding, respectively. Draft Gaussian splat coding use cases and requirements are available and various joint exploration experiments (JEEs) are conducted between meetings.
(3D) Gaussian splat coding is actively researched in academia, also in the context of streaming, e.g., like in “LapisGS: Layered Progressive 3D Gaussian Splatting for Adaptive Streaming” or “LTS: A DASH Streaming System for Dynamic Multi-Layer 3D Gaussian Splatting Scenes”. The research aspects of 3D Gaussian splat coding and streaming span a wide range of areas across computer graphics, compression, machine learning, and systems for real-time immersive media. In particular, on efficiently representing and transmitting Gaussian-based neural scene representations for real-time rendering. Key areas include compression of Gaussian parameters (position, scale, color, opacity), perceptual and geometry-aware optimizations, and neural compression techniques such as learned latent coding. Streaming challenges involve adaptive, view-dependent delivery, level-of-detail management, and low-latency rendering on edge or mobile devices. Additional research directions include standardizing file formats, integrating with scene graphs, and ensuring interoperability with existing 3D and immersive media frameworks.
MPEG Audio and Video Coding for Machines
The Call for Proposals on Audio Coding for Machines (ACoM), issued by the MPEG audio coding working group, aims to develop a standard for efficiently compressing audio, multi-dimensional signals (e.g., medical data), or extracted features for use in machine-driven applications. The standard targets use cases such as connected vehicles, audio surveillance, diagnostics, health monitoring, and smart cities, where vast data streams must be transmitted, stored, and processed with low latency and high fidelity. The ACoM system is designed in two phases: the first focusing on near-lossless compression of audio and metadata to facilitate training of machine learning models, and the second expanding to lossy compression of features optimized for specific applications. The goal is to support hybrid consumption – by machines and, where needed, humans – while ensuring interoperability, low delay, and efficient use of storage and bandwidth.
The CfP outlines technical requirements, submission guidelines, and evaluation metrics. Participants must provide decoders compatible with Linux/x86 systems, demonstrate performance through objective metrics like compression ratio, encoder/decoder runtime, and memory usage, and undergo a mandatory cross-checking process. Selected proposals will contribute to a reference model and working draft of the standard. Proponents must register by August 1, 2025, with submissions due in September, and evaluation taking place in October. The selection process emphasizes lossless reproduction, metadata fidelity, and significant improvements over a baseline codec, with a path to merge top-performing technologies into a unified solution for standardization.
Research aspects of Audio Coding for Machines (ACoM) include developing efficient compression techniques for audio and multi-dimensional data that preserve key features for machine learning tasks, optimizing encoding for low-latency and resource-constrained environments, and designing hybrid formats suitable for both machine and human consumption. Additional research areas involve creating interoperable feature representations, enhancing metadata handling for context-aware processing, evaluating trade-offs between lossless and lossy compression, and integrating machine-optimized codecs into real-world applications like surveillance, diagnostics, and smart systems.
The MPEG video coding working group approved the committee draft (CD) for ISO/IEC 23888-2 video coding for machines (VCM). VCM aims to encode visual content in a way that maximizes machine task performance, such as computer vision, scene understanding, autonomous driving, smart surveillance, robotics and IoT. Instead of preserving photorealistic quality, VCM seeks to retain features and structures important for machines, possibly at much lower bitrates than traditional video codecs. The CD introduces several new tools and enhancements aimed at improving machine-centric video processing efficiency. These include updates to spatial resampling, such as the signaling of the inner decoded picture size to better support scalable inference. For temporal resampling, the CD enables adaptive resampling ratios and introduces pre- and post-filters within the temporal resampler to maintain task-relevant temporal features. In the filtering domain, it adopts bit depth truncation techniques – integrating bit depth shifting, luma enhancement, and chroma reconstruction – to optimize both signaling efficiency and cross-platform interoperability. Luma enhancement is further refined through an integer-based implementation for luma distribution parameters, while chroma reconstruction is stabilized across different hardware platforms. Additionally, the CD proposes removing the neural network-based in-loop filter (NNLF) to simplify the pipeline. Finally, in terms of bitstream structure, it adopts a flattened structure with new signaling methods to support efficient random access and better coordination with system layers, aligning with the low-latency, high-accuracy needs of machine-driven applications.
Research in VCM focuses on optimizing video representation for downstream machine tasks, exploring task-driven compression techniques that prioritize inference accuracy over perceptual quality. Key areas include joint video and feature coding, adaptive resampling methods tailored to machine perception, learning-based filter design, and bitstream structuring for efficient decoding and random access. Other important directions involve balancing bitrate and task accuracy, enhancing robustness across platforms, and integrating machine-in-the-loop optimization to co-design codecs with AI inference pipelines.
Concluding Remarks
The 150th MPEG meeting marks significant progress across AI-enhanced media, immersive technologies, and machine-oriented coding. With ongoing work on MPEG-AI, metaverse standards, next-gen video compression, Gaussian splat representation, and machine-friendly audio and video coding, MPEG continues to shape the future of interoperable, intelligent, and adaptive multimedia systems. The research opportunities and standardization efforts outlined in this meeting provide a strong foundation for innovations that support real-time, efficient, and cross-platform media experiences for both human and machine consumption.
The 151st MPEG meeting will be held in Daejeon, Korea, from 30 June to 04 July 2025. Click here for more information about MPEG meetings and their developments.
Once upon a time, when engineers measured networks in latency and packet loss, the idea of Quality of Experience (QoE) emerged — a myth whispered among researchers who dared to ask not what the system delivers, but what the user perceives. Decades later, QoE has evolved into a sprawling epic, spanning disciplines and domains, from humble MOS scores to immersive virtual realities. But as media experiences become ever more complex — adaptive, interactive, personalized — the question lingers: O QoE, where art thou?
1. Introduction
In this column, we revisit the notion of QoE and its evolution over time. We begin by reviewing early work from the 1990s to 2000s on the definitions of QoE (Section 2), where researchers first recognized the importance of user perception and the relevant QoE influence factors, as well as QoE modeling efforts. As a summary of this literature survey, QoE evolved from abstract notions of perception and satisfaction to a measurable, standardized concept encompassing the emotional, cognitive, and contextual responses of users to a service or application. The trends across time are:
1990s: Early focus on perception and interaction design.
Early 2000s: Growing focus on subjectivity, emotion, and context in user experience. QoE separated from QoS, emphasizing emotion, context, and expectation. Seen as key to commercial and user success.
Mid-2000s: Integration of technical and perceptual layers; need for metrics and quantification. Push for measurable models combining technical and user perspectives. Recognition of multiple definitions across domains.
Late 2000s–2010s: Standardization, recognition of multi-dimensionality, and development of cross-disciplinary definitions. QoE defined around subjective perception and system-wide impact.
2010s: Unified, multidisciplinary understanding established through initiatives like QUALINET; QoE as “delight or annoyance”.
This initial insight laid the foundation for larger initiatives like QUALINET, which helped to shape the field by providing widely accepted QoE definitions. We then examine how these developments have been formalized through standardization activities (Section 3), particularly within the ITU and the QUALINET whitepapers on the definition of QoE and immersive QoE.
The diverse and often conflicting definitions of QoE emerging in the 2000s highlighted the need for coordinated efforts and shared understanding across disciplines. This led to joint initiatives like QUALINET, which aimed to formalize and unify QoE research within a dedicated network. One of the results is the updated QoE definition, which is now taken in standardization.
2016: ITU-T Recommendation P.10/G.100 (2006) Amendment 5 (07/ 16), New Definitions for Inclusion in Recommendation ITU-T P.10/G.100, International Telecommunication Union, July 2016. ‘‘Quality of experience (QoE) is the degree of delight or annoyance of the user of an application or service’’.
Figure 1. Timeline on the notion and definitions of QoE in literature and standardization.
A timeline of the literature survey and the early definitions of QoE as well as the standardization activities is visualized in Figure 1. Finally, we discuss selected open issues in QoE research (Section 4) that continue to challenge both academia and industry.
2. Early Definitions of QoE: 1990s to 2000s
The term Quality of Experience (QoE) emerged in the late 1990s to early 2000s as a response to the limitations of traditional network-centric approaches. Although Quality of Service (QoS) had already been formally defined in ITU-T Recommendation E.800 (1994) [ITU-T E.800] for telephony and established a basis for assessing service quality from both technical and user viewpoints, QoS primarily addresses performance at the network level. QoS is commonly applied within communication networks to describe a system’s ability to meet predefined performance targets, ensuring consistent data transmission through metrics such as bandwidth, latency, jitter, and packet loss [Varela2014].
In contrast, researchers and industry practitioners began to recognize the importance of how users actually perceive the quality of a service in the late 1990s to early 2000s. In this context, a variety of alternative terms were used prior to the standardization and definition of QoE, including User-Perceived Quality, Perceived Quality, End-User Quality, User-Experience Quality, Multimedia Experience Quality, Subjective Quality of Service, and user-level QoS. These early terms reflected a growing awareness of the need to evaluate digital services from the user’s point of view, ultimately leading to the coining and adoption of QoE as a distinct and essential concept in the field of communication systems and multimedia applications.
The term QoE brought attention to the user’s subjective perception, marking a shift toward evaluating service quality from the end-user’s perspective in the mid of 2000s. In the following, a brief overview on first documents about “Quality of Experience” or “QoE” are provided to sketch the definition of terms. In particular, research articles from the ACM Digital Library and IEEE Xplore searching for “Quality of Experience” or “QoE” are collected.
Focus on user perception and interaction design
1990: Harman, G. “The intrinsic quality of experience.“ laims we’re not directly aware of our experiences’ intrinsic properties, but of those of the external objects they represent—like color, shape, texture, motion, and spatial relations.
1996: Austin Henderson. “What’s next?” explains the idea behind the ACM Award about QoE in interaction. “We really want to know what users experience! In short we are interested in the quality of a person’s experience in the interaction. […] factors contribute to the effective experience of interacting with the device.“ However, no QoE definition is proposed.
1996: Lauralee Alben. “Quality of experience: defining the criteria for effective interaction design“ is also related to the ACM interactions design award. “By ‘experience’ we mean all the aspects of how people use an interactive product: the way it feels in their hands, how well they understand how it works, how they feel about it while they’re using it, how well it serves their purposes, and how well it fits into the entire context in which they are using it. If these experiences are successful and engaging, then they are valuable to users and noteworthy to the interaction design awards jury. We call this ‘quality of experience’.” This early definition of QoE encompasses all aspects of a user’s interaction with a product, including its physical feel, usability, emotional impact, and the overall satisfaction derived from its use.
2000: Alan Turner and Lucy T. Nowell. “Beyond the desktop: diversity and artistry” relate QoE to the need for engaging, media-rich interactions across diverse devices, emphasizing the role of artistry in delivering compelling user experiences. A remarkable statement: “We also believe that the quality of experience will become the key metric of success for software, both commercially and socially.“
Focus on subjectivity, emotion, and context
2000: Marion Buchenau and Jane Fulton Suri. “Experience prototyping.” introduce a prototyping approach that immerses users in simulated interactions to explore and refine QoE, including sensory, emotional, and contextual dimensions beyond usability or function. QoE goes beyond usability or functionality, encompassing emotional and contextual factors.
2000: Anna Bouch, Allan Kuchinsky, and Nina Bhatti. “Quality is in the eye of the beholder: meeting users’ requirements for Internet quality of service.” They show that in Internet commerce, QoE depends on both technical QoS as well as user expectations and context. “Only through such integration of users’ requirements into systems design [of users’ requirements into systems design] will it be possible to achieve the customer satisfaction that leads to the success of any commercial system.”
2001: Public slide set by Touradj Ebrahimi (2012) “Quality of Experience Past, Present and Future Trends”, presented 23 Nov 2012, refers to a definition of QoE as follows. “The degree of fulfillment of an intended experience on a given user – as defined by Touradj Ebrahimi, 2001”.
2002: Heddaya, A. S. “An economically scalable Internet” uses the term “QoE rather than quality of service because QoS is not necessary for QoE, and QoE is sufficient for successful service.”
Focus on measurable models combining technical and user perspectives
1994: Nahrstedt, K., & Smith, J., Ralf Steinmetz. “Mapping User Level QoS from a Single Parameter” aims at quantifying QoE. “The ‘satisfaction’ concept has been introduced to quantify the QoS provided by the system. The transformations required to both map the cost into satisfaction and then configure the system are then developed.”
2003: Siller, M., & Woods, J. C. “QoS arbitration for improving the QoE in multimedia transmission.” propose a QoE-aware framework that adapts QoS to real-time user perception for multimedia networks. They define QoE as “the user’s perceived experience of what is being presented by the Application Layer, where the application layer acts as a user interface front-end that presents the overall result of the individual Quality of Services”. They also review current related work at that time, which are taken from white papers, which are not accessible anymore:
“A metric used for measuring the performance of this perceptual layer is Quality of Experience (QoE).”
“QoE is referred to as; what a customer experiences and values to complete his tasks quickly and with confidence.”
“QoE is considered as all the perception elements of the network and performance relative to expectations of the users/subscribers.“
The QoE is defined as “the totality of the Quality of Service mechanisms, provided to ensure smooth transmission of audio and video over IP networks”.
2004: R. Jain. “Quality of Experience” asks the following questions. “But how do we quantitatively define the quality of experience? Can we extend QoS to QoE? What factors should we consider in developing measures for QoE?” He concludes with a remarkable statement. “In a sense, the challenges of QoE are nothing new. People in social sciences and marketing have always developed techniques to quantify people’s preferences and choices. That situation is similar to what goes into QoE.”
2004: Euro-NGI D.JRA.6.1.1 “State-of-the-art with regards to user-perceived Quality of Service and quality feedback” with Fiedler as lead for this deliverable reviews QoS from the user’s perspective. The notion of QoE is “The degree of satisfaction, i.e. the subjective quality, is influenced by the technical, objective quality stemming from the application and the interconnecting network(s). For this reason, subjective quality as perceived by the network has to be linked to objective, measurable quality, which is expressed in application and network performance parameters. “
2007: Hoßfeld, Tobias, Phuoc Tran-Gia, and Markus Fiedler. “Quantification of quality of experience for edge-based applications” provide a quantitative link between technical metrics and QoE. “Quality of Experience (QoE), a subjective measure from the user perspective of the overall value of the provided service or application”.
Diversity of definitions and interdisciplinarity
2007: Soldani, D., Li, M., & Cuny, R. “QoS and QoE management in UMTS cellular systems” define: “QoE is the term used to describe the perception of end-users on how usable the services are. […] The term ‘QoE’ refers to the perception of the user about the quality of a particular service or networks.” Notably, they already mentioned that “Browsing through the literature, one may find many different definitions for quality of end-user experience (QoE) and quality of service (QoS).”
2009: International Conference on Quality of Multimedia Experience (QoMEX) includes in the call for papers: “perceived user experience is psychological in nature and changes in different environmental conditions and with different multimedia devices.”
3. Definitions of QoE in Standardization
In standardization, the following definitions were introduced.
2007: ITU-T Rec. G.100/P.10 Amendment 1 (2007) New Appendix I – Definition of Quality of Experience (QoE). “The overall acceptability of an application or service, as perceived subjectively by the end user. NOTE 1: Quality of experience includes the complete end-to-end system effects (client, terminal, network, services infrastructure, etc.). NOTE 2: Overall acceptability may be influenced by user expectations and context.” This definition has been superseded by the Qualinet Definition of QoE in 2016. It should be mentioned that acceptance and QoE are different concepts. acceptability refers more narrowly to whether a service or system is deemed “good enough” or usable under certain conditions. Approaches to link QoE and acceptance have been discussed in literature [Schatz2011,Hossfeld2016].
2008: ITU-T Recommendation E.800. “Definitions of terms related to quality of service” defines in as follows: “quality of service experienced/perceived by customer/user (QoSE): a statement expressing the level of quality that customers/users believe they have experienced. NOTE 1: The level of QoS experienced and/or perceived by the customer/user may be expressed by an opinion rating.”
2009: ETSI TR 102 643 V1.0.1 (2009-12) “Human Factors (HF); Quality of Experience (QoE) requirements for real-time communication services” defines QoE as “measure of user performance based on both objective and subjective psychological measures of using an ICT service or product”. It includes two notes on QoE: (1) Considers technical QoS, context, and measures both communication process and outcomes (e.g. effectiveness, satisfaction). (2) Uses objective (e.g. task time, errors) and subjective (e.g. perceived quality, satisfaction) psychological measures, depending on context.
The diverse and often conflicting definitions of QoE emerging in the 2000s highlighted the need for coordinated efforts and shared understanding across disciplines. This led to joint initiatives like QUALINET, which aimed to formalize and unify QoE research within a dedicated network. One of the results is the updated QoE definition, which is now taken in standardization.
2016: ITU-T Recommendation P.10/G.100 (2006) Amendment 5 (07/ 16), New Definitions for Inclusion in Recommendation ITU-T P.10/G.100, International Telecommunication Union, July 2016: ‘‘Quality of experience (QoE) is the degree of delight or annoyance of the user of an application or service’’.
QUALINET White Paper on Definitions of Quality of Experience
QUALINET is the European Network on Quality of Experience in Multimedia Systems and Service (COST Action IC 1003 from 2010 to 2014, later a network that meets regularly at QoMEX) with the aim to “to establish a strong network on Quality of Experience (QoE) with participation from both academia and industry” (https://www.cost.eu/actions/IC1003/). QUALINET was the driving force to further advance research in the context of QoE, producing three major, well-cited assets (among others), namely (1) QUALINET White Paper on Definitions of Quality of Experience, (2) QUALINET databases [QUALINET2019], and (3) QUALINET White Paper on Definitions of Immersive Media Experience (IMEx)
The white paper on definitions of QoE was the result from a consultation and collaborative writing process within the COST Action IC 1003 of 38 authors, contributors, and editors from 18 countries. A first draft was discussed and improved at the 2012 QoE Dagstuhl Seminar [Fiedler2012]. The final definition of QoE:
“Quality of Experience (QoE) is the degree of delight or annoyance of the user of an application or service. It results from the fulfillment of his or her expectations with respect to the utility and / or enjoyment of the application or service in the light of the user’s personality and current state.”
The white paper also defines influence factors (human, system, context) and features of QoE (level of direct perception, level of interaction, level of the usage situation, level of service) as well as the relationship between QoS and QoE, plus application areas, which allow “to provide specializations of a generally agreed definition of QoE pertaining to the respective application domain taking into account its requirements formulated by means of influence factors and features of QoE”.
QUALINET White Paper on Definitions of Immersive Media Experience (IMEx)
A follow-up white paper defines the QoE for immersive media as
“the degree of delight or annoyance of the user of an application or service which involves an immersive media experience. It results from the fulfillment of his or her expectations with respect to the utility and/or enjoyment of the application or service in the light of the user’s personality and current state.”
“a high-fidelity simulation provided and communicated to the user through multiple sensory and semiotic modalities. Users are emplaced in a technology-driven environment with the possibility to actively partake and participate in the information and experiences dispensed by the generated world.”
Consequently, this white paper provides a “toolbox for definitions of IMEx including its Quality of Experience, application areas, influencing factors, and assessment methods.”[QUALINET2020].
4. Open Issues in QoE Research
We would like to conclude with some open issues regarding Quality of Experience. The upcoming 6G standard presents significant opportunities, such as QoE-aware orchestration of edge computing, cloud rendering, and network slicing [Tondwalkar2024] and native AI in 6G [Ziegler2020], while also considering tradeoff between QoE and CO2 emissions [Hossfeld2023]. As AI-generated content continues to rise, the evaluation of its quality remains in its early stages. The same applies to learning-based codecs, where existing quality assessment methods—both objective and subjective—are reaching their limits, particularly concerning media authenticity, which is becoming a critical issue. In this context, ethics and privacy are paramount, as user data plays a central role in QoE modeling. Future research must focus on privacy-preserving methods for QoE measurement and personalization. Finally, new modalities such as point clouds, light fields, and holograms necessitate the adaptation of existing techniques or the development of new methods. Moreover, multimodal or multisensory QoE, particularly concerning audio-visual-haptic or olfactory integration (previously referred to as Mulsemedia), is emerging as an important area that requires tailored QoE assessment methods and metrics. This is also reflected by the upcoming 17th Int. Conf. on Quality of Multimedia Experiences (QoMEX’25) under the theme “Thinking of a QoE ®evolultion”. In particular, the call for papers requests: “On the edge of QoMEX ‘coming of age’, it is time to rethink the purpose and methods of QoE research: cross-fertilizing with adjacent fields, reaching more diverse populations, or exploring novel techniques and paradigms.” This addresses innovative approaches and novel paradigms in QoE research, technological innovations in the era of big data data and AI, but also on user-centricity in 6G. Interdisciplinary links in QoE include diversity, ethics, accessibility, but also novel interaction techniques and multimedia experiences. Specific applications such as gaming, healthcare, education, and immersive technologies, and multisensory perception are in the scope.
And so, like any true odyssey, the search for Quality of Experience continues — not as a destination, but as a path we shape with every interaction, every pixel tuned, every user understood. QoE is no longer a myth, but neither is it fully found. It lives at the intersection of perception and precision, where engineers meet psychologists, and systems learn to listen. In a world of immersive media and intelligent networks, perhaps the better question is no longer “O QoE, where art thou?” but rather — “Are we ready to meet it where it truly resides?”
[Bouch2000]: Anna Bouch, Allan Kuchinsky, and Nina Bhatti. 2000. Quality is in the eye of the beholder: meeting users’ requirements for Internet quality of service. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems (CHI ’00). Association for Computing Machinery, New York, NY, USA, 297–304. https://doi.org/10.1145/332040.332447
[Buchenau2000] Marion Buchenau and Jane Fulton Suri. 2000. Experience prototyping. In Proceedings of the 3rd conference on Designing interactive systems: processes, practices, methods, and techniques (DIS ’00). Association for Computing Machinery, New York, NY, USA, 424–433. https://doi.org/10.1145/347642.347802
[Ebrahimi2001] Public slide set by Touradj Ebrahimi (2012) “Quality of Experience Past, Present and Future Trends”, presented at Alpen-Adria-Universität Klagenfurt, 23 Nov 2012
ETSI TR 102 643 V1.0.1 (2009-12) “Human Factors (HF); Quality of Experience (QoE) requirements for real-time communication services”
[EuroNGI2004] Euro-NGI D.JRA.6.1.1 : State-of-the-art with regards to user-perceived Quality of Service and quality feedback, Deliverable version No: 1.0 Sending date: 31/05-2004, Lead: Markus Fiedler, BTH Karlskrona. <a href=”https://www.diva-portal.org/smash/get/diva2:837296/FULLTEXT01.pdf”>Last accessed: 2025/04/22</a>
[Fiedler2012] Markus Fiedler, Sebastian Möller, and Peter Reichl. Quality of Experience: From User Perception to Instrumental Metrics (Dagstuhl Seminar 12181). In Dagstuhl Reports, Volume 2, Issue 5, pp. 1-25, Schloss Dagstuhl – Leibniz-Zentrum für Informatik (2012) https://doi.org/10.4230/DagRep.2.5.1
[Hestnes2009] Hestnes, B., Brooks, P., Heiestad, S. (2009). “QoE (Quality of Experience) – measuring QoE for improving the usage of telecommunication services”, Telenor R&I R 21/2009.
[Hossfeld2007] Hoßfeld, Tobias, Phuoc Tran-Gia, and Markus Fiedler. “Quantification of quality of experience for edge-based applications.” International Teletraffic Congress. Berlin, Heidelberg: Springer Berlin Heidelberg, 2007. https://doi.org/10.1007/978-3-540-72990-7_34
[Hossfeld2016] Hoßfeld, T., Heegaard, P. E., Varela, M., & Möller, S. (2016). QoE beyond the MOS: an in-depth look at QoE via better metrics and their relation to MOS. Quality and User Experience, 1, 1-23. https://doi.org/10.1007/s41233-016-0002-1
[Hossfeld2023] Hoßfeld, T., Varela, M., Skorin-Kapov, L., & Heegaard, P. E. (2023). A Greener Experience: Trade-Offs between QoE and CO 2 Emissions in Today’s and 6G Networks. IEEE communications magazine, 61(9), 178-184. https://doi.org/10.1109/MCOM.006.2200490
[ITU-T E.800] E.800: Terms and definitions related to quality of service and network performance including dependability”. ITU-T Recommendation. August 1994. Updated September 2008 as Definitions of terms related to quality of service. Last access: 2025/04/22
[ITU-T G.100/P.10 2007] ITU-T Rec. G.100/P.10 Amendment 1 (2007) New Appendix I—Definition of Quality of Experience (QoE). International Telecommunication Union, Geneva.
[Nahrstedt1994] Nahrstedt, K., & Smith, J., Ralf Steinmetz (Ed), 1994, “Service Kernel for Multimedia Endpoints”, Multimedia: Advanced Teleservices and High-speed Communication Architectures, Lecture Notes in Computer Science LNCS868, chanter I, pp. 8-22, Springer Verlag. https://doi.org/10.1007/3-540-58494-3_2
[QUALINET2013] Patrick Le Callet, Sebastian Möller and Andrew Perkis, eds., Qualinet White Paper on Definitions of Quality of Experience (2012). European Network on Quality of Experience in Multimedia Systems and Services (COST Action IC 1003) Lausanne, Switzerland, Version 1.2, March 2013. Last access: 2025/04/22
[QUALINET2019] Karel Fliegel, Lukáš Krasula, and Werner Robitza. 2022. Qualinet databases: central resource for QoE research – history, current status, and plans. SIGMultimedia Rec. 11, 3, Article 5 (September 2019), 1 pages. https://doi.org/10.1145/3524460.3524465
[QUALINET2020] Perkis, A., Timmerer, C., et al., “QUALINET White Paper on Definitions of Immersive Media Experience (IMEx)”, European Network on Quality of Experience in Multimedia Systems and Services, 14th QUALINET meeting (online), May 25, 2020. https://arxiv.org/abs/2007.07032
[Richards1998] Richards, A., Rogers, G., Witana, V., & Antoniades, M., 1998, “Mapping User Level QoS from a Single Parameter”, In Proceedings of the International Conference on MultimediaNetworks and Services (MMNS ‘98).
[Schatz2011] Schatz, R., Egger, S., & Platzer, A. (2011, June). Poor, good enough or even better? bridging the gap between acceptability and qoe of mobile broadband data services. In 2011 IEEE International Conference on Communications (ICC) (pp. 1-6). IEEE. https://doi.org/10.1109/icc.2011.5963220
[Siller2003] Siller, M., & Woods, J. C. (2003, July). QoS arbitration for improving the QoE in multimedia transmission. In International Conference on Visual Information Engineering (VIE 2003). Ideas, Applications, Experience (pp. 238-241). London UK: IEE. https://doi.org/10.1049/cp:20030531
[Tondwalkar2024] Tondwalkar, A., Andres-Maldonado, P., Chandramouli, D., Liebhart, R., Moya, F. S., Kolding, T., & Perez, P. (2024). Provisioning Quality of Experience in 6G Networks. IEEE Access. https://doi.org/10.1109/ACCESS.2024.3455938
[Turner2000] Alan Turner and Lucy T. Nowell. 2000. Beyond the desktop: diversity and artistry. In CHI ’00 Extended Abstracts on Human Factors in Computing Systems (CHI EA ’00). Association for Computing Machinery, New York, NY, USA, 35–36. https://doi.org/10.1145/633292.633317
[Varela2014] Varela, M., Skorin-Kapov, L., & Ebrahimi, T. (2014). Quality of service versus quality of experience. In Quality of Experience: Advanced Concepts, Applications and Methods (pp. 85-96). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-02681-7_6