Multimedia research is framed through
algorithms, datasets, and systems, but at its heart lies content that is deeply
human. Few forms of content illustrate this better than classical music. Long
before music becomes data to be recorded, generated, searched, or retrieved, it
is imagined by composers and brought to life by performers. At ACM Multimedia
2025 in Dublin, this human origin of multimedia took centre stage in a unique
social event that bridged classical music and multimedia content analysis. This
event was the fourth supported by ACM SIGMM in the framework of Music Meets
Science program (at CBMI’2022, CBMI’2023, CBMI’2024).
Music Meets Science explores musical spaces
across centuries and styles, from the dynamic Folia of Vivaldi and Handel’s
Passacaglia to works by Schubert and contemporary composers from around the
world. The goal here is to bring a wide range of music performed by some of the
original content creators, our classical musicians, to the multimedia research
community, who explore and mine this content. It brings fundamental cultural
values to the young researchers in Multimedia, opening their minds to classical
and contemporary music which oscillates with the rhythm of centuries.
The concert took place on 29 October, starting at 8:00 PM, during the Welcome Reception of ACM Multimedia 2025. It was attended by over 1,000 delegates of all ages from doctoral students to senior researchers. The programme featured music by Irish composer Garth Knox and a new composition by Finnish composer Jarno Vanhanen, written especially for ACM Multimedia. The performance was delivered by internationally acclaimed French musicians of the new generation: François Pineau-Benois (violin) and Olivier Marin (viola), see Figure 1. Together, they invited the audience to experience music not only as sound, but as rich multimedia content shaped by structure, expression, interpretation, and context.
Figure 1. François Pineau-Benois (violin), Oliver Marin (viola) performing Jarno Vanhanen’s “Aurora Borealis” duet.
By embedding live performance within a
major multimedia conference, Music Meets Science highlights the importance of
integrating creative arts into the research ecosystem. As multimedia research
continues to advance, from content understanding to generation, events like
this remind us that artistic practice is not just an application domain, but a
source of inspiration. Strengthening the dialogue between creative arts and
multimedia research can deepen our understanding of content, context, and
meaning, and enrich the future directions of the field.
We would like to begin by sincerely thanking the SIGMM community for
the trust you have placed in us. We are honored to serve as Chairs alongside a
talented and dedicated team. A special thanks goes to the previous Executive
Committee for their outstanding work during challenging times and for laying
down a solid foundation for the future.
We are at an exciting juncture. Multimedia is no longer just a
field, it is the connective tissue of modern life. From intelligent
communication and immersive experiences to AI-generated content and digital
twins, multimedia systems are shaping how we learn, work, and connect. Our
community is uniquely positioned to lead in this space.
Over the next two years, we want to focus on presence — not only in
terms of emerging technologies, but also in how SIGMM can be present for
researchers around the world. Together, we will:
Champion young researchers and
amplify their voices.
Promote open science by
supporting the sharing of code, data, and reproducible research.
Increase industry engagement by
creating meaningful bridges between academia and application.
Strengthen our global presence
through active local chapters and outreach.
Ensure SIGMM remains a space
that is inclusive, diverse, and equitable, a community where everyone feels
welcome and empowered.
Position SIGMM conferences
and journals as the leading venue for applied AI in multimodal systems and showcasing how sensing, understanding, generation, and
interaction converge to solve real-world challenges.
Let us continue to work together and to make an impact, inspired by the richness of multimedia research and united by a shared commitment to excellence and openness.
Abdulmotaleb, Elisa and Silvia
Abdulmotaleb El Saddik is an award-winning technologist and Distinguished Professor whose
leadership in Embodied AI, Digital Twins, and Mixed Reality bridges innovation,
mentorship, and human impact.
Elisa Ricci
is a Professor at University of Trento and Senior researcher at Fondazione
Bruno Kessler in Italy. Her research interests include computer vision and
multimedia analysis.
Silvia Rossi is a senior scientist at Centrum Wiskunde & Informatica (CWI) in
The Netherlands. Her research interests are at the intersection of multimedia
systems, artificial intelligence, and user behaviour modelling for immersive
and interactive systems.
The Benchmarking Initiative for Multimedia Evaluation (MediaEval) organizes interesting and engaging tasks related to multimedia data. MediaEval is proud to be supported by SIGMM. Tasks involve analyzing and exploring multimedia collections, as well as accessing the information that they contain. MediaEval emphasizes challenges that have a human or social aspect in order to support our goal of making multimedia a positive force in society. Participants in MediaEval are encouraged to submit effective, but also creative solutions to MediaEval tasks: We carry out quantitative evaluation of the submissions, but also go beyond the scores in order to obtain insight into the tasks, data, metrics.
Participation in MediaEval is open to any team that wishes to sign up. Registration has just opened and information is available on the MediaEval 2026 website: https://multimediaeval.github.io/editions/2026 The workshop will take place in Amsterdam, Netherlands and online coordinated with ACM ICMR https://icmr2026.org
In this column, we present a short report on MediaEval 2025, which culminated with the annual workshop in Dublin, Ireland between CBMI (https://www.cbmi2025.org) and ACM Multimedia (https://acmmm2025.org). Then, we provide an outlook to MediaEval 2026, which will be the sixteenth edition of MediaEval.
A Keynote on Metascience
The workshop kicked off with a keynote on metascience for machine learning. The metascience initiative (https://metascienceforml.github.io) strives to promote discussion and development of the scientific underpinnings of machine learning. It looks at the way in which machine learning is done and examines the full range of relevant aspects, from methodologies and mindsets. The keynote was delivered by Jan van Gemert, head of the Computer Vision Lab (https://www.tudelft.nl/ewi/over-de-faculteit/afdelingen/intelligent-systems/pattern-recognition-bioinformatics/computer-vision-lab) at Delft University of Technology. He discussed the “growing pains” of the field of deep learning and the importance of the scientific method for keeping the field on course. He invited the audience to consider the question of the power of benchmarks for hypothesis-driven science in machine learning and deep learning.
Tasks at MediaEval 2025
The MediaEval 2025tasks reflect the benchmark’s continued emphasis on human-centered and socially relevant multimedia challenges, spanning healthcare, media, memory, and responsible use of generative AI.
Several tasks this year focused on the human aspects of multimodal analysis, combining visual, textual, and physiological signals. The Medico Task challenges participants in building visual question answering models for the interpretation of gastrointestinal images, aiming to support clinical decision-making through interpretable multimodal explanations. The MemorabilityTask focuses on modeling long-term memory for short movie excerpts and commercial videos, requiring participants to predict how memorable a video is, whether viewers are familiar with it, and, in some cases, to leverage EEG signals alongside visual features. Multimodal understanding is further explored in the MultiSummTask, where participants are provided with collections of multimodal web content describing food sharing initiatives in different cities and are asked to generate summaries that satisfy specific informational criteria, with evaluation exploring both traditional and emerging LLM-based assessment approaches.
The remaining two tasks emphasize the societal impact of multimedia technology in real-world settings. In the NewsImagesTask, participants worked with large collections of international news articles and images, either retrieving suitable thumbnail images or generating thumbnails for articles. The Synthetic Images Task addressed the growing prevalence of AI-generated content online, asking participants to detect synthetic or manipulated images and localize manipulated areas. The task used data created by state-of-the-art generative models as well as images collected from real-world online settings. We gratefully acknowledge the support of AI-CODE (https://aicode-project.eu), a European project focused on topics related to these two tasks.
MediaEval in Motion
MediaEval is especially proud of participants who return over the years, improving their approaches and contributing insights. We would like to highlight two previous participants who became so interested and involved in MediaEval tasks that they decided to join the task organization team and help organize the tasks. Iván Martín-Fernández, PhD student at Universidad Politécnica de Madrid, became a task organizer for the Memorability task and Lucien Heitz, PhD Student, University of Zurich, became a task organizer for NewsImages.
One aspect of the MediaEval Benchmark I value most is its effort to go beyond metric-chasing and embark on a “quest for insights,” as the organizers put it, to help us better understand the tasks and encourage creative, innovative solutions. This spirit motivated me to participate in the 2023 Memorability Task in Amsterdam. The experience was so enriching that I wanted to become more involved in the community. In 2025, I was invited to join the Memorability Task organizing team, which gave me the chance to contribute to and help foster this innovative research effort. Thanks to SIGMM’s sponsorship, I was able to attend the event in Dublin, which further enhanced the experience. Working alongside Martha and Gabi as a student volunteer is always a pleasure. As my PhD studies come to an end, I’m proud to say that MediaEval has been a core part of my research, and I’m sure it will remain so in the immediate future. See you in Amsterdam in June!
Iván Martín-Fernández, PhD Student, GTHAU – Universidad Politécnica de Madrid
I ‘graduated’ from being a participant in the previous NewsImages challenge to now taking over the organization duties of the 2025 iteration of the task. It was an incredible journey and learning experience. Big thank you to the main MediaEval organizers for their tireless support and input for shaping this new task that combines image retrieval and generation. The recent benchmark event presented an amazing platform to share and discuss our research. We got so many great submissions from teams around the globe. I was truly overwhelmed by the feedback. Getting involved with the organization of a challenge task is something I can highly recommend to all participants. It allows you to take on an active role and bring new ideas to the table on what problems to tackle next.
Lucien Heitz, PhD Student, University of Zurich
MediaEval continues its tradition of awarding a “MediaEval Distinctive Mention” to teams that dive deeply into the data, the algorithms, and the evaluation procedure. Going above and beyond in this way makes important contributions to our understanding of the task and how to make meaningful progress. Moving the state of the art forward requires improving the scores on a pre-defined benchmark task such as the tasks offered by MediaEval. However, MediaEval Distinctive Mentions underline the importance of research that does not necessarily improve scores on a given task, but rather makes an overall contribution to knowledge.
We were happy to serve as student volunteers at MediaEval 2025. In addition, we participated as a team in the NewsImage task, contributing to two subtasks, and were honored to receive a Distinctive Mention.
Xiaomeng had previously participated in the same task at MediaEval 2023. Compared to the 2023 edition, she observed notable evolution in both the data and task design. These changes reflect the organizers’ careful consideration of recent advances in modeling techniques as well as the practical applicability of the datasets, which proved to be highly inspiring.
Bram participated in MediaEval for the first time and particularly found the discussions with colleagues about the challenges very rewarding. The NewsImage retrieval subtask additionally got him to learn how to deal with larger datasets.
We tried to incorporate deeper reflections on our results into our presentation. Specifically, we showed how certain types of articles are particularly suited for image generation and identified the news categories where retrieval was most effective.
Xiaomeng Wang and Bram Bakker PhD Students, Data Science – Radboud University
The people whose work is highlighted in this section are grateful to have received support from SIGMM in order to be able to attend the MediaEval workshop in person.
Outlook to MediaEval 2026
The 2025 workshop concluded with participants collaborating with the task organizers to start to develop “benchmark biographies”, which are living documents that describe benchmarking tasks. Combining elements from data sheets and model cards, benchmark biographies document motivation, history, datasets, evaluation protocols, and baseline results to support transparency, reproducibility, and reuse by the broader research community. We plan to continue work on these benchmark biographies as we move toward MediaEval 2026.
Further, in the 2026 edition, we will offer again the tasks that were held in 2025 to provide an opportunity for teams who were not able to participate in 2025. We especially encourage “Quest for Insight” papers that examine characteristics of the data and the task definitions, the strengths and weaknesses of particular types of approaches, observations about the evaluation procedure, and the implications of the task. We look forward to seeing you in Amsterdam for MediaEval and also ACM ICMR. Don’t forget to check out the MediaEval website (https://multimediaeval.github.io) and register your team if you are interested in participating in 2026.
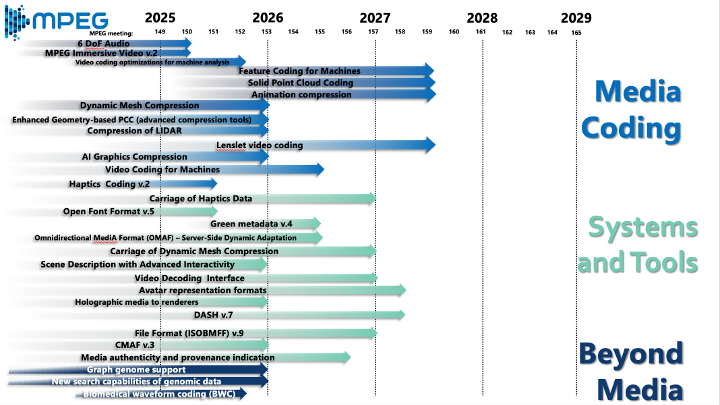
The 153rd MPEG meeting took place online from January 19-23, 2026. The official MPEG press release can be found here. This report highlights key outcomes from the meeting, with a focus on research directions relevant to the ACM SIGMM community:
MPEG Roadmap
Exploration on MPEG Gaussian Splat Coding (GSC)
MPEG Immersive Video 2nd edition (new white paper)
MPEG Roadmap
MPEG released an updated roadmap showing continued convergence of immersive and “beyond video” media with deployment-ready systems work. Near-term priorities include 6DoF experiences (MPEG Immersive Video v2 and 6DoF audio), volumetric representations (dynamic meshes, solid point clouds, LiDAR, and emerging Gaussian splat coding), and “coding for machines,” which treats visual and audio signals as inputs to downstream analytics rather than only for human consumption.
Research aspects: The most promising research opportunities sit at the intersections: renderer and device-aware rate-distortion-complexity optimization for volumetric content; adaptive streaming and packaging evolution (e.g., MPEG-DASH / CMAF) for interactive 6DoF services under tight latency constraints; and cross-cutting themes such as media authenticity and provenance, green and energy metadata, and exploration threads on neural-network-based compression and compression of neural networks that foreshadow AI-native multimedia pipelines.
MPEG Gaussian Splat Coding (GSC)
Gaussian Splat Coding (GSC) is MPEG’s effort to standardize how 3D Gaussian Splatting content, scenes represented as sparse “Gaussian splats” with geometry plus rich attributes (scale and rotation, opacity, and spherical-harmonics appearance for view-dependent rendering), is encoded, decoded, and evaluated so it can be exchanged and rendered consistently across platforms. The main motivation is interoperability for immersive media pipelines: enabling reproducible results, shared benchmarks, and comparable rate-distortion-complexity trade-offs for use cases spanning telepresence and immersive replay to mobile XR and digital twins, while retaining the visual strengths that made 3DGS attractive compared to heavier neural scene representations.
The work remains in an exploration phase, coordinated across ISO/IEC JTC 1/SC 29 groups WG 4 (MPEG Video Coding) and WG 7 (MPEG Coding for 3D Graphics and Haptics) through Joint Exploration Experiments covering datasets and anchors, new coding tools, software (renderer and metrics), and Common Test Conditions (CTC). A notable systems thread is “lightweight GSC” for resource-constrained devices (single-frame, low-latency tracks using geometry-based and video-based pipelines with explicit time and memory targets), alongside an “early deployment” path via amendments to existing MPEG point-cloud codecs to more natively carry Gaussian-splat parameters. In parallel, MPEG is testing whether splat-specific tools can outperform straightforward mappings in quality, bitrate, and compute for real-time and streaming-centric scenarios.
Research aspects: Relevant SIGMM directions include splat-aware compression tools and rate-distortion-complexity optimization (including tracked vs. non-tracked temporal prediction); QoE evaluation for 6DoF navigation (metrics for view and temporal consistency and splat-specific artifacts); decoder and renderer co-design for real-time and mobile lightweight profiles (progressive and LOD-friendly layouts, GPU-friendly decode); and networked delivery problems such as adaptive streaming, ROI and view-dependent transmission, and loss resilience for splat parameters. Additional opportunities include interoperability work on reproducible benchmarking, conformance testing, and practical packaging and signaling for deployment.
MPEG Immersive Video 2nd edition (white paper)
The second edition of MPEG Immersive Video defines an interoperable bitstream and decoding process for efficient 6DoF immersive scene playback, supporting translational and rotational movement with motion parallax to reduce discomfort often associated with pure 3DoF viewing. The second edition primarily extends functionality (without changing the high-level bitstream structure), adding capabilities such as capture-device information, additional projection types, and support for Simple Multi-Plane Image (MPI), alongside tools that better support geometry and attribute handling and depth-related processing.
Architecturally, MIV ingests multiple (unordered) camera views with geometry (depth and occupancy) and attributes (e.g., texture), then reduces inter-view redundancy by extracting patches and packing them into 2D “atlases” that are compressed using conventional video codecs. MIV-specific metadata signals how to reconstruct views from the atlases. The standard is built as an extension of the common Visual Volumetric Video-based Coding (V3C) bitstream framework shared with V-PCC, with profiles that preserve backward compatibility while introducing a new profile for added second-edition functionality and a tailored profile for full-plane MPI delivery.
Research aspects: Key SIGMM topics include systems-efficient 6DoF delivery (better view and patch selection and atlas packing under latency and bandwidth constraints); rate-distortion-complexity-QoE optimization that accounts for decode and render cost (especially on HMD and mobile) and motion-parallax comfort; adaptive delivery strategies (representation ladders, viewport and pose-driven bit allocation, robust packetization and error resilience for atlas video plus metadata); renderer-aware metrics and subjective protocols for multi-view temporal consistency; and deployment-oriented work such as profile and level tuning, codec-group choices (HEVC / VVC), conformance testing, and exploiting second-edition features (capture device info, depth tools, Simple MPI) for more reliable reconstruction and improved user experience.
Concluding Remarks
The meeting outcomes highlight a clear shift toward immersive and AI-enabled media systems where compression, rendering, delivery, and evaluation must be co-designed. These developments offer timely opportunities for the ACM SIGMM community to contribute reproducible benchmarks, perceptual metrics, and end-to-end streaming and systems research that can directly influence emerging standards and deployments.
The 154th MPEG meeting will be held in Santa Eulària, Spain, from April 27 to May 1, 2026. Click here for more information about MPEG meetings and ongoing developments.
[Multimedia systems are evolving towards AI-driven, adaptive services, leading to a natural convergence of QoE and machine intelligence. In this context, machine intelligence can empower QoE through learning-based, context-aware, and semantic-driven modelling and optimization. At the same time, QoE can guide machine intelligence by providing a human-centred objective for AI system design and evaluation; see also [11]. Looking beyond human perception, toward agent-centric and hybrid QoE, future multimedia systems increasingly require unified experience objectives that support human-AI co-experience. QoMEX’26 in Cardiff stands as a major milestone highlighting the convergence of Quality of Multimedia Experience with Machine Intelligence. This column reflects on this evolution and outlines the key challenges ahead.
Multimedia systems have shifted from “best-effort delivery” toward intelligent, adaptive services that operate under highly diverse network conditions, device capabilities, and user contexts. In this landscape, Quality of Experience (QoE) has become a central concept, focusing on user satisfaction rather than purely signal-level fidelity [1, 2, 3].
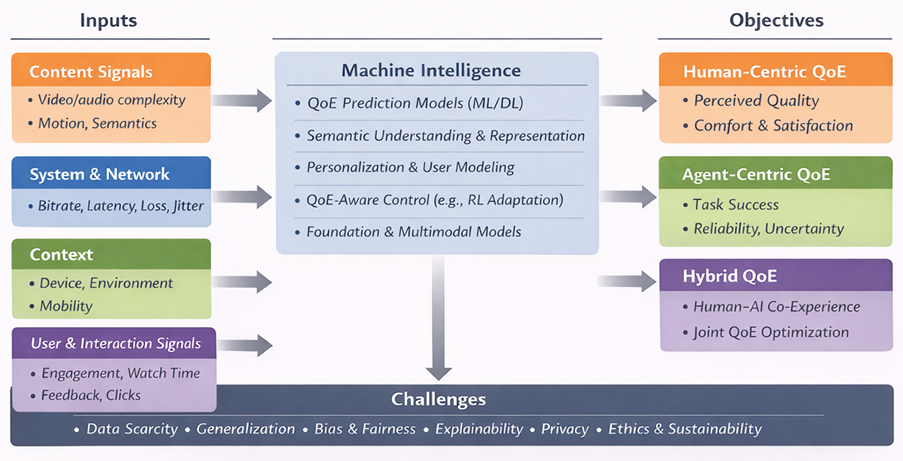
QoE has traditionally been human-centric, reflecting perceived quality, enjoyment, comfort, and acceptance of multimedia services [2]. Meanwhile, machine intelligence, from deep learning and reinforcement learning to multimodal foundation models, has rapidly become the dominant paradigm for perception, generation, and decision-making. The intersection of these trends is timely and inevitable: QoE provides the human-centred goal, while machine intelligence provides scalable tools to model and optimize experience in complex real-world environments. Figure 1 summarizes this bidirectional relationship between QoE and machine intelligence, from multimodal inputs to human-centric, agent-centric, and hybrid QoE objectives.
Figure 1. A conceptual framework where machine intelligence enables QoE prediction and QoE-aware optimization, while QoE evolves from a human-centric notion toward agent-centric and hybrid objectives in intelligent multimedia systems.
2. How
machine intelligence can empower QoE
(1) Learning QoE models beyond handcrafted rules
Classic QoE models often rely on handcrafted features and simplified assumptions linking system parameters (bitrate, delay, resolution) to perceived quality. Machine learning offers a flexible alternative: it can learn complex nonlinear mappings from content, network conditions, and user interaction signals to QoE outcomes. Deep models further enable learning from high-dimensional inputs such as raw video frames, audio signals, and multimodal logs, supporting richer QoE prediction in streaming, immersive media, short-form video, gaming, and interactive communication. In this context, advances in perceptual quality assessment (e.g., full-reference and no-reference IQA/VQA) also provide useful foundations for QoE-related modelling [5, 8, 9].
(2) QoE-aware control and optimization
Machine intelligence is not only about prediction, it can also enable QoE-driven decision-making. Instead of optimizing network metrics alone, systems can adapt encoding, bitrate selection, buffering strategies, or rendering policies to maximize predicted QoE. This direction has been extensively studied in adaptive streaming, where QoE-driven strategies are used to balance bitrate quality and playback stability [4]. Reinforcement learning is particularly promising, where QoE can serve as a reward signal and agents can learn robust policies under uncertainty (e.g., bandwidth fluctuations, user engagement changes) [6, 7].
(3) Personalization and context-awareness
QoE is inherently subjective and
context-dependent. Machine intelligence can support personalization by
incorporating user preferences and context signals such as device type,
mobility, ambient environment, and usage patterns. For example, some users are
more sensitive to rebuffering events, while others prioritize sharpness and
resolution. Context-aware learning enables systems to move beyond
“one-size-fits-all” adaptation.
(4) Semantic
Intelligence
Machine intelligence can empower QoE by shifting quality assessment from perceptual fidelity toward semantic quality. This means how well the meaning and task-relevant information of multimodal content is preserved for both machines and humans. As multimedia data is increasingly consumed by AI systems in applications like autonomous systems and AI-generated content pipelines, traditional perceptual metrics fail to reflect performance and experience because they ignore semantic consistency. Semantic-aware evaluation may enable task-oriented and task-agnostic assessment. By integrating semantic quality assessment, AI can guide compression, transmission, and system design in ways that better align technical performance with downstream task success and user experience.
3. How QoE
can guide machine intelligence
The relationship between QoE and
machine intelligence is bidirectional: QoE can also shape how multimedia AI
systems are designed, trained, and evaluated.
(1) QoE as a human-centric objective function
Many multimedia AI pipelines optimize proxy metrics such as accuracy, PSNR/SSIM, or task performance. However, these do not always align with perceived quality or user satisfaction. QoE provides a principled framework to define what “better” means from the user’s perspective and encourages evaluation beyond technical fidelity [2, 10].
(2) Aligning generative intelligence with user
satisfaction
With the rise of generative AI for
multimedia enhancement and creation, QoE becomes even more critical.
High-quality generation is not only about realism but also about temporal
consistency, comfort, trust, and acceptance in real usage conditions. Integrating
QoE considerations can help steer generative models toward outcomes that users
actually prefer.
Emerging Challenge “QoE of interactive AI systems”
AI evaluation is shifting from pure model accuracy toward experience-based assessment of how humans interact with AI, aligned with frameworks like the EU AI Act. Quality of Experience (QoE) and UX research provide established methods to measure subjective aspects such as trust, transparency, human oversight of the AIS systems, robustness, and satisfaction. Applying QoE methodologies can translate high-level AI principles into measurable experiential dimensions reflecting real-world user understanding and use. This requires new metrics that reflect how users actually understand, trust and operate AI systems in practice. For more details, see [11].
4. Beyond human-centric QoE: toward agent-centric and hybrid
QoE
While QoE has historically focused on
human perception, emerging multimedia systems increasingly serve autonomous
agents such as robots, drones, and intelligent vehicles. In these scenarios,
multimedia is not only consumed by humans but also by machines. This motivates
an extended view of QoE, agent-centric QoE, where “experience” can be
interpreted as the utility of multimedia inputs for decision-making and task
execution.
Agent-centric QoE can be characterized through indicators such as perception reliability, uncertainty reduction, latency sensitivity, safety margins, energy efficiency, and task success rate. Importantly, many future applications involve human–AI co-experience, for example, in teleoperation, remote driving, robot-assisted inspection, and collaborative XR. In such systems, overall quality depends on both human satisfaction and machine performance, motivating unified QoE objectives that jointly optimize human-centric and agent-centric requirements. As shown in Figure 1, future multimedia systems may require unified QoE objectives that jointly optimize human satisfaction and agent utility in human–AI co-experience scenarios.
5. Key challenges
Despite its promise, QoE-meets-AI
research faces several open challenges:
Subjective data cost and scarcity: QoE ground truth often requires user studies and careful experimental design [2, 3].
Generalization: QoE models may struggle across unseen content types, devices, or cultural contexts.
Bias and fairness: QoE datasets may underrepresent certain user groups or contexts, leading to skewed optimization.
Explainability and trust: Black-box QoE predictions can be difficult to interpret and validate in engineering pipelines.
Privacy: Personalization requires user data, raising responsible data usage concerns.
Ethical aspects: Beyond established research ethics procedures, QoE research must increasingly address the broader ethical implications of AI-driven experience optimization, such as fairness, transparency, wellbeing, privacy, and environmental impact, which are essential for truly human-centred technology.
6. Outlook and takeaways
The convergence of Quality of
Experience and machine intelligence represents a major opportunity for the
multimedia community. Machine intelligence offers scalable tools to predict and
optimize QoE in complex environments, while QoE provides a human-centred lens
to guide AI system design toward real user value. Looking forward, QoE may
evolve from a purely human-centric notion to a hybrid experience shared by
humans and intelligent agents, enabling multimedia systems that are not only
technically advanced, but also aligned with what humans and autonomous agents
truly need.
Looking ahead to the continued evolution of the QoMEX conference series, QoMEX’26 in Cardiff represents a key milestone where Quality of Multimedia Experience directly converges with Machine Intelligence. As AI increasingly shapes how multimedia is created, transmitted, and consumed, the conference invites the community to rethink both the goals and methods of QoE research – using AI to enhance user experience, while drawing on QoE insights to build more human-aware, trustworthy, and adaptive intelligent systems. This vision is reflected in special sessions: “SS1: Semantic Quality Assessment for Multi-Modal Intelligent Systems” on semantic quality assessment for multimodal intelligent systems, which extend quality evaluation beyond perceptual fidelity toward meaning and task relevance. The session aims to lay the foundations of multimodal semantic quality assessment, enable semantic-driven compression and transmission, and connect semantic quality evaluation with AI understanding. “SS2: Beyond Quality: Integrating Ethical Dimensions in QoE Research” on integrating ethical dimensions into QoE research, emphasizing fairness, transparency, wellbeing, privacy, and environmental impact, which are essential for truly human-centred technology. This session calls for ethically reflexive, value-sensitive QoE frameworks that incorporate social impact, collective QoE, and inclusive research practices alongside traditional UX measures.
Together, these themes signal a continued broadening of the QoE scope, reaffirming QoMEX as a forum that evolves with emerging technologies while advancing inclusive, responsible, and future-oriented quality research. The 18th International Conference on Quality of Multimedia Experience (QoMEX’26) will take place in Cardiff, United Kingdom, from June 29 to July 3, 2026. Please find more information on the website of QoMEX’26: https://qomex2026.itec.aau.at/
18th International Conference on Quality of Multimedia Experience (QoMEX’26) will take place in Cardiff, United Kingdom, from June 29 to July 3, 2026
Reference
[1] ITU-T Rec. P.10/G.100 (2006), Vocabulary for performance and quality of service.
The ACMSIGMM Multimodal Reasoning
Workshop was held on 8–9 November 2025 at Indian Institute of Technology
Patna (IIT Patna) in Hybrid mode. Organised by Dr. Sriparna Saha, faculty
member of the Department of Computer Science and Engineering, IIT Patna and
supported by ACM SIGMM, the two-day event brought together researchers,
students, and practitioners to discuss the foundations, methods, and
applications of multimodal reasoning and generative intelligence. The workshop
registered 108 participants and featured invited talks, tutorials, and hands-on
sessions by national and international experts. Sessions covered topics ranging
from trustworthy AI, LLM fine-tuning, temporal and multimodal reasoning, to
knowledge-grounded visual question answering and healthcare applications.
Inauguration:
During the inauguration, Dr. Sriparna Saha welcomed
participants and acknowledged the presence and support of Prof. Jimson
Mathew (Dean of Student Affairs, IIT Patna), Prof. Rajiv Ratn Shah (IIIT
Delhi) and all speakers. The organising committee expressed gratitude to
ACM SIGMM for its financial support, which made the workshop possible.
Felicitations were exchanged, and the inauguration concluded with words of
encouragement for active participation and interdisciplinary collaboration.
Session summaries and highlights:
Day 1:
The first day began with an inaugural session
followed by a series of engaging talks and tutorials. Prof. Rajiv Ratn Shah
(Associate Professor, IIIT Delhi, India) delivered the opening talk on “Tackling
Multimodal Challenges with AI: From User Behavior to Content Generation,”
highlighting the role of multimodal data in understanding user behaviour,
enabling AI-driven content generation, and building region-specific
applications such as voice conversion and video dubbing for Indic languages. Prof.
Sriparna Saha (Associate Professor, Department of Computer Science and
Engineering, IIT Patna, India) then presented “Harnessing Generative
Intelligence for Healthcare: Models, Methods, and Evaluations,” discussing
safe, domain-specific AI systems for healthcare, multimodal summarisation for
low-resource languages, and evaluation frameworks like M3Retrieve and
multilingual trust benchmarks. The afternoon sessions featured hands-on
tutorials and technical talks. Ms. Swagata Mukherjee (Research Scholar, IIT
Patna, India) conducted a tutorial on “Advanced Prompting Techniques for
Large Language Models,” covering zero/few-shot prompting, chain-of-thought
reasoning, and iterative refinement strategies. Mr. Rohan Kirti (Research
Scholar, IIT Patna, India) led a tutorial on “Exploring Multimodal
Reasoning: Text & Image Embeddings, Augmentation, and VQA,”
demonstrating text–image fusion using models such as CLIP, VILT, and PaliGemma.
Prof. José G. Moreno (Associate Professor, IRIT, France) presented “Visual
Question Answering about Named Entities with Knowledge-Based Explanation
(ViQuAE),” introducing a benchmark for explainable, knowledge-grounded VQA.
The day concluded with Prof. Chirag Agarwal (Assistant Professor, University
of Virginia, USA) delivering a talk on “Trustworthy AI in the Era of
Frontier Models,” which emphasised fairness, safety, and alignment in
multimodal and LLM systems.
Day 2:
The second day continued with high-level
technical sessions and tutorials. Prof. Ranjeet Ranjan Jha (Assistant
Professor, Department of Mathematics, IIT Patna, India) opened with a talk
on “Bridging Deep Learning and Multimodal Reasoning: Generative AI in
Real-World Contexts,” tracing the evolution of deep learning into
multimodal generative models and discussing ethical and computational
challenges in deployment. Prof. Adam Jatowt (Professor, Department of
Computer Science, University of Innsbruck, Austria) followed with a
presentation on “Analyzing and Improving Temporal Reasoning Capabilities of
Large Language Models,” showcasing benchmarks such as BiTimeBERT,
TempRetriever, and ComplexTempQA, while proposing methods to enhance
time-sensitive reasoning. The final technical session featured Mr. Syed
Ibrahim Ahmad (Research Scholar, IIT Patna, India) conducted a tutorial on “LLM
Fine-Tuning,” which covered PEFT approaches, QLoRA, quantization, and
optimization techniques to fine-tune large models efficiently.
Valedictory session:
The valedictory session marked the formal
close of the workshop. Dr. SriparnaSaha thanked speakers,
participants and the organising team for active engagement across technical
talks and tutorials. Participants shared positive feedback on the depth and
practicality of sessions. Certificates were distributed to attendees. Final
remarks encouraged continued research, collaboration and dissemination of
resources. Dr. Saha reiterated gratitude to ACM SIGMM for financial
support.
Outcomes, observations and suggested actions:
Multimodal reasoning
remains an interdisciplinary challenge that benefits from close collaboration
between multimedia, NLP, and application domain experts.
Trustworthiness, safety,
and evaluation (benchmarks and metrics) are critical for moving multimodal
models from demonstration to practice especially in healthcare and other
high-stakes domains.
Practical methods for model
adaptation (PEFT, quantization) make large models accessible for research
groups with limited compute.
Datasets and retrieval
resources that combine multimodal inputs with external knowledge (as in ViQuAE)
are valuable for advancing explainable VQA and grounded reasoning.
The community should
prioritise regional and language-diverse resources (Indic languages, code-mixed
data) to ensure equitable benefits from multimodal AI.
SIGMM and ACM venues can
play a role in fostering collaborations via special projects, regional
hackathons, grand challenges, and multimodal benchmark initiatives.
Outreach & social media:
The workshop generated significant visibility
on LinkedIn and other professional networks. Photos and session highlights were
widely shared by participants and organisers, acknowledging ACM SIGMM support
and the quality of the technical programme.
Acknowledgements: The organising committee thanks all speakers, attendees, student volunteers, and ACM SIGMM for financial and logistic support that enabled the workshop.
Date: Oct 27 – Oct 31, 2025 Place: Dublin, Ireland General Chairs: Cathal Gurrin, Klaus Schoeffmann, Min Zhang, Adapt Centre & DCU, Klagenfurt University, Tsinghua University
Introduction
The ACM
Multimedia Conference 2025, held in Dublin, Ireland from October 27 to October
31, 2025, continued its tradition as a premier international forum for
researchers, practitioners, and industry experts in the field of multimedia.
This year’s conference marked an exciting return to Europe, bringing the
community together in a city renowned for its rich cultural heritage,
innovation-driven ecosystem, and welcoming atmosphere. ACM MM 2025 provided a
dynamic platform for presenting state-of-the-art research, discussing emerging
trends, and fostering collaboration across diverse areas of multimedia
computing.
Hosted in
Dublin—a vibrant hub for both technology and academia—the conference delivered
a seamless and engaging experience for all attendees. As part of its ongoing
mission to support and encourage the next generation of multimedia researchers,
SIGMM awarded Student Travel Grants to assist students facing financial
constraints. Each recipient received up to 1,000 USD to help offset travel and
accommodation expenses. Applicants completed an online form, and the selection
committee evaluated candidates based on academic excellence, research
potential, and demonstrated financial need.
To shed light on the experiences of these outstanding young scholars, we interviewed several travel grant recipients about their participation in ACM MM 2025 and the conference’s influence on their academic and professional development. Their reflections are shared below.
Wang Zihao – Zhejiang University
This was not my first time attending ACM Multimedia—I also
participated in ACMMM 2022—but coming back in 2025 has been just as fantastic.
There were many memorable moments, but two of them stood out the most for me.
The first was the beautiful violin performance during the Volunteer Dinner,
which created such a warm and elegant atmosphere. The second was the Irish
drumming performance at the conference banquet on October 30th. It was
incredibly energetic and truly unforgettable. These moments reminded me how
special it is to be part of this community, where academic exchange and
cultural experiences blend together so naturally.
I am truly grateful for the SIGMM Student Travel Grant. The
financial support made it possible for me to attend the conference in person,
and I really appreciate the effort that SIGMM puts into supporting students.
One of the most valuable aspects of this trip was meeting researchers from all
over the world who work in areas similar to mine—especially those focusing on
music, audio, and multimodality. Having deep, face-to-face conversations with
them was inspiring and has given me many new ideas to explore in my future
research.
As for suggestions, I honestly think the SIGMM Student
Travel Grant program is already doing an amazing job in supporting young
scholars like us. My only small hope is for a smooth reimbursement process.
Overall, I feel incredibly fortunate to be here again, reconnecting with the ACM MM community and learning so much from everyone. I’m thankful for this opportunity and excited to continue growing in this field.
Huang Feng-Kai – National Taiwan University
Attending ACM Multimedia 2025 in Dublin was my first time joining the
conference, and it has been an unforgettable experience. Everything was so
well-organized, and I truly enjoyed every moment. The welcome reception was
especially memorable—the food was delicious, the atmosphere was lively, and it
was inspiring to see so many renowned researchers and professors chatting
enthusiastically. It really felt like the perfect start to my ACM MM journey.
I am deeply grateful to SIGMM for the Student Travel Grant. As a student
traveling all the way from Taiwan, attending a conference in Europe is a major
financial challenge. The grant covered my accommodation, meals, and flights,
which made it possible for me to participate without worrying too much about
the cost. Being here has really broadened my horizons. I was able to learn
about so many fascinating research topics and meet many kind, talented
researchers who generously shared their thoughts with me. These conversations
gave me a lot of inspiration for my own work.
I also had the chance to serve as a volunteer, which became my first
experience working with an international team. Collaborating with people from
different cultural and academic backgrounds helped me improve my communication
skills and made the conference even more meaningful.
I truly believe the SIGMM Student Travel Grant is an amazing program that enables students from all over the world to join this vibrant community, exchange ideas, and form new collaborations. My only wish is that SIGMM will continue offering this opportunity in the future. This grant brings so much energy to young researchers like me and plays an important role in supporting the next generation of the multimedia community. I am sincerely thankful for everything this experience has given me, and I look forward to returning to ACM Multimedia in the coming years.
Wang Hao (Peking University)
Attending ACM Multimedia 2025 was my very first time
participating in the conference, and the experience was truly amazing. The
moment that impressed me the most was having the chance to present my own
paper. As a non-native English speaker, giving an academic talk on an
international stage was both challenging and rewarding. I felt nervous at
first, but I’m really proud of how I managed to deliver my presentation. It was
a big milestone for me.
I’m incredibly grateful to SIGMM for the Student Travel
Grant, which made it possible for me to attend an international conference for
the first time. Without this support, I wouldn’t have been able to experience
such a meaningful academic event. Throughout the conference, I met so many new
friends, attended inspiring talks, and gained fresh perspectives on multimedia
research. These experiences have broadened my view of the field and will
definitely influence the direction of my future work.
I’m thankful for this opportunity and truly appreciate how welcoming and encouraging the ACM MM community is. This conference has given me motivation and confidence to continue growing as a researcher.
Yu Liu (University of Electronic Science and Technology of China)
This is my first time attending ACM Multimedia. I am a PhD student at the
University of Electronic Science and Technology of China (UESTC), currently
spending a year at the University of Auckland, New Zealand, as part of a joint
PhD program. It took 25 hours to travel from Auckland to Dublin, but the
journey was completely worth it. The conference has been vibrant and
intellectually engaging. I had the honor of being the first speaker in my
session, and it was incredibly fulfilling to see the audience show genuine
interest and appreciation for our work. Outside the sessions, I thoroughly
enjoyed immersing myself in Irish culture—tasting the smooth, rich Guinness,
watching lively tap dancing, and listening to traditional Irish music. Overall,
it has been an inspiring and truly memorable experience.
The SIGMM Student Travel Grant played a vital role in making my attendance
possible. In recent years, UESTC has discontinued funding for PhD students’
conference travel, transferring the financial responsibility entirely to
individual research groups. Receiving this grant was crucial, allowing me to
attend ACM MM 2025 without placing additional strain on my research team’s
limited budget. Attending the conference in person provided an invaluable
opportunity to present my research, exchange ideas face-to-face with
international scholars, and receive constructive feedback from leading experts.
These experiences fostered meaningful academic connections and opened doors for
potential long-term collaborations that online participation simply cannot
replace.
My biggest takeaway from ACM MM 2025 is the inspiration I gained from being part of such a diverse and passionate research community, which has motivated me to continue advancing in the field of responsible AI. I also really enjoyed the volunteer “Thank You” dinner—it was a wonderful experience. At the same time, I noticed that it is not always easy for students to approach professors they do not know personally. In the future, including short icebreaker or networking activities could help start conversations more naturally, making the conference experience even more valuable for students like me.
Li Deng (LUT University)
This is my first time attending ACM Multimedia, and my experience has been
exceptionally positive. I was particularly impressed by the workshops relevant
to my research area, as the discussions provided valuable insights that are
already influencing my ongoing work. I was also struck by the abundance and
quality of the social events and networking opportunities, which made it easy
to connect with senior researchers and fellow students from diverse
backgrounds.
Receiving the SIGMM Student Travel Grant significantly reduced the financial
burden of travel and accommodation, allowing me to attend the conference in
person without major financial stress. The opportunity to present my work and
engage in discussions with leading researchers has greatly supported my
academic development. I received direct feedback and established connections
that may lead to future collaborations. My biggest takeaway from ACM MM 2025 is
a deeper understanding of the rapid development and impact of multimodal large
language models.
Looking ahead, I suggest that the SIGMM Student Travel Grant program
collaborate with the main conference to organize sessions such as a “Career
Forum” for grant recipients and other student volunteers, providing additional
guidance and support for early-career researchers.
JPEG XS developers awarded the Engineering, Science and Technology Emmy®.
The 109th JPEG meeting was held in Nuremberg, Germany, from 12 to 17 October 2025.
This JPEG meeting began with the excellent news that JPEG XS developers Fraunhofer IIS and intoPIX were awarded the Engineering, Science and Technology Emmy® for their contributions to the development of the JPEG XS standard.
Furthermore the 109th JPEG meeting was also marked by several major achievements: JPEG Trust Part 2 on Trust Profiles and Reports, complementing Part 1 with several profiles for various usage scenarios, reached Committee Draft; JPEG AIC part 3 was produced for final publication by ISO; JPEG XE reached Committee Draft stage; and the calls for proposals on objective evaluation JPEG AIC-4 and JPEG Pleno Quality Assessment of Light Field received several responses.
The following sections summarise the main highlights of the 109th JPEG meeting:
Fraunhofer IIS and intoPIX representatives with the awarded Engineering, Science and Technology Emmy®.
JPEG Trust Part 2 on Trust Profiles and Reports reaches Committee Draft stage.
JPEG AIC-4 receives responses to the Call for Proposals on Objective Image Quality Assessment.
JPEG XE Part 1, the core coding system, reaches DIS stage.
JPEG XS Part 1 AMD 1 reaches DIS stage.
JPEG AI Part 2 (Profiling), Part 3 (Reference Software), and Part 5 (File Format) approved as International Standards.
JPEG DNA designed the wet-lab experiments, including DNA synthesis/sequencing.
JPEG Peno receives responses to the Call for Proposals on Objective Metrics for Light Field Quality Assessment.
JPEG RF establishes frameworks for coding and quality assessment of radiance fields.
JPEG XL innitiates embedding of JPEG XL in ISOBMFF/HEIF.
JPEG Trust
At the 109th JPEG Meeting, the JPEG Committee reached a key milestone with the completion of the Committee Draft (CD) for JPEG Trust Part 2 – Trust Profiles and Reports (ISO/IEC 21617-2). Building on the framework established in Part 1 (Core Foundation), this new specification further refines Trust Profiles and Trust Reports and provides several example profiles and reusable profile snippets for adoption in diverse usage scenarios.
Compared to earlier drafts, the new Trust Profiles specification introduces templates and dynamic metadata blocks, offering enhanced flexibility while maintaining full backwards compatibility for existing profiles. This flexibility is also reflected in the updated Trust Reports, which can now be more easily tailored to specific usage scenarios. This new specification sets the stage for user communities to build their own Trust Profiles and customise them to their specific needs.
In addition to the CD on Part 2, the committee also produced a CD of Part 4 – Reference Software. This specification provides a reference implementation and reference dataset of the Core Foundation. The reference software will be extended with additional implementations in the future.
Finally, the committee also advanced Part 3 – Media Asset Watermarking. The Terms and Definitions and Use Cases and Requirements documents are now publicly available on the JPEG website. The development of Part 3 is progressing on schedule, with the Committee Draft stage targeted for January 2026.
JPEG AIC
The JPEG AIC-3 standard, which specifies a methodology for fine-grained subjective image quality assessment in the range from good quality up to mathematically lossless, was finalised at the 109th JPEG meeting and will be published as International Standard ISO/IEC 29170-3.
In response to the JPEG AIC-4 Call for Proposals on Objective Image Quality Assessment, four proposals were received and presented. A large-scale subjective experiment has been prepared in order to evaluate the proposals.
JPEG XE
JPEG XE is a joint effort between ITU-T SG21 and ISO/IEC JTC1/SC29/WG1 and will become the first internationally endorsed specification by major standardization bodies ITU-T, ISO, and IEC, for coding of events. It aims to establish a robust and interoperable format for efficient representation and coding of events in the context of machine vision and related applications. To expand the reach of JPEG XE, the JPEG Committee has closely coordinated its activities with the MIPI Alliance with the intention of developing a cross-compatible coding mode, allowing MIPI ESP signals to be decoded effectively by JPEG XE decoders.
At the 109th JPEG Meeting, the DIS of JPEG XE Part 1, the core coding system, was prepared. This part specifies the low-complexity and low-latency lossless coding technology that will be the foundation of JPEG XE. Reaching DIS stage is a major milestone and freezes the core coding technology for the first edition of JPEG XE. The JPEG Committee plans to further improve the coding performance and to provide additional lossless and lossy coding modes, scheduled to be developed in 2026. While the DIS of Part 1 is under ballot for approval as an International Standard, the JPEG Committee initiated the work on Part 2 of JPEG XE to define the profiles and levels. A DIS of Part 2 is planned to be ready for ballot in January 2026.
With JPEG XE Part 1 under ballot and Part 2 in the pipeline, the JPEG Committee remains committed to the development of a comprehensive and industry-aligned standard that meets the growing demand for event-based vision technologies. The collaborative approach between multiple standardisation organisations underscores a shared vision for a unified, international standard to accelerate innovation and interoperability in this emerging field.
JPEG XS
The JPEG Committee is extremely proud to announce that the two companies behind the development of JPEG XS, intoPIX and Fraunhofer IIS, were awarded an Emmy® for Engineering, Science, and Technology for their role in the development of the JPEG XS standard. The awards ceremony was held on October 14th, 2025, at the Television Academy’s Saban Media Center in North Hollywood, California. This award recognizes JPEG XS for being a state-of-the-art image compression format that transmits high-quality images with minimal latency and low-resource consumption, with visually near-lossless image quality. It affirms that JPEG XS is the fundamental game changer for real-time transmission of video in live, professional video, and broadcast applications, and that it is being heavily adopted by the industry.
Nevertheless, the work to further improve JPEG XS continues. In this context, the DIS of AMD 1 of JPEG XS Part 1 is currently under ballot at ISO and is expected to be ready by January 2026. This amendment enables the embedding of sub-frame metadata to JPEG XS as required by augmented and virtual reality applications currently discussed within VESA. The JPEG Committee also initiated the steps to start an amendment for Part 2 (Profiles and buffer models) that will define additional sublevels needed to support on-the-fly proxy-level extraction (i.e. lower resolution streams from a master stream) without recompression. The amendment is planned to go to DIS ballot at the next 110th JPEG meeting in Sydney, Australia.
JPEG AI
During the 109th JPEG meeting, the JPEG AI project achieved major milestones, with Part 2 (Profiling), Part 3 (Reference Software), and Part 5 (File Format) approved as International Standards. Meanwhile, Part 4 (Conformance) is proceeding to publication after a positive ballot. The Core Experiments confirmed that JPEG AI outperforms state-of-the-art codecs in compression efficiency and demonstrated a decoder implementation based on the SADL library.
JPEG DNA
During the 109th JPEG meeting, the JPEG Committee designed the wet-lab experiments, including DNA synthesis/sequencing, with results expected by January 2026. The primary objective of the wet-lab experiments is to validate the technical specifications outlined in the current DIS study text of ISO/IEC 25508-1 in the realistic procedures for DNA media storage. Additional efforts are underway as a new Core Experiment to study the performance of the codec-dependent unequal error correction technique, which is expected to result in the future publication of JPEG DNA Part 2 – Profiles and levels.
JPEG Pleno
JPEG Pleno marked a pivotal step toward the forthcoming ISO/IEC 21794-7 standard, Light Field Quality Assessment. The new Part 7 was officially approved for inclusion in the ISO/IEC work programme, confirming international support for standardizing light field quality assessment methodologies. Moreover, in response to the Call for Proposals on Objective Metrics for Light Field Quality Assessment, three proposals were received and presented. In preparation for the evaluation of the proposals submitted in response to the CfP, an evaluation dataset was released and discussed during the meeting. The next milestone is the execution of a Subjective Quality Assessment on the evaluation dataset to evaluate the proposed objective metrics by the 110th JPEG meeting in Sydney. To this end, the methodological design and preparation of the subjective test were discussed and finalized, marking an important step toward developing the standardization framework for objective light field quality assessment.
The JPEG Pleno Workshop on Emerging Coding Technologies for Plenoptic Modalities was conducted at the 109th meeting with presentations from Touradj Ebrahimi (JPEG Convenor), Peter Schelkens (JPEG Plenoptic Coding and Quality Sub-Group Chair), Aljosa Smolic (Hochschule Luzern), Søren Otto Forchhammer (Danmarks Tekniske Universitet), Giuseppe Valenzise (Université Paris-Saclay), Amr Rizk (Leibniz Universität Hannover), Michael Rudolph (Leibniz Universität Hannover), and Irene Viola (Centrum Wiskunde & Informatica).
JPEG RF
At the 109th JPEG Meeting the exploration activity on JPEG Radiance Fields (JPEG RF) continued its progress toward establishing frameworks for coding and quality assessment of radiance fields. The group updated the drafts of the Use Cases and Requirements and Common Test Conditions, alongside the outcomes of an Exploration Study, which examined the impact of camera trajectory design on human perception during a subjective quality assessment. These discussions refined methodological guidelines for trajectory generation and the subjective assessment procedures. Building on this progress, Exploration Study 6 was launched to benchmark the complete assessment framework through a subjective experiment using the developed protocols. Outreach activities were also planned to engage additional stakeholders and support further development ahead of the next 110th JPEG Meeting in Sydney, Australia.
JPEG XL
At the 109th JPEG meeting, work has started on an embedding of JPEG XL in ISOBMFF/HEIF. It will be described in a new edition of ISO/IEC 18181-2, which has been initiated.
Final Quote
“During the 109th JPEG Meeting, the JPEG Committee reached several important milestones. In particular, JPEG Trust continues its development with the addition of new Parts towards the creation of a reliable and effective standard that restores authenticity and provenance of the multimedia information.” said Prof. Touradj Ebrahimi, the Convenor of the JPEG Committee.
This column introduces the now completed ITU-T P.1204 video quality model standards for assessing sequences up to UHD/4K resolution. Initially developed over two years by ITU-T Study Group 12 (Question Q14/12) and VQEG, the work used a large dataset of 26 subjective tests (13 for training, 13 for validation), each involving at least 24 participants rating sequences on the 5-point ACR scale. The tests covered diverse encoding settings, bitrates, resolutions, and framerates for H.264/AVC, H.265/HEVC, and VP9 codecs. The resulting 5,000-sequence dataset forms the largest lab-based source for model development to date. Initially standardized were P.1204.3, a no-reference bitstream-based model with full bitstream access, P.1204.4, a pixel-based, reduced-/full-reference model, and P.1204.5, a no-reference hybrid model. The current record focuses on the latest additions to the series, namely P.1204.1, a parametric, metadata-based model using only information about which codec was used, plus bitrate, framerate and resolution, and P.1204.2, which in addition uses frame-size and frame-type information to include video-content aspects into the predictions.
Introduction
Video quality under specific encoding settings is central to applications such as VoD, live streaming, and audiovisual communication. In HTTP-based adaptive streaming (HAS) services, bitrate ladders define video representations across resolutions and bitrates, balancing screen resolution and network capacity. Video quality, a key contributor to users’ Quality of Experience (QoE), can vary with bandwidth fluctuations, buffer delays, or playback stalls.
While such quality fluctuations and broader QoE aspects are discussed elsewhere, this record focuses on short-term video quality as modeled by ITU-T P.1204 for HAS-type content. These models assess segments of around 10s under reliable transport (e.g., TCP, QUIC), covering resolution, framerate, and encoding effects, but excluding pixel-level impairments from packet loss under unreliable transport.
Because video quality is perceptual, subjective tests, laboratory or crowdsourced, remain essential, especially at high resolutions such as 4K UHD under controlled viewing conditions (1.5H or 1.6H viewing distance). Yet, studies show limited perceptual gain between HD and 4K, depending on source content, underlining the need for representative test materials. Given the high cost of such tests, objective (instrumental) models are required for scalable, automated assessment supporting applications like bitrate ladder design and service monitoring.
Four main model classes exist: metadata-based, bitstream-based, pixel-based, and hybrid. Metadata-based models use codec parameters (e.g., resolution, bitrate) and are lightweight; bitstream-based models analyze encoded streams without decoding, as in ITU-T P.1203 and P.1204.3 [1][2][3][7]. Pixel-based models compare decoded frames and include Full Reference and Reduced Reference models (e.g., P.1204.4, and also PSNR [9], SSIM [10], VMAF [11][12]), as well as No Reference variants. Finally, hybrid models combine pixel and bitstream or metadata inputs, exemplified by the ITU-T P.1204.5 standard. These three standards, P.1204.3 P.1204.4 and P.1204.5, formed the initial P.1204 Recommendation series finalized in 2020.
ITU-T P.1204 series completed with P.1204.1 and P.1204.2
The respective standardization project under the Work Item name P.NATS Phase 2 (read: Peanuts) was a unique video quality model development competition conducted in collaboration between ITU-T Study Group 12 (SG12) and the Video Quality Experts Group (VQEG). The target use cases were for up to UHD/4K resolution, with presentation on UHD/4K resolution PC/TV or Mobile/Tablet (MO/TA). For the first time, bitstream-, pixel-based, and hybrid models were jointly developed, trained, and validated, using a large common subjective dataset comprising 26 tests, each with at least 24 participants (see, e.g., [1] for details). The P.NATS Phase 2 work built on the earlier “P.NATS Phase 1” project, which resulted in the ITU-T Rec. P.1203 standards series (P.1203, P.1203.1, P.1203.2, P.1203.3). In the P.NATS Phase 2 project, video quality models in five different categories were evaluated, and different candidates were found to be eligible to be recommended as standards. The initially standardized three models out of the five categories were the aforementioned P.1204.3, P.1204.4 and P.1204.5. However, due to the lack of consensus between the winning proponents, no models were recommended as standards for the category “bitstream Mode 0” with access to high-level metadata only, such as the video codec, resolution, framerate and bitrate used, and “bitstream Mode 1”, with further access to frame-size information that can be used for content-complexity estimation.
For the latest model additions of P.1204.1 and P.1204.2, subsets of the databases initially used in the P.NATS Phase 2 project were employed for model training. Two different datasets belonging to the two contexts PC/TV and MO/TA were used for training the models. AVT-PNATS-UHD-1 is the dataset for the PC/TV use case and ERCS-PNATS-UHD-1 the dataset used for the MO/TA use case.
AVT-PNATS-UHD-1 [7] consists of four different subjective tests conducted by TU Ilmenau as part of the P.NATS Phase 2 competition. The target resolution of these datasets was 3840 x 2160 pixels. ERCS-PNATS-UHD-1 [1] is a dataset targeting the MO/TA use case. It consists of one subjective test conducted by Ericsson as part of the P.NATS Phase 2 competition. The target resolution of these datasets was 2560 x 1440 pixels.
For model performance evaluation, beyond AVT-PNATS-UHD-1, further externally available video-quality test databases were used, as outlined in the following.
AVT-VQDB-UHD-1: This is a publicly available dataset and consists of four different subjective tests. All the four tests had a full-factorial design. In total, 17 different SRCs with a duration of 7-10 s were used across all the four tests. All the sources had a resolution of 3840×2160 pixels and a framerate of 60 fps. For HRC design, bitrate was selected in fixed (i.e. non-adaptive) values per PVS between 200kbps and 40000kbps, resolution between 360p and 2160p and framerate between 15fps and 60fps. In all the tests, a 2-pass encoding approach was used to encode the videos, with medium preset for H.264 and H.265, and the speed parameter for VP9 set to the default value “0”. A total of 104 participants in the four tests.
GVS: This dataset consists of 24 SRCs that have been extracted from 12 different games. The SRCs are of 1920×1080 pixel resolution, 30fps framerate and have a duration of 30s . The HRC design included three different resolutions, namely, 480p, 720p and 1080p . 90 PVSs resulting from 15 bitrate-resolution pairs were used for subjective evaluation. A total of 25 participants rated all the 90 PVSs.
KUGVD: Six SRCs out of the 24 SRCs from the GVSwere used to develop KUGVD. The same bitrate-resolution pairs from GVS were included to define the HRCs. In total, 90 PVSs were used in the subjective evaluation and 17 participants took part in the test.
CGVDS: This dataset consists of SRCs captured at 60fps from 15 different games. For designing the HRCs, three resolutions, namely, 480p, 720p and 1080p at three different framerates of 20, 30, and 60fps were considered. To ensure that the SRCs from all the games could be assessed by test subjects, the overall test was split into 5 different subjective tests, with a minimum of 72 PVSs being rated in each of the tests. A total of over 100 participants took part over the five different tests, with a minimum of 20 participants per test.
Twitch: The Twitch Dataset consists of 36 different games, with 6 games each representing one out of 6 pre-defined genres. The dataset consists of streams directly downloaded from Twitch. A total of 351 video sequences of approximately 50s duration across all representations were downloaded. 90 video sequences out of these 351 video sequences were selected for subjective evaluation. Only the first 30s of the chosen 90 PVSs were considered for subjective testing. Six different resolutions between 160p and 1080p at framerates of 30 and 60fps were used. 29 participants rated all the 90 PVSs.
BBQCG: This is the training dataset developed as part of the P.BBQCG work item. This dataset consists of nine subjective test databases. Three out of these nine test databases consisted of processed video sequences (PVSs) up to 1080p/120fps and the remaining had PVSs up to 4K/60fps. Three codecs, namely, H.264, H.265, and AV1 were used to encode the videos. Overall 900 different PVSs were created from 12 sources (SRCs) by encoding the SRCs with different encoding settings.
AVT-VQDB-UHD-1-VD: This dataset consists of 16 source contents encoded using a CRF-based encoding approach. Overall 192 PVSs were generated by encoding all 16 sources in four resolutions, namely, 360p, 720p, 1080p, 2160p with three CRF values (22, 30, 38) each. A total of 40 subjects participate in the study.
ITU-T P.1204.1 and P.1204.2 model prediction performance
The performance figures of the two new models P.1204.1 and P.1204.2 models on the different datasets are indicated in Table 1 (P.1204.1) and Table 2 (P.1204.2) below.
Table 1: Performance of P.1204.1 (Mode 0) on the evaluation datasets, in terms of Root Mean Square Error (RMSE, measure used as winning criterion in the ITU-T/VQEG modelling competition). Pearson Correlation Coefficeint (PCC), Spearman Rank Correlation Coefficient (SRCC) and Kendall’s tau.
Dataset
RMSE
PCC
SRCC
Kendall
AVT-VQDB-UHD-1
0.499
0.890
0.877
0.684
KUGVD
0.840
0.590
0.570
0.410
GVS
0.690
0.670
0.650
0.490
CGVDS
0.470
0.780
0.750
0.560
Twitch
0.430
0.920
0.890
0.710
BBQCG
0.598 (on a 7-point scale)
0.841
0.843
0.647
AVT-VQDB-UHD-1-VD
0.650
0.814
0.813
0.617
Table 2: Performance of P.1204.1 (Mode 1) on the evaluation datasets, in terms of Root Mean Square Error (RMSE, measure used as winning criterion in the ITU-T/VQEG modelling competition). Pearson Correlation Coefficeint (PCC), Spearman Rank Correlation Coefficient (SRCC) and Kendall’s tau.
Dataset
RMSE
PCC
SRCC
Kendall
AVT-VQDB-UHD-1
0.476
0.901
0.900
0.730
KUGVD
0.500
0.870
0.860
0.690
GVS
0.420
0.890
0.870
0.710
CGVDS
0.360
0.900
0.880
0.690
Twitch
0.370
0.940
0.930
0.770
BBQCG
0.737 (on a 7-point scale)
0.745
0.746
0.547
AVT-VQDB-UHD-1-VD
0.598
0.845
0.845
0.654
For all databases except BBQCG and KUGVD, the Mode 0 model P.1204.1 performs in a solid way, as shown in Table 1. With the information about frame types and sizes available to the Mode 1 model P.1204.2, performance improves considerably, as shown in Table 2. For performance results of all three previously standardized models, P.1204.3, P.1204.4 and P.1204.5, the reader is referred to [1] and the individual standards, [4][5][6]. For the P.1204.3 model, complementary performance information is presented in, e.g., [2][7]. For P.1204.4, additional model performance information is available in [8], including results for AV1, AVS2, and VVC.
The following plots provide an illustration of how the new P.1204.1 Mode 0 model may be used. Here, bitrate-ladder-type graphs are presented, with the predicted Mean Opinion Score on a 5-point scale plotted over log bitrate.
Codec: H.264
Codec: H.265
Codec: VP9
Conclusions and Outlook
The P.1204 standard
series now comprises the complete initially planned set of models, namely:
ITU-T P.1204.1: Bitstream Mode 0, i.e., metadata-based model with access to information about video codec, resolution, framerate and bitrate used.
ITU-T P.1204.2: Bitstream Mode 1, i.e., metadata-based model with access to information about video codec, resolution, framerate and bitrate used, plus information about video frame types and sizes.
Extensions of some of these models beyond the initial scope of codecs (H.264/AVC, H.265/HEVC, VP9) have been included over the last few years. Here, P.1204.4 and P.1204.5 have been extended (P.1204.5) or evaluated (P.1204.4) to also cover the AV1 video codec. Work in ITU-T SG12 (Q14/12) is ongoing so as to also extend P.1204.1, P.1204.2 and P.1204.3 to newer codecs such as AV1, and all five models are planned to be extended so as to also cover VVC. It is noted that for P.1204.3, P.1204.4 and P.1204.5, also long-term quality integration modules that generate per-session scores for up to 5min long streaming sessions have been described in Appendices of the respective recommendations. For P.1204.1 and P.1204.2, this extension still has to be completed. Initial evaluations for similar Mode 0 and Mode 1 models that use the P.1204.3-type long-term integration can be found in [7].
AI evaluation is undergoing a paradigm shift from focusing solely on algorithmic accuracy of AI models to emphasizing experience-based assessment of human interactions with AI systems. Under frameworks like the EU AI Act, evaluation now considers intended purpose, risk, transparency, human oversight, and real-world robustness alongside accuracy. Quality of Experience (QoE) methodologies may offer a structured approach to evaluate how users perceive and experience AI systems in terms of transparency, trust, control and overall satisfaction. This column gives inspiration and shared insights for both communities to advance experience-based AI system evaluation together.
1. From algorithms to systems: AI as user experience
Artificial Intelligence (AI) algorithms—mathematical models implemented as lines of code and trained on data to predict, recommend or generate outputs—were, until recently, tools reserved for programmers and researchers. Only those with technical expertise could access, run or adapt them. For decades, progress in AI was equated with improvements in algorithmic performance: higher accuracy, better precision or new benchmark records—often achieved under narrow, controlled conditions that did not reflect the full spectrum of real-world operational environments. These advances, though scientifically impressive, remained largely invisible to society at large.
The turning point came when AI stopped being just code and became an experience accessible to everyone, regardless of their technical background. Once algorithms were embedded into interactive systems—chatbots, voice assistants, recommendation platforms, image generators—AI became ubiquitous, integrated into people’s daily lives. Interfaces transformed technical capability into human experience, making AI not only a purely algorithmic or research-oriented field but also a social, experiential and increasingly public phenomenon [Mlynář et al., 2025].
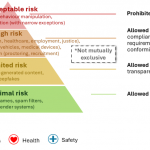
This shift fundamentally changed what it means to evaluate AI [Bach et al., 2024]. Accuracy-based metrics—such as precision, recall, specificity or F1-score—no longer suffice for systems that mediate human experiences, influence decision-making and shape trust. Evaluation must now extend beyond the model’s internal performance to assess the interaction, context and experience that emerge when humans engage with AI systems in realistic conditions. We must therefore move from evaluating algorithms in isolation to genuinely human-centered approaches to AI and the experiences it enables [see e.g., https://hai.stanford.edu/], evaluating AI systems as a whole, holistically—considering not only their technical performance but also their experiential, contextual, and social impact [Shneiderman, 2022]. The European Union’s Artificial Intelligence Act [AI Act, 2024] provides a clear illustration of this shift. As the first comprehensive regulatory framework for AI, it recognizes that while algorithmic quality remains essential, what is ultimately regulated is the AI system—its design, use, and intended purpose. Obligations under the Act are tied to that intended purpose, which determines both the risk level and the compliance requirements (see figure below). For instance, the same object detection model can be considered low risk when used to organize personal photo libraries, but high risk when deployed in an autonomous vehicle’s collision-avoidance system.
Figure 1. The European Union’s Artificial Intelligence Act [AI Act, 2024]: risk and obligations depend on an AI system’s intended purpose—permitting low-risk uses while restricting or prohibiting high-risk applications. Examples in the figure are illustrative, not exhaustive. Some uses require prior authorisation under the EU AI Act.
This illustrates a fundamental change: evaluating AI systems today requires understanding how, where and by whom a system is used—not merely how accurate its underlying AI model is. Moreover, evaluation must consider how systems behave and degrade under operational conditions (e.g., adverse weather in traffic monitoring or biased performance across demographic groups in facial analysis), how humans interact with, interpret and rely on them, and what mechanisms of human oversight or intervention exist in practice to ensure accountability and control [Panigutti et al., 2023].
2. Towards a paradigm shift in AI evaluation
The European AI Act marks the first comprehensive attempt to regulate the design, deployment and use of AI systems. Yet its underlying philosophy resonates broadly with the principles endorsed by other high-level international institutions and initiatives—such as the OECD [OECD, 2024], the World Economic Forum [WEF, 2025] and, more recently, the Paris AI Action Summit [CSIS, 2025], where over sixty countries signed a joint commitment to promote responsible, trustworthy and human-centric AI.
Among the many obligations set out in the AI Act for high-risk AI systems, three provisions stand out as emblematic of this paradigm shift: they focus not on algorithmic precision, but on how AI systems are experienced, supervised and operated in the real world.
Article 13 – Transparency. AI systems must be designed and developed in a way that is sufficiently transparent to enable users to interpret their output and use it appropriately. Transparency therefore extends beyond disclosure or documentation: it encompasses interaction design and interpretability, ensuring that users—especially non-experts—can meaningfully understand and act upon what the system produces, based on which input and how.
Article 14 – Human oversight. High-risk AI systems must allow for effective human supervision so that they can be used as intended and to prevent or minimise risks to health, safety or fundamental rights (e.g., respect for human dignity, privacy, equality and non-discrimination). Oversight involves not only control features or override mechanisms, but also interface designs that help operators recognise when human intervention is necessary—addressing known challenges such as automation bias and over-trust on AI systems [Gaudeul et al., 2024].
Article 15 – Accuracy, robustness and cybersecurity. This provision broadens the traditional notion of accuracy, demanding that systems perform reliably under real-world operational conditions and remain secure and resilient to errors, adversarial manipulation or context change. It also calls for mechanisms that support graceful degradation and error recovery, ensuring sustained trust and dependable performance over time.
These provisions, aligned to both the AI Act and the broader international discourse on responsible AI, express a clear transformation in how AI systems should be evaluated. They call for a move beyond in-lab algorithmic performance metrics to include criteria grounded in human experience, operational reliability and social trust. To make these requirements actionable, the European Commission issued a Standardisation Request on Artificial Intelligence (initially published as M/593, 2024 [European Commission, 2024] and subsequently updated following the adoption of the AI Act), mandating the development of harmonised standards to support conformity with the regulation. Yet analyses of existing AI standardisation frameworks suggest that they remain primarily focused on technical robustness and risk management, while offering limited methodological guidance for assessing transparency, human oversight and perceived reliability [Soler et al., 2023].
This gap underscores the need for contributions from the Quality of Experience (QoE) community, whose expertise in assessing perceived quality, pragmatic, hedonic and increasingly also eudaimonic aspects of users’ experiences, usability and trust could inform both standardisation efforts and AI system design in practice. For example, [Hammer et al., 2018] introduced the “HEP cube”, that is a 3D model that maps hedonic (H), eudaimonic (E), and pragmatic (P) aspects of QoE and user experience. For example, utility (P), joy-of-use (H), and meaningfulness (E) are integrated into a multidimensional HEP construct [Egger-Lampl et al., 2019]. In professional contexts, long-term experiential quality depends increasingly on eudaimonic factors such as meaning and personal growth of the user’s capabilities. On the example of augmented reality for the informational phase of procedure assistance, [Hynes et al., 2023] take into account pragmatic aspects like clear, accurately aligned AR instructions that reduce cognitive load and support efficient task execution; hedonic and eudaimonic aspects involve engaging, intuitive interactions that not only make the experience pleasant but also foster confidence, competence, and meaningful professional growth. The study confirmed that AR better fulfills users’ pragmatic needs compared to paper-based instructions. However, the hypothesis that AR surpasses paper-based instructions in meeting hedonic needs was rejected. [Oppermann et al., 2024] evaluated a VR-based forestry safety training and found improved experiential quality and real-world skill transfer compared to traditional instruction. In addition to hedonic and pragmatic UX, eudaimonic experience was assessed by asking participants whether the training would help them “make me a better forestry worker” and “develop my personal potential”.
3. From benchmark performance to operational reality: the case of facial recognition
The example of remote facial recognition (RFR) for public security clearly illustrates how traditional accuracy-based evaluation fails to capture the real challenges of proportionality, operational viability and public trust that define the true quality of experience of AI in use. Under the EU AI Act, the use of real-time remote biometric identification systems in publicly accessible spaces for law enforcement is prohibited, except in narrowly defined circumstances—such as the prevention of terrorist threats, the search for missing persons or the prosecution of crimes—and always subject to prior authorisation by a competent authority. In these cases, the authority must assess whether the deployment of such a system is necessary and proportionate to the intended purpose.
Both the AI Act and the World Economic Forum emphasise this principle of “proportionality” for face recognition systems [AI Act, 2024], [Louradour & Madzou, 2021], yet without providing a clear guidance to determine what “proportionate use” actually means. Deciding whether to deploy RFR therefore requires balancing multiple dimensions—technical performance, societal impact and human oversight—beyond mere accuracy scores [Negri et al., 2024]. Consider, for instance, a competent authority evaluating whether to deploy an RFR system in airports screening 200 million passengers annually, where the estimated prevalence of genuine threats is roughly one in fifty million. Even with a true positive rate (TPR) and true negative rate (TNR) of 99% (equivalent to 99% sensitivity and specificity), the outcome is paradoxical: nearly all real threats would be detected (≈ 4 per year), but around two million innocent passengers would face unnecessary police interventions. Algorithmically, a 99% performance looks excellent. Operationally, it is unmanageable and counterproductive. Handling millions of false alarms would overwhelm security forces, delay operations, and—most importantly—erode public trust, as citizens repeatedly experience unjustified scrutiny and loss of confidence in authorities.
Beyond accuracy, competent authorities must evaluate trade-offs between different operational, social and economic dimensions that holistically define the proportionality and viability of an AI system:
Operational feasibility: number of human interventions needed, false alarms to handle and system downtime.
Social impact: perceived fairness, legitimacy and transparency of interventions.
Economic cost: cost of system deployment, resources spent managing false positives versus genuine detections.
Human trust and cognitive load: how repeated interactions with the system affect operator confidence, vigilance and the balance between over-trust and alert fatigue.
Consequences of error: the cost of a missed detection versus that of an unjustified intervention.
Hence, accuracy alone cannot guarantee reliability or trustworthiness. Evaluating AI systems requires contextual and human-aware metrics that capture operational trade-offs and social implications. The goal is not only to predict well, but to perform well in the real world. This example reveals a broader truth: trustworthy AI demands evaluation methods that connect technical performance with lived experience—and this is precisely where the QoE community can make a distinctive contribution.
4. Where AI and QoE should meet: new metrics for a new era
The limitations of accuracy-based evaluation, as illustrated by the facial recognition case, point to a broader need for metrics that capture how AI systems perform in real-world, human-centred contexts [Virvou, 2023],[Park et al., 2023].
Over the past decades, the scientific communities focusing on QoE and user experience (UX) research have developed a rigorous toolbox for quantifying subjective experience—how users perceive quality, usability, pragmatic, hedonic and increasingly also eudaimonic aspects of users’ experiences, reliability, control and satisfaction when interacting with complex technological systems. Originally rooted in multimedia, communication networks and human–computer interaction, these methodologies offer a mature foundation for assessing experienced quality in AI systems. QoE-based approaches can help transform general principles such as transparency, human oversight and robustness into measurable experiential dimensions that reflect how users actually understand, trust and operate AI systems in practice.
The following table presents a set of illustrative examples of QoE-inspired metrics—adapted from long-standing practices in the field—that could be further adapted, developed and validated for the evaluation of trustworthy AI.
General AI principles
QoE-inspired metrics
Transparency and comprehensibility
Perceived transparency score: % of users reporting understanding of system capabilities/limitations, potentially with a way to dimension the gap between reported understanding and actual understanding Explanation clarity MOS: Mean Opinion Score on clarity and interpretability of explanations. While traditional QoE assessment results are often reported as a Mean Opinion Score (MOS), additional statistical measures related to the distribution of scores in the target population are of interest, such as user diversity, uncertainty of user rating distributions, ratio of dissatisfied users, etc. [Hoßfeld et al., 2016] Time to comprehension: average time for a non-expert to understand the meaning of a given output produced by the system. Experienced interpretability: extent to which users feel that explanations meaningfully enhance their understanding of the system’s reasoning and limitations [Wehner et al., 2025].
Human oversight
Perceived controllability: MOS on ease of intervening or correcting system behavior. Intervention success rate: % of interventions improving outcomes. Trust calibration index: alignment between user confidence and actual system reliability.
Robustness and resilience to errors
Perceived reliability over time: longitudinal QoE measure of stability (for example, inspired by work on the longitudinal development of QoE, such as [Guse, D., 2016], [Cieplinska, 2023]). Graceful degradation MOS: subjective quality under stress (e.g., noise, adversarial input). Error recovery satisfaction: % of users satisfied with post-failure recovery.
Experience quality (holistic)
Overall satisfaction MOS: overall perceived quality of interaction with the AI system and factors influencing that experience quality (human, system, context, as discussed in [Reiter et al.. 2014]. Smoothness of use: perceived fluidity, continuity, absence of frustration. Perceived usefulness and usability: e.g., adapted from widely-used SUS/UMUX-Lite scales [Lewis et al., 2013]. Perceived response alignment: capture to what extent the system response aligns semantically and contextually with the prompt intent (particularly relevant for generative AI systems). Cognitive load: mental effort perceived during operation (e.g., adapted NASA-TLX [Hart & Staveland, 1988]). Perceived productivity impact: how users perceive the effect of AI system assistance on task efficiency and cognitive effort, reflecting findings from recent large-scale developer studies [Early-2025 AI, AI hampers Productivity].
These examples illustrate how the QoE perspective can complement traditional performance indicators such as accuracy or robustness. They extend evaluation beyond technical correctness to include how people experience, trust and manage AI systems in operational environments. Of interest will be to further explore and model the complex relationships between identified QoE dimensions and underlying system, context and human influence factors.
To better illustrate such complex relationships, it is useful to consider how technical and experiential dimensions interact dynamically in use. One particularly relevant example concerns how AI systems communicate confidence or uncertainty, and how this shapes users’ perceived trustworthiness, engagement and overall Quality of Experience.
Figure 2. Positive and negative feedback loop between confidence and QoE of AI systems.
While this is only one example among many possible human–AI interaction dynamics, it illustrates the kind of interrelation that still requires deeper understanding. As depicted in the figure above, complex interrelations exist that are not yet fully understood. AI confidence calibration (based on the AI model) and the way how this confidence or uncertainty is transported to users influences the users’ perceived trustworthiness of the AI system. This impacts the user’s confidence to which degree a user trusts their own ability to understand, interpret, and effectively interact with the AI system. Poor calibration can trigger a negative feedback loop of mistrust and disengagement, while well-calibrated, transparent AI fosters a positive feedback loop that enhances trust, confidence, and effective human-AI collaboration. In a negative feedback loop, overconfidence leads to low perceived trustworthiness and a strong QoE decline, while underconfidence results in moderate perceived trustworthiness and medium QoE, ultimately lowering user engagement. In contrast, a positive feedback loop emerges when confidence is well-calibrated and aligns with accuracy or when uncertainty is expressed transparently, leading to high trust, higher QoE, and stronger user engagement. User engagement and QoE are closely interrelated [Reichl et al., 2015], as higher engagement often reflects and reinforces a more positive overall experience.
Following this and similar examples, the bridge that now needs to be built is between the AI community’s focus on algorithmic performance and the QoE community’s expertise in human experience, bringing together two perspectives that have evolved largely in isolation, but are inherently complementary.
5. Conclusions: QoE as part of the missing link between AI systems and real-world experiences
Bridging the gap between how AI systems perform and how they are experienced is now one of the most pressing challenges in the field. The AI community has achieved extraordinary advances in model accuracy, scalability and efficiency, yet these metrics alone do not fully capture how systems behave in context—how they interact with people, support oversight or sustain trust under real operating conditions. The field of QoE, with its long tradition of measuring perceived quality, different experiential dimensions and usability, offers the conceptual and methodological tools needed to evaluate AI systems as experienced technologies, not merely as computational artefacts.
In this context, QoE of AI systems can be adapted from the original definition of QoE as proposed in [Qualinet, 2013] to read as: “The degree of delight or annoyance of a user resulting from interacting with an AI system. It results from how well the AI system fulfills the user’s expectations regarding usefulness, transparency, trustworthiness, comprehensibility, controllability, and reliability, considering the user’s goals, context, and cognitive state.”
Collaborative research between these domains can foster new interdisciplinary methodologies, shared benchmarks and evidence-based guidelines for assessing AI systems as they are used in the real world—not just as they perform in the lab or within classical accuracy-centred benchmarks. Building this shared evaluation culture is essential to advance trustworthy, human-centric AI, ensuring that future systems are not only intelligent but also understandable, reliable and aligned with human values.
This need is becoming increasingly urgent as, in many regions such as the EU, the principles of trustworthy AI are evolving from ethical aspirations into formal regulatory requirements, reinforcing the importance of robust, experience-based evaluation frameworks.
References
[AI Act, 2024] European Parliament & Council of the European Union. (2024). Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/1020 and Directives (EU) 2015/1535 and 2017/745 (Artificial Intelligence Act). Official Journal of the European Union, L 2024/1689. https://eur-lex.europa.eu/eli/reg/2024/1689/oj