The 19th International Conference on Content-based Multimedia Indexing (CBMI) took place as a hybrid conference in Graz, Austria, from September 14-16, 2022, organized by JOANNEUM RESEARCH and supported by SIGMM. After the 2020 edition was postponed and held as a fully online conference in 2021, this was an important step back to a physical conference. Probably still as an effect of the COVID pandemic, the event was a bit smaller than in previous years, with around 50 participants from 18 countries (13 European countries, the rest from Asia and North America). About 60% were attending on-site, the other via web conference.
Program highlights
The conference program included two keynotes. The opening keynote by Miriam Redi from Wikimedia analysed the role of multimedia assets in a free knowledge ecosystem such as the one around Wikipedia. The closing keynote by Efstratios Gavves from the University of Amsterdam showcased recent progress in machine learning of dynamic information and causality in a diverse range of application domains and highlighted open research challenges.
With the aim to increase the interaction between the scientific community and the users of multimedia indexing technologies, a panel session titled “Multimedia Indexing and Retrieval Challenges in Media Archives” was organised. The panel featured four distinguished experts from the audiovisual archive domain. Brecht Declerq from meemoo, the Flemish Institute for Archive, is currently the president of FIAT/IFTA, the International Association of TV Archives. Richard Wright started as a researcher in speech processing before he became a renowned expert in digital preservation, setting up a series of successful European projects in the area. Johan Oomen manages the department for Research and Heritage at Beeld en Geluid, the Netherlands Institute of Sound and Vision. Christoph Bauer is an expert from the Multimedia Archive of the Austrian Broadcasting Corporation ORF and consults archives of the Western Balkan countries on digitisation and preservation topics. The panel tried to analyse why only a small part of research outputs makes it into productive use at archives and identified research challenges such as the need for more semantic and contextualised content descriptions, the ability to easily control the amount vs. accuracy of generated metadata and the need for novel paradigms to interact with multimedia collections beyond the textual search box. At the same time, archives face the challenge of dealing with much richer metadata, but without the quality guarantees known from manually documented content.
Panel discussion with Richard Wright, Brecht Declerq, Christoph Bauer and Johan Oomen (online), moderated by Georg Thallinger.
In addition to five regular paper sessions (presenting 16 papers in total), the 2022 conference followed the tradition of previous editions of special sessions addressing the use of multimedia indexing in specific application areas or specific settings. This year the special sessions (nine papers in total) covered multimedia in clinical applications and for the protection against natural disasters as well as machine learning from multimedia in cases where data is scarce. The program was completed with a poster & demo session, featuring seven posters and two demos.
Participants enjoyed the return of face-to-face discussions at the poster and demo sessions.
The best paper and the best student paper of the conference were each awarded EUR 500, generously sponsored by SIGMM. The selection committee quickly found consensus to award the best paper award to Maria Eirini Pegia, Anastasia Moumtzidou, Ilias Gialampoukidis, Björn Þór Jónsson, Stefanos Vrochidis and Ioannis Kompatsiaris for their paper “BiasUNet: Learning Change Detection over Sentinel-2 Image Pairs”, and the best student paper award to Sara Sarto, Marcella Cornia, Lorenzo Baraldi and Rita Cucchiara for their paper “Retrieval-Augmented Transformer for Image Captioning”. The authors of the best papers were invited to submit an extended version to the IEEE Transactions on Multimedia journal.
Best student paper award for Sara Sarto, presented by Werner Bailer.
Best paper award for Maria Eirini Pegia and Björn Þór Jónsson, presented by Georges Quénot.
Handling the hybrid setting
As a platform for the online part of the conference, an online event using GoTo Webinar has been created. The aim was still to have all presentations and Q&A live, however, speakers were asked to provide a backup video of their talk (which was only used in one case). The poster and demo session was a particular challenge in the hybrid setting. In order to allow all participants to see the contributions in the best setting, all contributions were both presented as printed posters on-site and as a short video online. After discussions took place on-site in front of the posters and demos, a Q&A session connecting the conference room and the remote presenters took place to enable also discussions with the online presenters.
Social events
Getting back to at least hybrid conferences also means having the long missed opportunities to discuss and exchange with both well-known colleagues and first-time attendees during coffee breaks and over lunch and dinner. In addition to a conference dinner on the second evening, the government of the state of Styria, of which Graz is the capital, hosted a reception for the participants in the beautiful setting of the historic Orangerie in the gardens of Graz castle. The participants had the opportunity to enjoy a guided tour through Graz on their way to the reception.
Concert by François Pineau-Benois (violin), Olga Cepovecka (piano) and Dorottya Standi (cello).
A special event was the Music meets Science concert, with the support of SIGMM. This is already the fourth concert which has been presented in the framework of the CBMI conference (2007, 2018, 2021, 2022). After a long conference day, the participants could enjoy works by Schubert and Haydn, Austrian composers which gave an aspect of local Austrian culture to the event. Reflecting the international spirit of CBMI, the concert was given by a trio of very talented young musicians with international careers from three different countries. We thank SIGMM for its support which made this cultural event happen.
Matthias Rüther, director of JOANNEUM RESEARCH DIGITAL, welcomes the conference participants at the reception
Outlook
The next edition of CBMI will be organised in September 2023 in Orleans, France. While it is likely that the hybrid setting is here to stay for the near future, we hope that the share of participants on site will move back towards the pre-pandemic level.
The 13th ACM Multimedia Systems Conference (and its associated workshops: MMVE 2022, NOSSDAV 2022, and GameSys 2022) took place from the 14th – 17th of June 2022 in Athlone, Ireland. The week after, the ACM International Conference on Interactive Media Experiences took place in Aveiro, Portugal from the 22nd – 24th of June. Both conferences are strongly committed to creating a diverse, inclusive and accessible forum to discuss the latest research on multimedia systems and the technology experiences they enable and have been actively working towards this goal over the last number of years. While this is challenging in itself, demanding systematic and continuous efforts at various levels, the worldwide COVID-19 pandemic introduced even more challenges. As it has repeatedly been coined (and shown), restrictions due to the COVID-19 pandemic have had a significant impact on many scholars, such as female academics [1,2], caregivers [3], young scientists [4] and may have exacerbated existing inequalities [5], despite the increased participation possibilities introduced by fully online conferences. The diversity and inclusion chairs of both IMX and MMSys were therefore highly motivated to adopt a set of measures aimed at stimulating the inclusion of underrepresented groups, offering various possibilities for participation, and raising awareness of diversity (and implications of a lack of diversity) for community development and research activities.
SIGMM student travel grants: any student member of SIGMM is eligible to apply for such a grant, however, the students who are the first author of an accepted paper (in any track/workshop) are particularly encouraged to apply. The grants can cover any travel expenses such as airfare/shuttle, hotel and meals (but not conference registration fees).
SIGMM carer grants: the carer grants are intended to allow SIGMM members to fully engage with the online event or attend in person. These grants are intended to cover extra costs to help with caring responsibilities — for example, childcare at home or at the destination — which would otherwise limit your participation in the conference.
SIGMM-sponsored Equality Diversity and Inclusion (EDI) travel grants: these grants aim to support researchers who self-identify as marginalized and/or underrepresented in the MMSys community (e.g., scholars who come from non-WEIRD – Western, Educated, Industrialized, Rich, Developed – societies). The EDI grants have also been used to support researchers who lack other/own funding opportunities, as well as scholars from relevant yet underrepresented research areas.
Paper mentoring: this instrument was primarily aimed at those who are new to submitting an academic paper. In particular, those in circumstances which are particularly adverse, like for example those for whom English is a second language or those who are authoring a particularly novel submission which may require additional input, could apply for paper mentoring.
In addition to the above measures, MMSys’22 also offered excellent mentoring activities for both PhD students and postdocs and more advanced researchers. The PhD mentoring was organized by the doctoral consortium chairs Patrick Le Callet and Carsten Griwodz and PhD students had the possibility to give a short pitch about their PhD research, have discussions with the MMSys’22 mentors and wider community, and have a 1 on 1 in-person talk with their assigned mentor. The postdoc mentoring was organized by Pablo Cesar and Irena Orsolic. Postdocs in the MMSys community were invited to give a lightning talk about their research and were invited to a dedicated networking lunch with other members of the MMSys community. IMX’ 22 on the other hand, featured an open application process for program committee membership and an active reasonable adjustment policy to ensure that registration fees are not preventing people from attending the conference. In addition, undergraduate and graduate students, as well as early-career researchers could also apply for travel support from the SIGCHI Gary Marsden travel awards and PhD students could benefit from interaction with and feedback from peers and senior researchers in the Doctoral Consortium. Finally, both for MMSys and IMX, participants had to actively agree with the ACM Policy Against Discrimination and Harassment.
Activities at the conference
At the conference, additional activities were organized to raise awareness, increase understanding, foster experience sharing and especially also trigger reflection about diversity and inclusion. MMSys ’22 featured a panel on “Designing Inclusivity in Technologies“. Inclusive Design is an approach used in many sectors to try and allow everyone to experience our services and products in an equitable way. One of the ways we could do this is by celebrating diversity in how we design and take into account the different barriers faced by different communities across the globe. The panel brought together experts to discuss what inclusive design looks like for them, the charms of the communities they work with, the challenges they face in designing with and for them and how other communities can learn from the methods they have used in order to build a more inclusive world that benefits all of us. The panellists were:
Veronica Orvalho: Professor at Porto University’s Instituto de Telecomunicações and the Founder/CEO of Didimo – a platform that enables users to generate digital humans.
Nitesh Goyal: Leads research on Responsible AI tools at Google Research.
Kellie Morrissey: Researcher & Lecturer at the University of Limerick’s School of Design.
IMX ’22 featured a panel discussion on “Diversity in the Metaverse”. The Metaverse is a hot topic, which has many people wondering both what it is, and more importantly, what it will look like in the future for immersive media experiences. As a unique space for social interaction, engagement and connection, it’s essential that we address the importance of representation and accessibility during its time of infancy. The discussion intended not only to cover the current scenario in virtual and augmented reality worlds, but also the consequences and challenges of building a diverse Metaverse by taking into account design, content, marketing, and the various barriers faced by different communities across the globe.
The panel was moderated by Tara Collingwoode-Williams (Goldsmiths University) and had four panellists to discuss topics related to research and practice around “Diversity and Inclusive design in the Metaverse”:
Nina Salomons – (Filmmaker, diversity advocate and XR consultant, XRDI, AnomieXR co-founder UK – London)
Micaela Mantegna – (TED Fellow. Video Games Policy/Artificial intelligence, creativity & copyright Professor. AI, XR and Metaverse researcher. BKC Harvard Affiliate. Diversity & Inclusion advocate. Founder of Women In Games, Argentina – Greater Buenos Aires)
Krystal Cooper -( Unity : Emerging Products – Professional Artistry / Virtual production * Spatial Computing * XR researcher * , USA – LA)
Mmuso Mafisa – (XR consultant, Veza Interactive and Venture Chain Capital, SA – Johannesburg Metropolitan Area)
Short testimonials by two of the EDI grant beneficiaries
Soonbin Lee is a PhD student at Sungkyunkwan University (SKKU) in Korea, who would not have been able to attend MMsys ’22 without the SIGMM support (due to a lack of other funding opportunities). Soonbin wrote a short testimonial.
“The conference consisted of the presentation of a keynote and regular sessions by various speakers. In particular, with the advent of cloud gaming, there are many presentations, including: streaming systems specialized in game videos; haptic media for realistic viewing; and humanoid robots that can empathize with humans. During the conference, I enjoyed the spectacular views of Ireland and the wonderful traditional cuisine that was included in the conference program. Along with the presentations during the regular sessions, demo sessions were also presented. Participants from the industry, including Qualcomm, Fraunhofer FOKUS, INRIA, and TNO, were engaged during the MMSys demo sessions. Being able to participate offered also an excellent opportunity to witness the outcomes of real-time systems, including user-interactive VR games, holographic cube matching instructions, and a mobile-based deep learning video codec decoding demo. I was also able to hear the presentations of various PhD research proposals, and it was very impressive to see many PhD students present their interesting research.
At the MMSys conference, there were also a number of social events, like Viking boat and beer-brewing in Ireland, so I was able to meet with other researchers and get to know them better. This was an amazing experience for me because it is not easy to meet the researchers in person. On the last day, I gave a presentation at the NOSSDAV session on the compression processing of MPEG Immersive Video (MIV). Through this discussion and the Q&A, I was able to learn more about the most recent trends in research. More importantly, I made many friends who studied with the same interests. I had a fantastic chance and a wonderful experience meeting other scholars in person. The MMSys Conference was a really impressive conference for me. With the travel grant, I fully enjoyed this opportunity!”
Postdoctoral researcher Alan Guedes also wrote a short reflection: “I am a researcher from the Brazilian multimedia community, especially concentrated at the WebMedia event (http://webmedia.org.br). Although my community is considerably large and active, it has little presence at ACM events. This lack prevents the visibility of our research and possible international collaboration. In 2022, I was honoured with ACM Diversity and Inclusion Travel Award to attend two ACM SIGMM-supported conferences, namely IMX and MMSys. The events had inspiring presentations and keynotes, which made me energetic about new research directions. Particularly, I had the chance to meet researchers that I only know by their citing names. At these events, I could present some research done in Brazil and collaborate on technical committees and workshops.
This networking was invaluable and will be essential in my research career. I was also happy to see other Brazilians that, like me, seek to engage and strengthen the bonds of SIGMM and Brazilian communities.”
Final reflections
Both at IMX and MMSys, there were various actions and initiatives to put EDI-related topics on the agenda and to foster diversity and inclusion, both at the community level and in terms of research-related activities. We believe that a key success factor in this respect is the fact that there are valuable support mechanisms offered by the ACM and SIGMM, allowing the IMX and MMSys communities to continuously and systematically have goals related to equality, diversity and inclusion on the agenda, e.g., by removing participation barriers (e.g., by having adjusted prices depending on the country of the attendees), triggering awareness, providing a forum for under-represented voices and/or regions (e.g., focused workshops at IMX focusing on Asia (2016, 2017), Latin America (2020), .., supported by the SIGCHI Development Fund).
Based on our experiences, it is also important that defined actions and measures are based on a good understanding of the key problems. This means that efforts to gain insights into key aspects (e.g., gender balance, numbers on the participation of under-represented groups, …) and developments over time are highly valuable. Secondly, it is important that EDI aspects are considered holistically, as they relate to all aspects of the conference, from the beginning until the end, including e.g., the selection of keynote speakers, the matter of who is represented in the technical committees (e.g., have an open call for associate chairs as has been done at IMX since the beginning), or who is represented in the organizing committee, which efforts are done to reach out to relevant communities in various parts of the world that are currently under-represented (e.g., South-America, Afrika,…). Lastly, we need more experience sharing through both formal and informal channels. There is a huge potential to share best practices and experiences both within and between the related conferences and communities to combine our efforts towards a common EDI vision and associated goals.
The 13th ACM Multimedia Systems Conference (and associated workshops: MMVE 2022, NOSSDAV 2022, GameSys 2022) happened from 14th – 17th June 2022 in Athlone, Ireland. The MMSys conference is an essential forum for researchers in multimedia systems to present and share their latest research findings in multimedia systems. After two years of online and hybrid editions, MMSys was held onsite in the beautiful Athlone. Besides the many high-quality technical talks spread across different multimedia areas and the wonderful keynote talks, there were a few events targeted especially at students, such as mentoring sessions and the doctoral symposium. The social events were significant this year since they were the first opportunity in two years for multimedia researchers to meet colleagues, collaborators, and friends and discuss the latest hot topics while sharing a pint of Guinness or a glass of wine.
To encourage student authors to participate on-site, SIGMM has sponsored a group of students with Student Travel Grant Awards. Students who wanted to apply for this travel grant needed to submit an online form before the submission deadline. The selected students received either 1,000 or 2,000 USD to cover their airline tickets as well as accommodation costs for this event. Of the recipients, 11 were able to attend the conference. We asked them to share their unique experience attending MMSys’22. In this article, we share their reports of the event.
Andrea M. Storås, PhD student, Oslo Metropolitan University, Norway
I am grateful for receiving the SIGMM Student Travel Grant and getting the opportunity to participate at the MMSys’ 2022 Conference in Athlone, Ireland. During the conference, I presented my research as a part of the Doctoral Symposium and got valuable advice and mentoring from an experienced professor in the field of multimedia systems. The Doctoral Symposium was a great place for me to get experience with pitching my research and presenting posters at a scientific conference.
In addition to inspiring talks and demos, the conference was filled with social events. One of the highlights was the boat trip to the Glasson Lake House with barbeque afterwards. I found the conference useful for my future career as I got to meet brilliant researchers, connect with other PhD students and discuss topics related to my PhD. I really hope that I will get the opportunity to participate in future editions of MMSys.
Reza Farahani, PhD student, ITEC Dept., Alpen-Adria-University Klagenfurt, Austria
After two years of virtual attendance in ACM MMSys, I had the opportunity to be in Athlone, Ireland, and present our work in front of the community. Like previous years, I expected a well-organized conference, and I witnessed everything from keynotes to papers sessions was perfect. Moreover, the social events were one of the best experiences I achieved, where I could discuss with community members and learn many things in a friendly atmosphere. Overall, I must express that the MMSys 2022 was excellent in all aspects, and I appreciate the SIGMM committee once again for the nice travel grant which made this experience possible.
Xiaokun Xu, PhD student, Worcester Polytechnic Institute, USA
The MMsys2022 was my first in-person conference, and it was very well organized and far more than my expectation for an in-person conference since in the past 2 years I participated in some virtual conferences and they were not very good experiences. I thought the in-person conference would be similar. The fact is that I was totally wrong. MMsys2022 was a wonderful experience, the first time I built a real connection with the community and peer researchers. Many things impressed me a lot. For the papers and presentations, I found the poster #75 “Realistic Video Sequences for Subjective QoE Analysis” was really interesting to me. The presentation from the author was very helpful and I talked a lot with the author. Now he is one of my new friends I made from the conference and we still keep in communication through email. Besides the papers, social events were another part that impressed me. All the social events were highly organized and made communication easier for us. I got the opportunity to talk with the authors and ask some questions that I didn’t ask during the presentation, and made some new friends who are doing similar research as me. I also got the chance to talk with some professors who are the top researchers in specific fields. Those are really precious experiences for a PhD student. Overall, MMSys 2022 was an amazing conference and now it’s an encouragement for me to attend more academic communication in future. I’m really grateful to the SIGMM committee for the travel grant, which made this wonderful experience possible.
Sindhu Chellappa, PhD student, University of New Hampshire, US
I am really happy to be part of MMSys at Athlone, Ireland. This is the first in-person conference I have attended after the pandemic. The conference was organized seamlessly, and the keynotes were very interesting. The keynote “Network is the Renderer” by Dr Morgan from Roblox stole the entire show. Along with that, the keynotes by Dr Ali and Dr Mohamed Hefeeda on Low latency streaming and DeepGame respectively were very interesting. The social events were very relaxing and well organized. I had to travel from the US to India and to Ireland. It was a breathtaking trip, but with the student travel grant, it was a boon to attend the conference in-person.
Tzu-Yi Fan, master student, National Tsing Hua University, Taiwan
I am grateful to receive the student grant for MMSys 2022, which was my first in-person conference. I learned a lot at the conference and had a wonderful experience in Athlone, Ireland. Initially, I felt nervous when I arrived in a distant and unfamiliar place, but the kind and welcomed organization calmed my mind. The schedule of the conference was fruitful. I enjoyed the presentations and keynotes a lot. I presented my paper about high-rise firefighting in the special session. Although I did not speak smoothly at the beginning, I still enjoyed interacting with the audience. Keynote given by Professor Mohamed impressed me a lot. He spoke about the challenges of cloud gaming and introduced a video encoding pipeline to reduce the bandwidth. I also loved the coffee break between sessions. During that time, people worldwide could discuss each other’s research, which I could not do in virtual participation. It was an excellent opportunity to practice demonstrating our research to people from different backgrounds. Moreover, the social events at night were also exciting. I tasted several kinds of beer at the welcome party. Ireland is famous for beer. I was glad to try the local flavour, which I never thought beer could be. Thank the MMSys 2022 organization for holding such a splendid conference and expanding my horizons. I look forward to carrying on my new research and joining more conferences in the future.
Kerim Hodžić, PhD student, University of Sarajevo, Bosnia and Herzegovina
My name is Kerim Hodžić, and I am a PhD student at the Faculty of Electrical Engineering, Computer Science Department at the University of Sarajevo, Bosnia and Herzegovina. It was my pleasure to attend the ACM/MMSYS 2022 conference held in Athlone, Ireland where I presented my paper „Realistic Video Sequences for Subjective QoE Analysis” which is part of my PhD research. In addition to that, I had an opportunity to learn much from attending all the conference sessions with very interesting paper presentations and also from the special guests who provided us with interesting information about the industry. In social events, I met many people from industry and academia and I hope it will lead to some useful cooperation in the future. This is the best conference I have attended so far in my career and I want to congratulate everyone who organised it. I also want to thank the SIGMM committee for their travel grant, which made this experience possible. Till the next MMSYS! All the best.
Juan Antonio De Rus Arance, Universitat Politècnica de València, Spain
MMSys’2022 was an amazing experience and a great opportunity to discover other research works in my field. It gave me the chance to meet colleagues working in the same area and discuss ideas with them, opening the doors to possible collaborations. Moreover, participating in the Doctoral Symposium was very didactic. It wouldn’t have been possible for me to attend the conference if it wasn’t for the SIGMM Student travel award and I’m very grateful.
Miguel Fernández Dasí, PhD student, Universitat Politècnica de Catalunya, Spain
I am a PhD student at the Universitat Politècnica de Catalunya, and MMSys 2022 was my first in-person conference. I attended the Doctoral Symposium to present my paper, “Design, development and evaluation of adaptive and interactive solutions for high-quality viewport-aware VR360 video processing and delivery”. It was a great experience meeting fellow PhD students and sharing ideas about different topics, especially with those working in the same area. Furthermore, everyone at the conference was always willing to talk, which I have significantly appreciated as a PhD student and that always led to fascinating conversations. All the keynotes were engaging. I was particularly interested in Prof. Mohamed Hefeeda’s “DeepGame: Efficient Video Encoding for Cloud Gaming” keynote, a topic related to my PhD thesis. I also found Prof. Nadia Magnenat Thalmann’s keynote on “Digital and Robotic Humanoid Twins: for Which Purposes” interesting, a topic I didn’t know about but found great interest in. I am thankful to SIGMM for receiving the Student Travel Grant, which made my attendance at this conference possible.
Melan Vijayaratnam, PhD student, CentraleSupelec, France
I am delighted to have been given a grant for the MMSys conference in Athlone, Ireland. This was my first in-person conference that my supervisor Dr Giuseppe Valenzise really wanted me to attend to meet with the Multimedia community. I went there by myself and it was scary at first to go to the conference without knowing anyone at first. However, being on the doctoral symposium track, my mentor Dr Pablo Cesar helped me with his advice and introduced me to many people and I got to meet other fellow PhD students. It was definitely an incredible experience and I am grateful to have been introduced to this welcoming community.
Chun Wei Ooi, PhD student, Trinity College Dublin, Ireland
It was my first time attending the MMsys conference this year. I would like to thank the committee for awarding the travel grants to students such as myself. I presented my research topic at MMVE and received some good suggestions from senior researchers. It was a very fruitful conference where I met different researchers from different backgrounds and levels. I also benefited tremendously from attending the conference because my latest work is partly inspired by the research talk I attended. One of the highlights of attending MMsys in person is its many social events. Not only did they show the best side of the venue, but more importantly I was able to make friends with fellow researchers. Overall MMsys community is a very talented and friendly bunch, I am glad to be a part of it.
Jingwen Zhu, PhD student, Nantes university, France
I was very disappointed that I didn’t receive my visa until the day before the MMSys. However, I got a call from the embassy on the first day of the conference, telling me that my visa application was approved. I shared the news with my supervisor Patrick Le Callet, who insisted that I should buy the next plane to come to the conference and present my research proposal in person.
MMSys is the first conference for me since the beginning of my PhD. As a first-year PhD student, it was a very good opportunity for me to know this excellent community and exchange my research with more experienced researchers. I really appreciate the breakfast with my mentor Dr Ketan Mayer-Patel. He gave me very nice suggestions for my PhD during breakfast. After the conference, he still sent me a good tutorial about how to make a good academic poster. I would like to thank the conference organizers and the travel grand for giving me the opportunity to meet everyone in person. Thanks to everyone who exchanged ideas with me during the conference and especially my DS mentor Ketan. I hope that I can continue to attend MMSys next year!
This short article reports on lessons learned from a multidisciplinary hands-on course that I co-taught in the academic winter term 2021/2022. Over the course of the term, I co-advised a group of 4 students who explored designing interfaces for Musiklusion [1], a project focused on inclusive music making using digital tools. Inclusive participation in music making processes is a topic home to the Multimedia community, as well as many neighbouring disciplines (see e.g. [2,3]). In the following, I briefly detail the curriculum, describe project Musiklusion, outline challenges and report on the course outcome. I conclude by summarizing a set of personal observations from the course—albeit anecdotal—that could be helpful for fellow teachers who wish to design a hands-on course with inclusive design sessions.
When I rejoined academia in 2020, I got the unique possibility to take part in teaching activities pertaining to, i.a., human-centered multimedia within a master’s curriculum on Human Factors at Furtwangen University. Within this 2-year master’s programme, one of the major mandatory courses is a 4-month hands-on course on Human Factors Design. I co-teach this course jointly with 3 other colleagues from my department. We expose students to multi-disciplinary research questions which they must investigate empirically in groups of 4-6. They have to come up with tangible results, e.g. a prototype or qualitative and quantitative data as empirical evidence.
Last term, each of us docents advised one group of students. Each group was also assigned an external partner to help ground the work and embed it into a real-world use case. The group of students I had the pleasure to work with partnered with Musiklusion’s project team. Musiklusion is an inclusive project focused on accessible music making with digital tools for people with so-called disabilities. They work and make music alongside people without any disabilities. These disabilities pertain e.g. to cognitive disabilities and impairments of motor skills with conditions continuing to progress. Movement, gestures and, eventually tasks, that can be performed today (e.g. being able to move one’s upper body) cannot be taken for granted in the future. Thus, as an overarching research agenda for the course project, the group of students explored the design and implementation of digital interfaces that enable people with cognitive and/or motor impairments to actively participate in music making processes and possibly sustain their participation in the long run depending on their physical abilities.
Project Musiklusion is spearheaded by musician and designer Andreas Brand [4], partnering with Lebenshilfe Tuttlingen [5]. The German Lebenshilfe is a nation-wide charitable association for people with so-called disabilities. Musiklusion’s project team makes two salient contributions: (i) orchestrating off-the-shelf instruments such that they are “programmable” and (ii) designing, developing and implementing digital interfaces that enable people with so-called disabilities to make music using said instruments. The project’s current line-up of instruments (cf. Figure 1) comprises a Disklavier with a Midi port and an enhanced drum set with drivers and mechanical actuators [6]. Both instruments can be controlled using MAX/MSP through OSC. Hence tools like TouchOSC [7] can be leveraged to design 2D widget-based graphical user interfaces to control each instrument. While a musician with impaired motor skills in the upper body might not be able to play individual notes using a touch interface or the actual Disklavier for instance, digital interfaces and widgets can be used to vary e.g. pitch or pace of themes.
With sustainable use of the above instruments in mind, the group of students aimed to explore alternative input modalities that could be used redundantly depending on a musician’s motor skills. They conducted weekly sessions with project members of Musiklusion over the course of about 2.5 months. Most of the project members use a motorized wheelchair and have limited upper body movement. Each session ran from 1 to 3 hours, depending on availability of project members and typically 2-5 members were present. The sessions took place at Lebenshilfe Tuttlingen, where the instruments were based at and used on daily basis. Based on in-situ observations and conversations, the group of students derived requirements and user needs to inform interface designs. They also led weekly co-design sessions where they prototyped both interfaces and interactions and tried them out with project members, respectively. Reporting on the actual iterative design sessions, the employed methodology (cf. [8,9]), as well as data gathered is beyond this short article and should be presented at a proper venue focusing on human-centred multimedia. Yet, to provide a glimpse on to the results: the group of students came up with a set of 4 different interfaces that cater to individual abilities and can be used redundantly with both the Disklavier and the drum kit. They designed (a) body-based interactions that can be employed while sitting in a motorized wheelchair, (b) motion-based interactions that leverage accelerometer and gyroscope data of e.g. a mobile phone held in hand or strapped to an upper arm, (c) an interface that leverages face mimics, relying on face tracking and (d) an eye-tracking interface that leverages eye movement for interaction. At the end of the course, and amidst the corona pandemic, these interfaces were used to enable the Musiklusion project members to team up with artists and singers Tabea Booz and Sharon to produce a music video remotely. The music video is available at https://www.youtube.com/watch?v=RYaTEYiaSDo and showcases the interfaces in actual productive use.
In the following, I enumerate personal lessons learned as an advisor and course instructor. Although these observations only steam from a single term and single group of students, I still find them worthwhile to share with the community.
Grounding of course topic is key. Teaming up with an external partner who provides a real-world use case had a tremendous impact on how the project went. The course could have also taken place without involving Musiklusion’s project members and actual instruments—designs and implementations would then have suffered from a low external validity. Furthermore, this would have rendered conduction of co-design sessions impossible.
Project work must be meaningful and possibly impactful. The real-world grounding of the project work and therefore also pressure to deliver progress to Musiklusion’s project members kept students extrinsically motivated. However, I observed students being engaged on a very high level and going above and beyond to deliver constantly improved prototypes. From conversations I had, I felt that both meaningfulness of their work and the impact they had motivated them intrinsically.
Course specifications should be tailored towards interests to acquire skills of course members. It might seem obvious (cf. [10]), but this course made me again realize how important it is to cater to the interest of students in acquiring new skills and match their interest to course specifications (cite Teaching college). The outcome of this project would have been entirely different, if students were not interested in learning how to build, deliver and test-drive prototypes iteratively at a high pace. This certainly also served as an additional intrinsic motivation.
In conclusion, teaching this course was a unique experience for me, as well as for the student members involved in the course work. It was certainly not my first hands-on course that I had taught. Also, hands-on course work is home to many HCI curricula across the globe. But I hope that this anecdotal report further inspires fellow teachers to partner with (charitable) organizations to co-teach modules and have them sponsor real-world use cases that motivate students both extrinsically and intrinsically.
Acknowledgements
I want to extend special thanks to participating students Selina Layer, Laura Moosmann, Marvin Shopp and Tobias Wirth, as well as Andreas Brand, Musiklusion project members and Lebenshilfe Tuttlingen.
[2] Hornof A, Sato L. (2004). EyeMusic: making music with the eyes. In: Proceedings of the 2004 conference on New interfaces for musical expression, pp 185–188.
[3] Petry, B., Illandara, T., & Nanayakkara, S. (2016, November). MuSS-bits: sensor-display blocks for deaf people to explore musical sounds. In Proceedings of the 28th Australian Conference on Computer-Human Interaction(pp. 72-80).
[4] Personal webpage of Andreas Brand. https://andybrand.de. Last accessed: June 28, 2022.
[8] Veytizou J, Magnier C, Villeneuve F, Thomann G. (2012). Integrating the human factors characterization of disabled users in a design method. Application to an interface for playing acoustic music. Association for the Advancement of Modelling and Simulation Techniques in Enterprises 73:173.
[9] Gehlhaar R, Rodrigues PM, Girão LM, Penha R. (2014). Instruments for everyone: Designing new means of musical expression for disabled creators. In: Technologies of inclusive well-being. Springer, pp 167–196.
[10] Eng, N. (2017). Teaching college: The ultimate guide to lecturing, presenting, and engaging students.
About the Column
The Multidisciplinary Column is edited by Cynthia C. S. Liem and Jochen Huber. Every other edition, we will feature an interview with a researcher performing multidisciplinary work, or a column of our own hand. For this edition, we feature a column by Jochen Huber.
Editor Biographies
Dr. Cynthia C. S. Liem is an Assistant Professor in the Multimedia Computing Group of Delft University of Technology, The Netherlands, and pianist of the Magma Duo. She initiated and co-coordinated the European research project PHENICX (2013-2016), focusing on technological enrichment of symphonic concert recordings with partners such as the Royal Concertgebouw Orchestra. Her research interests consider music and multimedia search and recommendation, and increasingly shift towards making people discover new interests and content which would not trivially be retrieved. Beyond her academic activities, Cynthia gained industrial experience at Bell Labs Netherlands, Philips Research and Google. She was a recipient of the Lucent Global Science and Google Anita Borg Europe Memorial scholarships, the Google European Doctoral Fellowship 2010 in Multimedia, and a finalist of the New Scientist Science Talent Award 2016 for young scientists committed to public outreach.
Dr. Jochen Huber is Professor of Computer Science at Furtwangen University, Germany. Previously, he was a Senior User Experience Researcher with Synaptics and an SUTD-MIT postdoctoral fellow in the Fluid Interfaces Group at MIT Media Lab and the Augmented Human Lab at Singapore University of Technology and Design. He holds a Ph.D. in Computer Science and degrees in both Mathematics (Dipl.-Math.) and Computer Science (Dipl.-Inform.), all from Technische Universität Darmstadt, Germany. Jochen’s work is situated at the intersection of Human-Computer Interaction and Human Augmentation. He designs, implements and studies novel input technology in the areas of mobile, tangible & non-visual interaction, automotive UX and assistive augmentation. He has co-authored over 60 academic publications and regularly serves as program committee member in premier HCI and multimedia conferences. He was program co-chair of ACM TVX 2016 and Augmented Human 2015 and chaired tracks of ACM Multimedia, ACM Creativity and Cognition and ACM International Conference on Interface Surfaces and Spaces, as well as numerous workshops at ACM CHI and IUI. Further information can be found on his personal homepage: http://jochenhuber.com
This issue of the Dataset Column provides two interviews with the researchers responsible for novel datasets of recent years. In particular, we first interview Nacho Reimat (https://www.cwi.nl/people/nacho-reimat), the scientific programmer responsible for the CWIPC-SXR, one of the first datasets on dynamic, interactive volumetric media. Second, we interview Pierre-Etienne Martin (https://www.eva.mpg.de/comparative-cultural-psychology/staff/pierre-etienne-martin/), responsible for contributions to datasets in the area of sports and culture.
The two interviewees were asked about their contribution to the dataset research, their interests, challenges, and the future. We would like to thank both Nacho and Pierre-Etienne for their agreement to contribute to our column.
Nacho Reimat, Scientific Programmer at the Distributed and Interactive Systems group at the CWI, Amsterdam, The Netherlands
Short bio: Ignacio Reimat is currently an R&D Engineer at Centrum Wiskunde & Informatica (CWI) in Amsterdam. He received the B.S. degree in Audiovisual Systems Engineering of Telecommunications at Universitat Politecnica de Catalunya in 2016 and the M.S degree in Innovation and Research in Informatics – Computer Graphics and Virtual Reality at Universitat Politecnica de Catalunya in 2020. His current research interests are 3D graphics, volumetric capturing, 3d reconstruction, point clouds, social Virtual Reality and real-time communications.
Could you provide a small summary of your contribution to the dataset research?
We have released the CWI Point Cloud Social XR Dataset [1], a dynamic point cloud dataset that depicts humans interacting in social XR settings. In particular, using commodity hardware we captured audio-visual data (RGB + Depth + Infrared + synchronized Audio) for a total of 45 unique sequences of people performing scripted actions [2]. The screenplays for the human actors were devised so as to simulate a variety of common use cases in social XR, namely, (i) Education and training, (ii) Healthcare, (iii) communication and social interaction, and (iv) Performance and sports. Moreover, diversity in gender, age, ethnicities, materials, textures and colours were additionally considered. As part of our release, we provide annotated raw material, resulting point cloud sequences, and an auxiliary software toolbox to acquire, process, encode, and visualize data, suitable for real-time applications.
Sample frames from the point cloud sequences released with the CWIPC-SXR dataset.
Why did you get interested in datasets research?
Real-time, immersive telecommunication systems are quickly becoming a reality, thanks to the advances in the acquisition, transmission, and rendering technologies. Point clouds in particular serve as a promising representation in these types of systems, offering photorealistic rendering capabilities with low complexity. Further development of transmission, coding, and quality evaluation algorithms, though, is currently hindered by the lack of publicly available datasets that represent realistic scenarios of remote communication between people in real-time. So we are trying to fill this gap.
What is the most challenging aspect of datasets research?
In our case, because point clouds are a relatively new format, the most challenging part has been developing the technology to generate them. Our dataset is generated from several cameras, which need to be calibrated and synchronized in order to merge the views successfully. Apart from that, if you are releasing a large dataset, you also need to deal with other challenges like data hosting and maintenance, but even more important, find the way to distribute the data in a way that is suitable for different target users. Because we are not releasing just point clouds but also the raw data, there may be people interested in the raw videos, or in particular point clouds, and they do not want to download the full 1.6TB of data. And going even further, because of the novelty of the point cloud format, there is also a lack of tools to re-capture, playback or modify this type of data. That’s why, together with the dataset, we also released our point cloud auxiliary toolbox of software utilities built on top of the Point Cloud Library, which allows for alignment and processing of point clouds, as well as real-time capturing, encoding, transmission, and rendering.
How do you see the future of datasets research?
Open datasets are an essential part of science since they allow for comparison and reproducibility. The major problem is that creating datasets is difficult and expensive, requiring a big investment from research groups. In order to ensure that relevant datasets keep on being created, we need a push including: scientific venues for the publication and discussion of datasets (like the dataset track at the Multimedia Systems conference, which started more than a decade ago), investment from funding agencies and organizations identifying the datasets that the community will need in the future, and collaboration between labs to share the effort.
What are your future plans for your research?
We are very happy with the first version of the dataset since it provides a good starting point and was a source of learning. Still, there is room for improvements, so now that we have a full capturing system (together with the auxiliary tools), we would like to extend the dataset and refine the tools. The community still needs more datasets of volumetric video to further advance the research on alignment, post-processing, compression, delivery, and rendering. Apart from the dataset, the Distributed and Interactive Systems (https://www.dis.cwi.nl) group from CWI is working on volumetric video conferencing, developing a Social VR pipeline for enabling users to more naturally communicate and interact. Recently, we deployed a solution for visiting museums remotely together with friends and family members (https://youtu.be/zzB7B6EAU9c), and next October we will start two EU-funded projects on this topic.
Pierre-Etienne Martin, Postdoctoral Researcher & Tech Development Coordinator, Max Planck Institute for Evolutionary Anthropology, Department of Comparative Cultural Psychology, Leipzig, Germany
Short Bio: Pierre-Etienne Martin is currently a Postdoctoral researcher at the Max Planck Institute. He received his M.S. degree in 2017 from the University of Bordeaux, the Pázmány Péter Catholic University and the Autonomous University of Madrid via the Image Processing and Computer vision Erasmus Master program. He obtained his PhD, labelled European, from the University of Bordeaux in 2020, supervised by Jenny Benois-Pineau and Renaud Péteri, on the topic of video detection and classification by means of Convolutional Neural Networks. His current research interests include among others Artificial Intelligence, Machine Learning and Computer Vision.
Could you provide a small summary of your contribution to the dataset research?
In 2017, I started my PhD thesis which focuses on movement analysis in sports. The aim of this research project, so-called CRIPS (ComputeR vIsion for Sports Performance – see ), is to improve the training experience of the athletes. Our team decided to focus on Table Tennis, and it is with the collaboration of the Sports Faculty of the University of Bordeaux, STAPS, that our first contribution came to be: the TTStroke-21 dataset [3]. This dataset gathers recordings of table tennis games at high resolution and 120 frames per second. The players and annotators are both from the STAPS. The annotation platform was designed by students from the LaBRI – University of Bordeaux, and the MIA from the University of la Rochelle. Coordination for recording the videos and doing the annotation was performed by my supervisors and myself.
In 2019, and until now, the TTStroke-21 is used to propose the Sports Task at the Multimedia Evaluation benchmark – MediaEval [4]. The goal is to segment and classify table tennis strokes from videos.
TTStrokes-21 sample images
Since 2021, I have joined the MPI EVA institute and I now focus on elaborating datasets for the Comparative Cultural Psychology department (CCP). The data we are working on focuses on great apes and children. We aim at segmenting, identifying and tracking.
Why did you get interested in datasets research?
Datasets research is the field where the application of computer vision tools is possible. In order to widen the range of applications, datasets with qualitative ground truth need to be offered by the scientific community. Only then, models can be developed to solve the problem raised by the dataset and finally be offered to the community. This has been the goal of the interdisciplinary CRISP project, through the collaboration of the sport and computer science community, for improving athlete performance.
It is also the aim of collaborative projects, such as MMLAB [5], which gathers many models and implementations trained on various datasets, in order to ease reproducibility, performance comparison and inference for applications.
What is the most challenging aspect of datasets research?
From my experience, when organizing the Sport task at the MediaEval workshop, the most challenging aspect of datasets research is to be able to provide qualitative data: from acquisition to annotation; and tools to process them: use, demonstration and evaluation. That is why, on the side of our task, we also provide a baseline which covers most of these aspects.
How do you see the future of datasets research?
I hope datasets research will transcend in order to have a general scheme for annotation and evaluation of datasets. I hope the different datasets could be used together for training multi-task models, and give the opportunity to share knowledge and features proper to each type of dataset. Finally, quantity has been a major criterion for dataset research, but quality should be more considered in order to improve state-of-the-art performance while keeping a sustainable way to conduct research.
What are your future plans for your research?
Within the CCP department at MPI, I hope to be able to build different types of datasets to put to best use what has been implemented in the computer vision field to psychology.
I. Reimat, et al., “CWIPC-SXR: Point Cloud dynamic human dataset for Social XR. In Proceedings of the 12th ACM Multimedia Systems Conference (MMSys ’21). Association for Computing Machinery, New York, NY, USA, 300–306. https://doi.org/10.1145/3458305.3478452
The Special Interest Group in Multimedia of ACM, ACM SIGMM, provides a forum for researchers, engineers, and practitioners in all aspects of multimedia computing, communication, storage, and applications. We do this through our sponsorship and organization of conferences and workshops, supporting student travel to such events, discounted registrations, two regional chapters, recognition of excellence and achievement through an awards scheme, and we inform the Multimedia community of our activities through the SIGMM Records, social media and through mailing lists. Information on joining SIGMM can be found at https://www.acm.org/special-interest-groups/sigs/sigmm.
The SIGMM Executive Committee Newsletter in SIGMM Records periodically reports on the topics discussed and the decisions assumed in the Executive Committee meetings to improve transparency and sense of community.
SIGMM Executive Committee Meeting 2022-03-16
Attended:Alberto Del Bimbo (Chair); Phoebe Chen (Vice-Chair); Miriam Redi (Conference Director); Changsheng Xu, Ketan Mayer-Patel, Kiyoharu Aizawa, Pablo Cesar, Prabhakaran, Balakrishnan, Qi Tian, Susanne Boll, Tao Mei, Abdulmotaleb El Saddik, Alan Smeaton (SIGMM Executive Committee members); Xavier Alameda Pineda (Invited guest)
Sent justification and comments: Lexing Xie (SIGMM Executive Committee member).
We discussed the 2022 SIGMM budget. The SIGMM budget is in a good shape, and we foresee room for new initiatives to strengthen and expand the SIGMM community and improve our communication via existing and new channels.
We approved a revision of SIGMM bylaws (proposed by Susanne Boll) to improve diversity: the chair and vice-chair will run for the offices in pairs; a way to encourage diversity without necessarily having to put quota. The proposal has been sent to ACM for approval.
We approved three proposals for special initiatives that will improve inclusion. In late 2021, the SIGMM Executive invited SIGMM Members to apply for funding for new initiatives building on SIGMM’s excellence and strengths, nurturing new talent in the SIGMM community, and addressing weaknesses in the SIGMM community and in SIGMM activities. The fund can support auditable expenses incurred and necessary for the completion of the initiative. The proposals received were evaluated based on impact and contribution to the SIGMM community, and cost-effectiveness of the proposed budget. The three special initiatives approved so far are:
Multi-City PhD-School(proposed by the Steering Committee Co-Chairs of MM Asia) This is a two-half day program which is planned to be implemented in ACM MM Asia and eventually applied to other conferences in the future. The program is hosted in 3-5 satellite sites located in different Asian cities. Each site will physically gather 30-50 PhD students plus 1-2 senior researchers in a local venue. Different sites are virtually connected by online meetings. Invited student speakers will deliver a 3-minute lightning talk in turn followed by QA talks with mentors. The program allows students to physically attend the event, talk to senior researchers, while increasing the impact of satellite events among young researchers. Students are encouraged to register for the satellite events and attend virtually. This could involve more students and minority attendees with satellite events bringing students from multiple cities for idea exchange and research training
MMSys inclusion initiative (proposed by the MMSys’22 General Chairs & Diversity Chairs) The goal of this initiative is to improve diversity and inclusion in the MMSys community. The proposal includes 1) Travel support for non-student participants who self-identify as marginalized and/or underrepresented, lacking other funding opportunities; 2) an EDI (Equality, Diversity and Inclusion) panel aiming at increasing visibility and recognition of minorities and under-represented researchersin SIGMM fields, stimulating new collaborations; and promoting networking and mentoring between junior and senior researchers.
IMX Inclusion initiative (proposed by the IMX’22 Diversity Chairs) The goal of this initiative is to promote the participation of groups of students and researchers that have historically been underrepresented in the IMX’s community. The proposal includes funding for 1) a panel discussion on diversity in the metaverse; 2) travel support for individuals who self-identify as marginalized and/or underrepresented in terms of gender, race, and geographical location and who lack the financial resources to attend an international conference.
The SIGMM Executive also discussed two other initiatives, namely the opportunity of using Open Review in the SIGMM flagship conference ACM Multimedia (this year it is adopted on an experimental basis in ACMMM 2022), and the project of a reproducibility platform for open streaming evaluation and benchmarking (proposed by Ali Begen) eventually extendible beyond streaming media. They both will be further discussed and evaluated in the next future.
JPEG issues a call for proposals for JPEG Fake Media
The 95th JPEG meeting was held online from 25 to 29 April 2022. A Call for Proposals (CfP) was issued for JPEG Fake Media that aims at a standardisation framework for secure annotation of modifications in media assets. With this new initiative, JPEG endeavours to provide standardised means for the identification of the provenance of media assets that include imaging information. Assuring the provenance of the coded information is essential considering the current trends and possibilities on multimedia technology.
Fake Media standardisation aims the identification of image provenance.
This new initiative complements the ongoing standardisation of machine learning based codecs for images and point clouds. Both are expected to revolutionise the state of the art of coding standards, leading to compression rates beyond the current state of the art.
The 95th JPEG meeting had the following highlights:
JPEG Fake Media issues a Call for Proposals;
JPEG AI
JPEG Pleno Point Cloud Coding;
JPEG Pleno Light Fields quality assessment;
JPEG AIC near perceptual lossless quality assessment;
JPEG NFT exploration;
JPEG DNA explorations
JPEG XS 2nd edition published;
JPEG XL 2nd edition.
The following summarises the major achievements of the 95th JPEG meeting.
JPEG Fake
Media
At
its 95th JPEG meeting, the committee issued a Final Call for Proposals (CfP) on
JPEG Fake Media. The scope of JPEG Fake Media is the creation of a standard
that can facilitate the secure and reliable annotation of media asset creation
and modifications. The standard shall address use cases that are in good faith
as well as those with malicious intent. The call for proposals welcomes
contributions that address at least one of the extensive list of requirements
specified in the associated “Use Cases and Requirements for JPEG Fake Media”
document. Proponents are highly encouraged to express their interest in
submission of a proposal before 20 July 2022 and submit their final proposal
before 19 October 2022. Full details about the timeline, submission
requirements and evaluation processes are documented in the CfP available on
jpeg.org.
JPEG AI
Following the JPEG AI joint ISO/IEC/ITU-T Call for
Proposals issued after the 94th JPEG committee meeting, 14 registrations were
received among which 12 codecs were submitted for the standard reconstruction
task. For computer vision and image processing tasks, several teams have
submitted compressed domain decoders, notably 6 for image classification. Prior
to the 95th JPEG meeting, the work was focused on the management of the Call
for Proposals submissions and the creation of the test sets and the generation
of anchors for standard reconstruction, image processing and computer vision
tasks. Moreover, a dry run of the subjective evaluation of the JPEG AI anchors
was performed with expert subjects and the results were analysed during this
meeting, followed by additions and corrections to the JPEG AI Common Training
and Test Conditions and the definition of several recommendations for the
evaluation of the proposals, notably, the anchors, images and bitrates
selection. A procedure for cross-check evaluation was also discussed and
approved. The work will now focus on the evaluation of the Call for Proposals
submissions, which is expected to be finalized at the 96th JPEG meeting.
JPEG Pleno Point Cloud Coding
JPEG
Pleno is working towards the integration of various modalities of plenoptic
content under a single and seamless framework. Efficient and powerful point
cloud representation is a key feature within this vision. Point cloud data
supports a wide range of applications for human and machine consumption
including metaverse, autonomous driving, computer-aided manufacturing,
entertainment, cultural heritage preservation, scientific research and advanced
sensing and analysis. During the 95th JPEG meeting, the JPEG Committee reviewed
the responses to the Final Call for Proposals on JPEG Pleno Point Cloud Coding.
Four responses have been received from three different institutions. At the
upcoming 96th JPEG meeting, the responses to the Call for Proposals will be
evaluated with a subjective quality evaluation and objective metric
calculations.
JPEG Pleno Light Field
The JPEG Pleno standard tools provide a
framework for coding new imaging modalities derived from representations
inspired by the plenoptic function. The image modalities addressed by the
current standardization activities are light field, holography, and point
clouds, where these image modalities describe different sampled representations
of the plenoptic function. Therefore, to properly assess the quality of these
plenoptic modalities, specific subjective and objective quality assessment
methods need to be designed.
In this context, JPEG has launched a new
standardisation effort known as JPEG Pleno Quality Assessment. It aims at
providing a quality assessment standard, defining a framework that includes subjective
quality assessment protocols and objective quality assessment procedures for
lossy decoded data of plenoptic modalities for multiple use cases and
requirements. The first phase of this effort will address the light field
modality.
To assist this task, JPEG has issued the
“JPEG Pleno Draft Call for Contributions on Light Field Subjective Quality
Assessment”, to collect new procedures and best practices with regard to
light field subjective quality assessment methodologies to assess artefacts
induced by coding algorithms. All contributions, which can be test procedures,
datasets, and any additional information, will be considered to develop the
standard by consensus among the JPEG experts following a collaborative process
approach.
The Final Call for Contributions will be
issued at the 96th JPEG meeting. The deadline for submission of contributions
is 18 December 2022.
JPEG AIC
During the 95th JPEG Meeting, the committee released
the Draft Call for Contributions on Subjective Image Quality Assessment.
The new JPEG AIC standard will be developed
considering all the submissions to the Call for Contributions in a
collaborative process. The deadline for the submission is set for 14 October
2022. Multiple types of contributions are accepted, notably subjective
assessment methods including supporting evidence and detailed description, test
material, interchange format, software implementation, criteria and protocols
for evaluation, additional relevant use cases and requirements, and any
relevant evidence or literature.
The JPEG AIC committee has also started the
preparation of a workshop on subjective assessment methods for the investigated
quality range, which will be held at the end of June. The workshop targets obtaining
different views on the problem, and will include both internal and external
speakers, as well as a Q&A panel. Experts in the field of quality
assessment and stakeholders interested in the use cases are invited.
JPEG NFT
After the joint
JPEG NFT and Fake Media workshops it became evident that even though the use
cases between both topics are different, there is a significant overlap in
terms of requirements and relevant solutions. For that reason, it was decided
to create a single AHG that covers both JPEG NFT and JPEG Fake Media
explorations. The newly established AHG JPEG Fake Media and NFT will use the
JPEG Fake Media mailing list.
JPEG DNA
The JPEG Committee has continued its
exploration of the coding of images in quaternary representations, as it is
particularly suitable for DNA storage applications. The scope of JPEG DNA is
the creation of a standard for efficient coding of images that considers
biochemical constraints and offers robustness to noise introduced by the
different stages of the storage process that is based on DNA synthetic
polymers. A new version of the overview document on DNA-based Media Storage:
State-of-the-Art, Challenges, Use Cases and Requirements was issued and has
been made publicly available. It was decided to continue this exploration by
validating and extending the JPEG DNA benchmark codec to simulate an end-to-end
image storage pipeline using DNA for future exploration experiments including
biochemical noise simulation. During the 95th JPEG meeting, a new specific
document describing the Use Cases and Requirements for DNA-based Media Storage
was created which is made publicly available. A timeline for the
standardization process was also defined. Interested parties are invited to
consider joining the effort by registering to the JPEG DNA AHG mailing list.
JPEG XS
The JPEG
Committee is pleased to announce that the 2nd editions of Part 1 (Core coding
system), Part 2 (Profiles and buffer models), and Part 3 (Transport and
container formats) were published in March 2022. Furthermore, the committee
finalized the work on Part 4 (Conformance testing) and Part 5 (Reference
software), which are now entering the final phase for publication. With these
last two parts, the committee’s work on the 2nd edition of the JPEG XS standards comes to an end, allowing to shift the focus to further
improve the standard. Meanwhile, in response to the latest Use Cases and
Requirements for JPEG XS v3.1, the committee received a number of technology
proposals from Fraunhofer and intoPIX that focus on improving the compression
performance for desktop content sequences. The proposals will now be evaluated
and thoroughly tested and will form the foundation of the work towards a 3rd
edition of the JPEG XS suite of standards. The primary goal of the 3rd edition
is to deliver the same image quality as the 2nd edition, but with half of the
required bandwidth.
JPEG XL
The second edition of JPEG XL Part 1 (Core coding system), with an improved numerical stability of the edge-preserving filter and numerous editorial improvements, has proceeded to the CD stage. Work on a second edition of Part 2 (File format) was initiated. Hardware coding was also further investigated. Preliminary software support has been implemented in major web browsers, image viewing and editing software, including popular tools such as FFmpeg, ImageMagick, libvips, GIMP, GDK and Qt. JPEG XL is now ready for wide-scale adoption.
Final Quote
“Recent development on creation and modification of visual information call for development of tools that can help protecting the authenticity and integrity of media assets. JPEG Fake Media is a standardised framework to deal with imaging provenance.” said Prof. Touradj Ebrahimi, the Convenor of the JPEG Committee.
Upcoming JPEG meetings are planned as follows:
No. 96, will be held
online during 25-29 July 2022.
We often find other collaborators by chance at a conference or by looking for them specifically through their papers. However, sometimes hidden potential social connections might exist between different researchers that cannot be immediately observed because the keywords we use might not always represent the entire space of similar research interests. As a community, Multimedia (MM) is so diverse that it is easy for community members to miss out on very useful expertise and potentially fruitful collaborations. There is a lot of latent knowledge and potential synergies that could exist if we were to offer conference attendees an alternative perspective on their similarities to other attendees. ConfFlow is an online application that offers an alternative perspective on finding new research connections. It is designed to help researchers find others at conferences with complementary research interests for collaboration. With ConfFlow we take a data-driven approach by using something similar to the Toronto Paper Matching System (TPMS), used to identify suitable reviewers for papers, to construct a similarity embedding space for researchers to find other researchers.
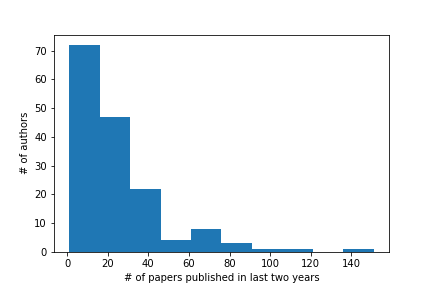
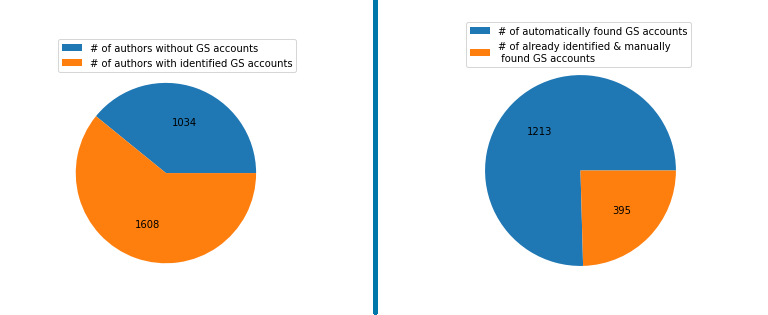
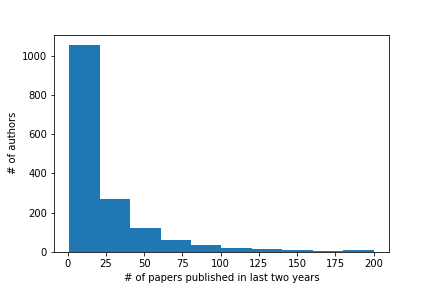
In this report, we discuss the follow up to the 2020 ConfFlow edition which was run at MMSys, MM, ICMR in 2021. We created separate editions of ConfFlow for each conference, processing 2642 (MM), 272 (MMSys), and 494 (ICMR) accepted authors from each conference.
Both the 2020 and 2021 editions of ConfFlow were funded by the SIGMM special initiatives fund.
New Functionality
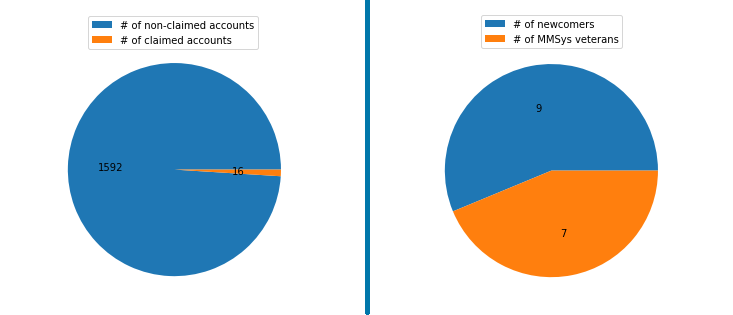
In the 2020 edition of ConfFlow, we created an interface allowing authors at the MM 2020 conference to browse the research similarity space with others. Each user needs to claim their Google scholar account in the application before using it. We implemented a strict privacy-sensitive policy allowing data of individuals only to be shown if they consented to use the database; even public data was not shown as the processed public data might be considered a privacy invasion. Unfortunately, because of this strict policy, and very little uptake of the application, the full experience of the application was not possible for any user. In the 2021 edition, we updated the privacy policy to be more permissive, whilst still secure (see discussion in the Privacy and Ethical Considerations section below).
From our experiences from the 2020 edition, we identified some bottlenecks that could be improved upon. To that end, we made the following augmentations:
Improved frontend design: We did an overhaul of the interface to make it more modern, visually appealing, and user-friendly. The design was also slightly changed to accommodate new functionalities
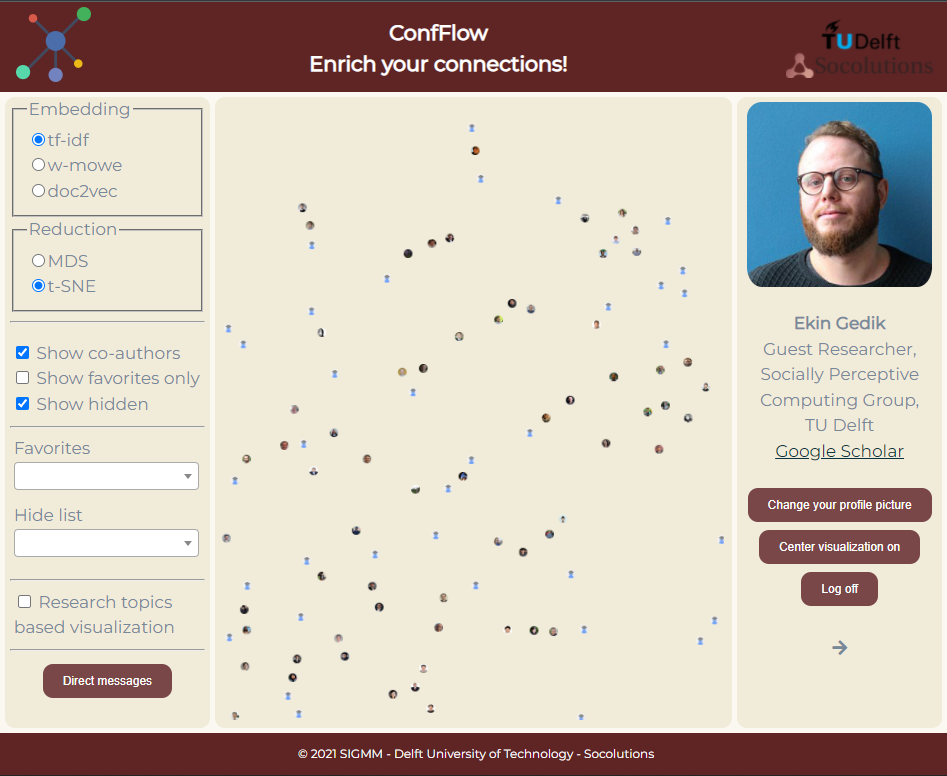
New embedding options: We added two more options to choose how the similarity space is formed; word2vec (tf-idf weighted mean word2vec embeddings: w(eighted)-m(ean)o(f)w(ord)e(mbeddings)) and doc2vec (see Figure 1)
Figure 1. Screenshot showing the new embedding functionality (m-mowe and doc2vec)
Interactive tutorial for onboarding: We included an interactive tutorial that showcases the full range of functionalities to the users when they first log in (see Figure 2)
Direct messaging functionality: We added direct messaging to ConfFlow, allowing direct communication between attendees (see Figure 3)
Scaling ConfFlow and making it cheaper to run in the future: There is an economy of scale to only needing to update the ConfFlow database with conference newcomers. We made the following steps to make the process more efficient:
Generating a database of verified authors from the lists of SIGMM conference attendees listed on the ACM website in the last 6 years.
A helper tool for finding google scholar profiles of newcomers quicker as they needed to be manually verified for security reasons.
Figure 2. Screenshot example of the walkthrough/tutorial
Figure 3. Screenshot of the direct messaging functionality
Deployment
Method
ConfFlow was rolled out to 3 conferences starting with MMSys 2021 (Istanbul, Turkey) in September, Multimedia 2021 (Chengdu, China) in October, and ICMR (Taipei, Taiwan) 2021 in November rather than just ACM MM in 2020. All MMSys and MM conferences were organized as hybrid events whilst ICMR was finally organized virtually after having to be rescheduled twice.
We asked all general and program chairs of each respective conference to provide the author lists of the accepted papers in the conference at least 1 month before the conference started. This was in the end a compromise between obtaining just the actual conference attendees (which would have made social connection easier if the conferences had been in-person only) and being able to get conference relevant participants sufficiently ahead of time in order to disambiguate identities and start the time-consuming computations of the embedding spaces. Given the added complication that MMSys and Multimedia were hybrid, the problem of waiting for the final conference registration list was that we would need to wait until very close to the conference itself to get the latest attendee list. In any case, even if we knew, the hybrid nature of the conference made virtual social connection still the more viable option. Use of the attendee list would also make it harder to pre-announce the application just before the conference started. Given also that the conference organizers were very occupied with handling the many uncertainties of conference organization during the pandemic, we decided that obtaining the author lists was the least risky approach.
Aside from getting the author lists, we also asked the conference organizers for support in disseminating the application to the conference attendees. A separate edition of ConfFlow needed to be generated for each conference. The following strategies were used for disseminating the application via the conference directly and from a personal account:
MMSys: slack channel, Twitter (conference, personal, and sigmm), weixin, weibo, facebook, presentation slides during conference general announcements
ACM MM: Twitter (conference and sigmm), whova, presentation slide during the conference banquet
ICMR: Twitter (conference, personal, and sigmm).
We tried a different strategy compared to last year to catch people’s attention to the application by a more comprehensive dissemination strategy and also short catchy explanatory videos to communicate the functionalities of the application. These were embedded in our social media dissemination campaigns.
Following on from that, we issued an online survey to gauge how people in the community at large felt about social interaction and, if they had used ConfFlow, how was their experience of the app. This was sent shortly after the conference by email to all those that used the application and then also 1 week later as a reminder. Posts were also sent out on Twitter and Facebook to encourage people in the community to fill in the survey even if they had not used ConfFlow. The survey was divided into questions related to collaboration in general, their experience using ConfFlow, and questions about how the application experience could be changed. Further details about the questions are shown in the Appendix.
Privacy and Ethical Considerations
The first edition of ConfFlow (2020) had a very restrictive opt-in only policy. This made the visualization hard to use for interestedusers, thus severely hindering the user experience. Users unanimously asked for visualization of the other researchers in the community. Therefore, any already publicly available information from a user’s google scholar account or ACM website and derived visualizations were displayed to everyone. Information that is not available publicly online such as their individual usage behavior, their visualization options, whether their ConfFlow account is activated or not etc is not shown publicly.
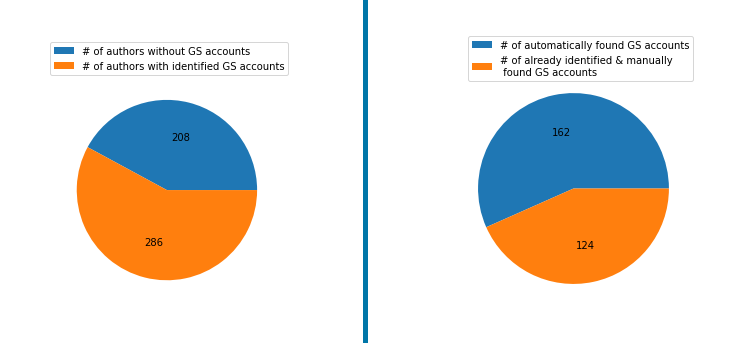
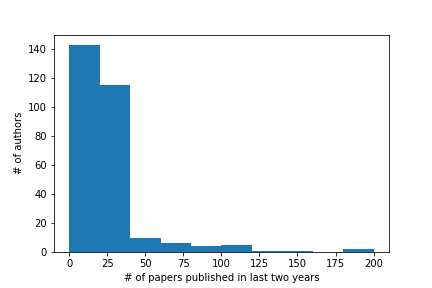
Application Realization
For security reasons, each user cannot use ConfLab until they have claimed their account. This is needed because each account has preferences related to the ConfFlow interface – settings such as hiding particular researchers, having researchers marked as ‘favourites’ as well as the direct messaging functionality. We used very strict security procedures for the building of ConfFlow and this also meant that to retrieve a user’s preferences in the application, a user’s identity needed to be verified when a user claims their account. We do this by associating the author’s name and affiliation with a Google scholar profile and then a user needs to verify their identity with respect to their Google scholar account. In some cases, it is necessary to manually assign an author to a Google scholar profile because there are too many profiles with the same name; sometimes many author names can be associated with the same Google scholar account. To this end, one of the main new functionalities was the creation of a database of all SIGMM community members who had published at the MM conference recently. That way, their name and google scholar profile only needs to be associated once and can easily be re-used in future editions of ConfLab. This manual effort aspect of the process varied across the three different conferences in which ConfLab was created. We elaborate on this below. An additional helper function was created to allow faster manual verification in cases of ambiguity.
ConfFlow at ACM SIGMM
We describe some statistics for each edition of ConfFlow at the three conferences of SIGMM in 2021: MMSys, MM, and ICMR. We list them in chronological order of when the conference occurred in the calendar year.
ACM MMSys
The author list provided by General Chairs of MMSys had 272 unique authors. As shown in Figure 4., we were able to identify Google Scholar accounts of 158 authors. 145 of these accounts were identified automatically using the provided author information: name, affiliation, and e-mail domain. 13 accounts identified by the automatic process were tagged as ambiguous and required manual validation.
Figure 4. Author statistics for ACM MMSys‘21
We created ConfFlow accounts for 145 identified authors. As shown in Figure 5, 18 users claimed their accounts and used ConfFlow during the conference. Further analysis showed that 7 out of 18 users were newcomers to MMSys i.e., it was their first publication at this conference.
After sending out the survey request to the 18 users after the conference, we obtained 1 survey response from a PhD student. Due to the low response rate, we do not report the responses.
Figure 5. User statistics for ConfFlow-MMSys‘21
The similarity space visualized in ConfFlow is based on the publications of authors in the last two years. Figure 6 shows the distribution of the number of papers MMSys authors published in the last two years. We show this because for each identified author, we take all the papers they published in the last 2 years to generate the latent representation of their research interests. What was particularly interesting to see is how many researchers were publishing 30 or more papers in the last 2 years. They account for a significant proportion of the authors of the conference who may be too busy to find new research connections. However, there is also a significant proportion of researchers publishing less than 30 papers a year who could find Conf Lab useful.
Figure 6. Histogram of the number of publications in the last 2 years for MMSys’21 authors.
ACM Multimedia
We realized that users without a Google scholar profile could not use ConfLab at all so for the Multimedia edition, we added a view-only (guest account) option of ConfLab and advertised it on social media accordingly. This view-only account also allowed researchers who did not want to claim their account to browse the embedding space. The disadvantage of this approach is that the application does not immediately centre on the user in the embedding space. Given the large number of authors at Multimedia, this made it extremely hard for view-only users to find themselves, which may have made it harder for them to appreciate the utility of the application.
As shown in Figure 7, the author list provided by General Chairs of Multimedia had 2642 unique authors. We were able to identify Google Scholar accounts of 1608 authors. 1213 of these accounts were identified automatically using the provided author information: name, affiliation, and e-mail domain. 225 authors were already identified in the previous iterations of ConfFlow for ACM MMSys ‘21 and MM ‘20. We then manually analyzed the remaining 1204 authors that were either tagged as ambiguous matches by the automatic process or returned no matches at all. We were able to identify an additional 170 accounts with the manual search. This highlights how challenging it is to establish an online identity for all authors in order for them to use ConfFlow, despite manual intervention.
Figure 7. Author statistics for MM’21
We created ConfFlow accounts for the identified authors. As shown in Figure 8, 16 users claimed their accounts and used ConfFlow during the conference. Further analysis showed that 9 out of 16 users were newcomers to MMSys i.e., it was their first publication at this conference. 5 attendees requested access to the guest account.
Figure 8. User statistics for ConfFlow-MM’21.
Figure 9 shows the distribution of the number of papers. Multimedia 2021 authors published in the last two years. It is interesting to see a more skewed distribution towards people with fewer publications compared to the MMSys edition. This would suggest that there are potentially more researchers who would find ConfFlow interesting as a social connection tool. However, both MMSys and Multimedia had very similar numbers of users despite Multimedia being almost 10 times bigger. This may be related to the fact that we were able to be in closer communication with the general chairs of MMSys who gave us access to more channels of communication (including a slide announcement during the conference opening). Meanwhile, at MM, the initial dissemination via Whova (which was the first line of attack) did not yield any new users at all and the Multimedia social media feed (Twitter) had very few followers – this could be explained by the fact that Twitter is not used by many of our colleagues in Asia and Multimedia was being run in Chengdu. We do not have statistics on the proportion of hybrid vs. in-person attendees which may also have affected usage.
Figure 9. Histogram of the number of publications in the last 2 years for all identified authors of MM’21.
ICMR
The author list provided by the General Chairs of Multimedia had 494 unique authors. As shown in Figure 10, we were able to identify Google Scholar accounts of 286 authors. 162 of these accounts were identified automatically using the provided author information: name, affiliation, and e-mail domain. 67 authors were already identified in the previous iterations of ConfFlow. We then manually analyzed the remaining 265 authors that were either tagged as ambiguous matches by the automatic process or returned no matches at all. We were able to identify an additional 57 accounts with the manual search.
Figure 10. Author statistics for ICMR ‘21
None of the users claimed their ConfFlow account during ICMR’21. Figure 11 shows the distribution of the number of papers MMSys authors published in the last two years. It is interesting that despite being almost double the size of MMSys and 5 times smaller than Multimedia,
Figure 11. Histogram of number of publications in the last 2 years for all identified authors of ICMR ‘21.
Discussion and Recommendations
This section describes some key points of reflection on the running of ConfFlow this year.
One of the main issues relates to the low number of users despite conference participants being aware of the application. The survey on collaboration and experience with ConfFlow did not yield sufficient responses.
It is interesting to see in all conferences that a significant proportion of the users of ConfFlow were newcomers. Unfortunately, without the statistics from the survey we put out, it is not clear if this reflects the distribution of the conference attendees in general or whether more newcomers are interested in using ConfFlow due to its promise of helping people to connect socially.
The reasons for this could be multiple: The hybrid format and virtual formats of the conferences made it difficult to provide time to think about collaborations whilst being in the middle of preparing to go to a conference or during the conference itself. For virtual participants, in particular, the benefit of not going physically means that one can continue with day to day duties in the person’s normal job. However, this does take away opportunities for social networking that one might have in the in-person setting. In addition, the challenges of running the conference in the hybrid format may also have led to fatigue for in-person as well as virtual participants. Another possible explanation is that in the general Multimedia community there is no obvious intrinsic value in changing the way collaboration is already carried out. The additional barrier of needing to claim their account due to privacy and ethical reasons may have been confusing (it could appear that an account needs to be created, which can be a barrier to usage).
We reflect that the fact that more users were obtained for MMSys could have been related to the closer access we had to social media channels e.g. the conference slack channel, which helped to keep a centralized reminder for participants of what was going on in the conference. It could also be a reflection of the openness of the community to finding social connections. On the other hand, the Whova app used for MM is a more complex interface with multiple purposes beyond just communication, which may have made it harder for attendees to see the ConfLab announcement, embedded in other announcements.
Finally, we also considered that the ConfFlow interface takes time to browse and reflect on. Given that the intrinsic value of the application is not immediately obvious to many (this is our interpretation of the low interest in application use). It could make more sense to have a SIGMM community-wide edition of ConfFlow that is available all year round, allowing for the dissemination of the application and its purpose to be made clear outside of the pre-conference rush. Then conference-specific editions could be generated. This, however, comes with its own logistic issues as every new identity added to the database would either require the entire embedding to be recomputed, or their latent research interest representation would need to be projected directly onto the existing embedding, which does not necessarily accurately represent their closeness to others in the existing database. The rate at which updates (new authors) are added would also require significant manual attention (and may not be easy to resolve as shown in the statistics in Table 1). Given also the popularity of the Influence Flowers (http://influencemap.ml/), a previously funded SIGMM initiative, we suspect that a more ego-based strategy may be more effective in encouraging researchers in the community to start engaging with the ConfFlow application.
ConfLab Factors\ Conference:
MMSys
Multimedia
ICMR
#authors
272
2642
494
#previously identified authors
0
225
286
#authors with automatically identifiable Google scholar
158
1213
67
#authors without Google Scholar Match
13
1204
265
#authors with manually identified Google Scholar.
13
170
57
#users
18
16
0
#survey respondents
1
0
0
Table 1. Summary statistics for each of the three conferences.
Conclusions
The ConfFlow 2021 edition generated new functionalities to allow researchers to browse their research interests with respect to others in a fun and novel way. More effort was given this year to improve the advertising of the application and to try and understand the community’s struggles with collaboration. Steps were also taken to make the running of ConfFlow less labour-intensive.
Our conclusions from the many efforts made in ConfFlow 2021, the surrounding social media presence, and the survey is that for the SIGMM population at large, encouraging more social connections outside of the normal routes is unfortunately not perceived to have significant value. It seems that for now, more immediate forms of social interaction encouragement e.g. initiatives during the conference to help newcomers to integrate may be a more effective route to enable social integration. Another option is to consider a hybrid approach where ConfFlow can be used to e.g. identify groups for going to dinner together during the conference or sitting at the same table during the conference banquet. However, this would still require a sufficient uptake of the application. Given the myriad of different motivations community members have to attend conferences, it remains an intriguing and open challenge to encourage more diverse research output from this highly interdisciplinary community.
Acknowledgements:
ConfFlow 2021 was supported in part by the SIGMM Special Initiatives Fund and the Dutch NWO-funded MINGLE project number 639.022.606. We thank users who gave feedback on the application during prototyping and implementation and the General Chairs of ACM MMSys, Multimedia, and ICMR 2021 for their support.
References:
Ekin Gedik and Hayley Hung. 2020. ConfFlow: A Tool to Encourage New Diverse Collaborations. Proceedings of the 28th ACM International Conference on Multimedia. Association for Computing Machinery, New York, NY, USA, 4562–4564. DOI:https://doi.org/10.1145/3394171.3414459
Appendix:
List of Survey Questions used for our google form:
Please indicate the job description that best describes you.
General Questions about Scientific Collaboration
I tend to initiate collaborations with people I already know well.
I tend to initiate collaborations with people at the same experience level as me.
I am very interested in finding collaborators from a different discipline.
I find it very hard to identify relevant collaborators from a different discipline.
I find it very hard to initiate interdisciplinary collaborations even when I know who I want to work with.
What are the common problems you face when trying to initiate a collaboration?
Do these problems influence how or whether you initiate collaborations?
Initial contact with ConfFlow:
I saw announcements encouraging me to try ConfFlow
Did you have problems in getting in to ConfFlow? e.g. the system could not find your Google Scholar account?
On how many separate occasions have you used ConfFlow?
Motivation for using ConfFlow
I did not use ConfFlow because I did not have time.
I did not use ConfFlow because I did not find it interesting.
I would be interested in trying ConfFlow in the weeks leading up to or following a conference.
Despite not using ConfFlow, I could see how it might help advance my research work.
We would be very grateful for any comments or feedback on your experience of ConfFlow so we can make it more useful. Please feel free to share any remarks you might have on this topic.
Experience using ConfFlow
The visualization matched who I would expect to be close to me.
The visualization matched who I would expect to be far away from me.
ConfFlow helped me to find interesting people that I did not know before.
ConfFlow helped me to connect with interesting people that I did not know before.
ConfFlow encouraged me to think more deliberately about making connections with researchers in a different discipline.
I think that ConfFlow could help to advance my research work.
Welcome to a new column on the ACM SIGMM Records from the Video Quality Experts Group (VQEG). The last VQEG plenary meeting took place from 13 to 17 December 2021, and it was organized online by University of Surrey, UK. During five days, more than 100 participants (from more than 20 different countries of America, Asia, Africa, and Europe) could remotely attend the multiple sessions related to the active VQEG projects, which included more than 35 presentations and interesting discussions. This column provides an overview of this VQEG plenary meeting, while all the information, minutes and files (including the presented slides) from the meeting are available online in the VQEG meeting website.
Group picture of the VQEG Meeting 13-17 December 2021
Many of the works presented in this meeting can be relevant for the SIGMM community working on quality assessment. Particularly interesting can be the new analyses and methodologies discussed within the Statistical Analyses Methods group, the new metrics and datasets presented within the No-Reference Metrics group, and the progress on the plans of the 5G Key Performance Indicators group and the Immersive Media group. We encourage those readers interested in any of the activities going on in the working groups to check their websites and subscribe to the corresponding reflectors, to follow them and get involved.
Overview of VQEG Projects
Audiovisual HD (AVHD)
The AVHD group investigates improved subjective and objective methods for analyzing commonly available video systems. In this sense, it has recently completed a joint project between VQEG and ITU SG12 in which 35 candidate objective quality models were submitted and evaluated through extensive validation tests. The result was the ITU-T Recommendation P.1204, which includes three standardized models: a bit-stream model, a reduced reference model, and a hybrid no-reference model. The group is currently considering extensions of this standard, which originally covered H.264, HEVC, and VP9, to include other encoders, such as AV1. Apart from this, two other projects are active under the scope of AVHD: QoE Metrics for Live Video Streaming Applications (Live QoE) and Advanced Subjective Methods (AVHD-SUB).
During the meeting, three presentations related to AVHD activities were provided. In the first one, Mikolaj Leszczuk (AGH University) presented their work on secure and reliable delivery of professional live transmissions with low latency, which brought to the floor the constant need for video datasets, such as the VideoSet. In addition, Andy Quested (ITU-R Working Party 6C) led a discussion on how to assess video quality for very high resolution (e.g., 8K, 16K, 32K, etc.) monitors with interactive applications, which raised the discussion on the key possibility of zooming in to absorb the details of the images without pixelation. Finally, Abhinau Kumar (UT Austin) and Cosmin Stejerean (Meta) presented their work on exploring the reduction of the complexity of VMAF by using features in the wavelet domain [1].
Quality Assessment for Health applications (QAH)
The QAH group works on the quality assessment of health applications, considering both subjective evaluation and the development of datasets, objective metrics, and task-based approaches. This group was recently launched and, for the moment, they have been working on a topical review paper on objective quality assessment of medical images and videos, which was submitted in December to Medical Image Analysis [2]. Rafael Rodrigues (Universidade da Beira Interior) and Lucie Lévêque (Nantes Université) presented the main details of this work in a presentation scheduled during the QAH session. The presentation also included information about the review paper published by some members of the group on methodologies for subjective quality assessment of medical images [3] and the efforts in gathering datasets to be listed on the VQEG datasets website. In addition, Lu Zhang (IETR – INSA Rennes) presented her work on model observers for the objective quality assessment of medical images from task-based approaches, considering three tasks: detection, localization, and characterization [4]. In addition, it is worth noting that members of this group are organizing a special session on “Quality Assessment for Medical Imaging” at the IEEE International Conference on Image Processing (ICIP) that will take place in Bordeaux (France) from the 16 to the 19 October 2022.
Statistical Analysis Methods (SAM)
The SAM group works on improving analysis methods both for the results of subjective experiments and for objective quality models and metrics. Currently, they are working on statistical analysis methods for subjective tests, which are discussed in their monthly meetings.
In this meeting, there were four presentations related to SAM activities. In the first one, Zhi Li and Lukáš Krasula (Netflix), exposed the lessons they learned from the subjective assessment test carried out during the development of their metric Contrast Aware Multiscale Banding Index (CAMBI) [5]. In particular, they found that some subjective can have perceptually unbalanced stimuli, which can cause systematic and random errors in the results. In this sense, they explained their statistical data analyses to mitigate these errors, such as the techniques in ITU-T Recommendation P.913 (section 12.6) which can reduce the effects of the random error. The second presentation described the work by Pablo Pérez (Nokia Bell Labs), Lucjan Janowsk (AGH University), Narciso Garcia (Universidad Politécnica de Madrid), and Margaret H. Pinson (NTIA/ITS) on a novel subjective assessment methodology with few observers with repetitions (FOWR) [6]. Apart from the description of the methodology, the dataset generated from the experiments is available on the Consumer Digital Video Library (CDVL). Also, they launched a call for other labs to repeat their experiments, which will help on discovering the viability, scope and limitations of the FOWR method and, if appropriate, include this method in the ITU-T Recommendation P.913 for quasi-experimental assessments when it is not possible to have 16 to 24 subjects (e.g., pre-tests, expert assessment, and resource limitations), for example, performing the experiment with 4 subjects 4 times each on different days, which would be similar to a test with 15 subjects. In the third presentation, Irene Viola (CWI) and Lucjan Janowski (AGH University) presented their analyses on the standardized methods for subject removal in subjective tests. In particular, the methods proposed in the recommendations ITU-R BT.500 and ITU-T P.913 were considered, resulting in that the first one (described in Annex 1 of Part 1) is not recommended for Absolute Category Rating (ACR) tests, while the one described in the second recommendations provides good performance, although further investigation in the correlation threshold used to discard subjects s required. Finally, the last presentation led the discussion on the future activities of SAM group, where different possibilities were proposed, such as the analysis of confidence intervals for subjective tests, new methods for comparing subjective tests from more than two labs, how to extend these results to better understand the precision of objective metrics, and research on crowdsourcing experiment in order to make them more reliable and improve cost-effectiveness. These new activities are discussed in the monthly meetings of the group.
Computer Generated Imagery (CGI)
CGI group focuses on quality analysis of computer-generated imagery, with a focus on gaming in particular. Currently, the group is working on topics related to ITU work items, such as ITU-T Recommendation P.809 with the development of a questionnaire for interactive cloud gaming quality assessment, ITU-T Recommendation P.CROWDG related to quality assessment of gaming through crowdsourcing, ITU-T Recommendation P.BBQCG with a bit-stream based quality assessment of cloud gaming services, and a codec comparison for computer-generated content. In addition, a presentation was delivered during the meeting by Nabajeet Barman (Kingston University/Brightcove), who presented the subjective results related to the work presented at the last VQEG meeting on the use of LCEVC for Gaming Video Streaming Applications [7]. For more information on the related activities, do not hesitate to contact the chairs of the group.
No Reference Metrics (NORM)
The NORM group is an open collaborative project for developing no-reference metrics for monitoring visual service quality. Currently, two main topics are being addressed by the group, which are discussed in regular online meetings. The first one is related to the improvement of SI/TI metrics to solve ambiguities that have appeared over time, with the objective of providing reference software and updating the ITU-T Recommendation P.910. The second item is related to the addition of standard metadata of video quality assessment-related information in the encoded video streams.
In this meeting, this group was one of the most active in terms of presentations on related topics, with 11 presentations. Firstly, Lukáš Krasula (Netflix) presented their Contrast Aware Multiscale Banding Index (CAMBI) [5], an objective quality metric that addresses banding degradations that are not detected by other metrics, such as VMAF and PSNR (code is available on GitHub). Mikolaj Leszczuk (AGH University) presented their work on the detection of User-Generated Content (UGC) automatic detection in the wild. Also, Vignesh Menon & Hadi Amirpour (AAU Klagenfurt) presented their open-source project related to the analysis and online prediction of video complexity for streaming applications. Jing Li (Alibaba) presented their work related to the perceptual quality assessment of internet videos [8], proposing a new objective metric (STDAM, for the moment, used internally) validated in the Youku-V1K dataset. The next presentation was delivered by Margaret Pinson (NTIA/ITS) dealing with a comprehensive analysis on why no-reference metrics fail, which emphasized the need of training these metrics on several datasets and test them on larger ones. The discussion also pointed out the recommendation for researchers to publish their metrics in open source in order to make it easier to validate and improve them. Moreover, Balu Adsumilli and Yilin Wang (Youtube) presented a new no-reference metric for UGC, called YouVQ, based on a transfer-learning approach with a pre-train on non-UGC data and a re-train on UGC. This metric will be released in open-source shortly, and a dataset with videos and subjective scores has been also published. Also, Margaret Pinson (NTIA/ITS), Mikołaj Leszczuk (AGH University), Lukáš Krasula (Netflix), Nabajeet Barman (Kingston University/Brightcove), Maria Martini (Kingston University), and Jing Li (Alibaba) presented a collection of datasets for no-reference metric research, while Shahid Satti (Opticom GmbH) exposed their work on encoding complexity for short video sequences. On his side, Franz Götz-Hahn (Universität Konstanz/Universität Kassel) presented their work on the creation of the KonVid-150k video quality assessment dataset [9], which can be very valuable for training no-reference metrics, and the development of objective video quality metrics. Finally, regarding the aforementioned two active topics within NORM group, Ioannis Katsavounidis (Meta) provided a presentation on the advances in relation to the activity related to the inclusion of standard video quality metadata, while Lukáš Krasula (Netflix), Cosmin Stejerean (Meta), and Werner Robitza (AVEQ/TU Ilmenau) presented the updates on the improvement of SI/TI metrics for modern video systems.
Joint Effort Group (JEG) – Hybrid
The JEG group was focused on joint work to develop hybrid perceptual/bitstream metrics and on the creation of a large dataset for training such models using full-reference metrics instead of subjective metrics. In this sense, a project in collaboration with Sky was finished and presented in the last VQEG meeting.
Related activities were presented in this meeting. In particular, Enrico Masala and Lohic Fotio Tiotsop (Politecnico di Torino) presented the updates on the recent activities carried out by the group, and their work on artificial-intelligence observers for video quality evaluation [10].
Implementer’s Guide for Video Quality Metrics (IGVQM)
The IGVQM group, whose activity started in the VQEG meeting in December 2020, works on creating an implementer’s guide for video quality metrics. In this sense, the current goal is to create a report on the accuracy of video quality metrics following a test plan based on collecting datasets, collecting metrics and methods for assessment, and carrying out statistical analyses. An update on the advances was provided by Ioannis Katsavounidis (Meta) and a call for the community is open to contribute to this activity with datasets and metrics.
5G Key Performance Indicators (5GKPI)
The 5GKPI group studies relationship between key performance indicators of new communications networks (especially 5G) and QoE of video services on top of them. Currently, the group is working on the definition of relevant use cases, which are discussed on monthly audiocalls.
In relation to these activities, there were four presentations during this meeting. Werner Robitza (AVQ/TU Ilmenau) presented a proposal for KPI message format for gaming QoE over 5G networks. Also, Pablo Pérez (Nokia Bell Labs) presented their work on a parametric quality model for teleoperated driving [11] and an update of the ITU-T GSTR-5GQoE topic, related to the QoE requirements for real-time multimedia services over 5G networks. Finally, Margaret Pinson (NTIA/ITS) presented an overall description of 5G technology, including differences in spectrum allocation per country impact on the propagation and responsiveness and throughput of 5G devices.
Immersive Media Group (IMG)
The IMG group researches on quality assessment of immersive media. The group recently finished the test plan for quality assessment of short 360-degree video sequences, which resulted in the support for the development of the ITU-T Recommendation P.919. Currently, the group is working on further analyses of the data gathered from the subjective tests carried out for that test plan and on the analysis of data for the quality assessment of long 360-degree videos. In addition, members of the group are contributing to the IUT-T SG12 on the topic G.CMVTQS on computational models for QoE/QoS monitoring to assess video telephony services. Finally, the group is also working on the preparation of a test plan for evaluating the QoE with immersive and interactive communication systems, which was presented by Pablo Pérez (Nokia Bell Labs) and Jesús Gutiérrez (Universidad Politécnica de Madrid). If the reader is interested in this topic, do not hesitate to contact them to join the effort.
During the meeting, there were also four presentations covering topics related to the IMG topics. Firstly, Alexander Raake (TU Ilmenau) provided an overview of the projects within the AVT group dealing with the QoE assessment of immersive media. Also, Ashutosh Singla (TU Ilmenau) presented a 360-degree video database with higher-order ambisonics spatial audio. Maria Martini (Kingston University) presented an update on the IEEE standardization activities on Human Factors or Visual Experiences (HFVE), such as the recently submitted draft standard on deep-learning-based quality assessment and the draft standard to be submitted shortly on quality assessment of light field content. Finally, Kjell Brunnstöm (RISE) presented their work on legibility in virtual reality, also addressing the perception of speech-to-text by Deaf and hard of hearing.
Intersector Rapporteur Group on Audiovisual Quality Assessment (IRG-AVQA) and Q19 Interim Meeting
Although in this case there was no official meeting IRG-AVQA meeting, there were various presentations related to ITU activities addressing QoE evaluation topics. In this sense, Chulhee Lee (Yonsei University) presented an overview of ITU-R activities, with a special focus on quality assessment of HDR content, and together with Alexander Raake (TU Ilmenau) presented an update on ongoing ITU-T activities.
Other updates
All the sessions of this meeting and, thus, the presentations, were recorded and have been uploaded to Youtube. Also, it is worth informing that the anonymous FTP will be closed soon, so files and presentations can be accessed from old browsers or via an FTP app. All the files, including those corresponding to the VQEG meetings, will be embedded into the VQEG website over the next months. In addition, the GitHub with tools and subjective labs setup is still online and kept updated. Moreover, during this meeting, it was decided to close the Joint Effort Group (JEG) and the Independent Lab Group (ILG), which can be re-established when needed. Finally, although there were not many activities in this meeting within the Quality Assessment for Computer Vision Applications (QACoViA) and the Psycho-Physiological Quality Assessment (PsyPhyQA) they are still active.
The next VQEG plenary meeting will take place in Rennes (France) from 9 to 13 May 2022, which will be again face-to-face after four online meetings.
It is a natural thing that users of multimedia services want to have the highest possible Quality of Experience (QoE), when using said services. This is especially so in contexts such as video-conferencing and video streaming services, which are nowadays a large part of many users’ daily life, be it work-related Zoom calls, or relaxing while watching Netflix. This has implications in terms of the energy consumed for the provision of those services (think of the cloud services involved, the networks, and the users’ own devices), and therefore it also has an impact on the resulting CO₂ emissions. In this column, we look at the potential trade-offs involved between varying levels of QoE (which for video services is strongly correlated with the bit rates used), and the resulting CO₂ emissions. We also look at other factors that should be taken into account when making decisions based on these calculations, in order to provide a more holistic view of the environmental impact of these types of services, and whether they do have a significant impact.
Energy Consumption and CO2 Emissions for Internet Service Delivery
Understanding the footprint of Internet service delivery is a challenging task. On one hand, the infrastructure and software components involved in the service delivery need to be known. For a very fine-grained model, this requires knowledge of all components along the entire service delivery chain: end-user devices, fixed or mobile access network, core network, data center and Internet service infrastructure. Furthermore, the footprint may need to consider the CO₂ emissions for producing and manufacturing the hardware components as well as the CO₂ emissions during runtime. Life cycle assessment is then necessary to obtain CO₂ emission per year for hardware production. However, one may argue that the infrastructure is already there and therefore the focus will be on the energy consumption and CO₂ emission during runtime and delivery of the services. This is also the approach we follow here to provide quantitative numbers of energy consumption and CO₂ emission for Internet-based video services. On the other hand, quantitative numbers are needed beyond the complexity of understanding and modelling the contributors to energy consumption and C02 emission.
To overcome this complexity, the literature typically considers key figures on the overall data traffic and service consumption times aggregated over users and services over a longer period of time, e.g., one year. In addition, the total energy consumption of mobile operators and data centres is considered. Together with the information on e.g., the number of base station sites, this gives some estimates, e.g., on the average power consumption per site or the average data traffic per base station site [Feh11]. As a result, we obtain measures such as energy per bit (Joule/bit) determining the energy efficiency of a network segment. In [Yan19], the annual energy consumption of Akamai is converted to power consumption and then divided by the maximum network traffic, which results again in the energy consumption per bit of Akamai’s data centers. Knowing the share of energy sources (nonrenewable energy, including coal, natural gas, oil, diesel, petroleum; renewable energy including solar, geothermal, wind energy, biomass, hydropower from flowing water), allows relating the energy consumption to the total CO₂ emissions. For example, the total contribution from renewables exceeded 40% in 2021 in Germany and Finland, Norway has about 60%, Croatia about 36% (statistics from 2020).
A detailed model of the total energy consumption of mobile network services and applications is provided in [Yan19]. Their model structure considers important factors from each network segment from cloud to core network, mobile network, and end-user devices. Furthermore, service-specific energy consumption are provided. They found that there are strong differences between the service type and the emerging data traffic pattern. However, key factors are the amount of data traffic and the duration of the services. They also consider different end-to-end network topologies (user-to-data center, user-to-user via data center, user-to-user and P2P communication). Their model of the total energy consumption is expressed as the sum of the energy consumption of the different segments:
Smartphone: service-specific energy depends among others on the CPU usage and the network usage e.g. 4G over the duration of use,
Base station and access network: data traffic and signalling traffic over the duration of use,
Wireline core network: service specific energy consumption of a mobile service taking into account the data traffic volume and the energy per bit,
Data center: energy per bit of the data center is multiplied by data traffic volume of the mobile service.
The Shift Project [TSP19] provides a similar model which is called the “1 Byte Model”. The computation of energy consumption is transparently provided in calculation sheets and discussed by the scientific community. As a result of the discussions [Kam20a,Kam20b], an updated model was released [TSP20] clarifying a simple bit/byte conversion issue. The suggested models in [TSP20, Kam20b] finally lead to comparable numbers in terms of energy consumption and CO₂ emission. As a side remark: Transparency and reproducibility are key for developing such complex models!
The basic idea of the 1 Byte Model for computing energy consumption is to take into account the time t of Internet service usage and the overall data volume v. The time of use is directly related to the energy consumption of the display of an end-user device, but also for allocating network resources. The data volume to transmit through the network, but also to generate or process data for cloud services, drives the energy consumption additionally. The model does not differentiate between Internet services, but they will result in different traffic volumes over the time of use. Then, for each segment i (device, network, cloud) a linear model E_i(t,v)=a_i * t + b_i * v + c_i is provided to quantify the energy consumption. To be more precise, the different coefficients are provided for each segment by [TSP20]. The overall energy consumption is then E_total = E_device + E_network + E_cloud.
CO₂ emission is then again a linear model of the total energy consumption (over the time of use of a service), which depends on the share of nonrenewable and renewable energies. Again, The Shift Project derives such coefficients for different countries and we finally obtain CO2 = k_country * E_total.
The Trade-off
between QoE and CO2 Emissions
As a use case, we consider
hosting a scientific conference online through video-conferencing services.
Assume there are 200 conference participants attending the video-conferencing
session. The conference lasts for one week, with 6 hours of online program per
day. The video conference software
requires the following data rates for streaming the sessions (video including
audio and screen sharing):
high-quality video: 1.0 Mbps
720p HD video: 1.5 Mbps
1080p HD video: 3 Mbps
However, group video calls require even higher bandwidth consumption. To make such experiences more immersive, even higher bit rates may be necessary, for instance, if using VR systems for attendance.
A simple QoE model may map the video bit rate of the current video session to a mean opinion score (MOS). [Lop18] provides a logistic regression MOS(x) depending on the video bit rate x in Mbps: f(x) = m_1 log x + m_2
Then, we can connect the QoE model with the energy consumption and CO₂ emissions model from above in the following way. We assume a user attending the conference for time t. With a video bit rate x, the emerging data traffic is v = x*t. Those input parameters are now used in the 1 Byte Model for a particular device (laptop, smartphone), type of network (wired, wifi, mobile), and country (EU, US, China).
Figure 1 shows the trade-off between the MOS and energy consumption (left y-axis). The energy consumption is mapped to CO₂ emission by assuming the corresponding parameter for the EU, and that the conference participants are all connected with a laptop. It can be seen that there is a strong increase in energy consumption and CO₂ emission in order to reach the best possible QoE. The MOS score of 4.75 is reached if a video bit rate of roughly 11 Mbps is used. However, with 4.5 Mbps, a MOS score of 4 is already reached according to that logarithmic model. This logarithmic behaviour is a typical observation in QoE and is connected to the Weber-Fechner law, see [Rei10]. As a consequence, we may significantly save energy and CO₂ when not providing the maximum QoE, but “only” good quality (i.e., MOS score of 4). The meaning of the MOS ratings is 5=Excellent, 4=Good, 3=Fair, 2=Poor, 1=Bad quality.
Figure 1: Trade-off between MOS and energy consumption or CO2 emission.
Figure 2, therefore, visualized the gain when delivering the video in lower quality and lower video bit rates. In fact, the gain compared to the efforts for MOS 5 are visualized. To get a better understanding of the meaning of those CO₂ numbers, we express the CO₂ gain now in terms of thousands of kilometers driving by car. Since the CO₂ emission depends on the share of renewable energies, we may consider different countries and the parameters as provided in [TSP20]. We see that ensuring each conference participant a MOS score of 4 instead of MOS 5 results in savings corresponding to driving approximately 40000 kilometers by car assuming the renewable energy share in the EU – this is the distance around the Earth! Assuming the energy share in China, this would save more than 90000 kilometers. Of course, you could also save 90 000 kilometers by walking – which requires however about 2 years non-stop with a speed of 5 km/h. Note that this large amount of CO₂ emission is calculated assuming a data rate of 15 Mbps over 5 days (and 6 hours per day), resulting in about 40.5 TB of data that needs to be transferred to the 200 conference participants.
Figure 2: Relating the CO2 emission in different countries for achieving this MOS to the distance by travelling in a car (in thousands of kilometers).
Discussions
Raising awareness of CO₂ emissions due to Internet service consumption is crucial. The abstract CO₂ emission numbers may be difficult to understand, but relating this to more common quantities helps to understand the impact individuals have. Of course, the provided numbers only give an impression, since the models are very simple and do not take into account various facets. However, the numbers nicely demonstrate the potential trade-off between QoE of end-users and sustainability in terms of energy consumption and CO₂ emission. In fact, [Gna21] conducted qualitative interviews and found that there is a lack of awareness of the environmental impact of digital applications and services, even for digital natives. In particular, an underlying issue is that there is a lack of understanding among end-users as to how Internet service delivery works, which infrastructure components play a role and are included along the end-to-end service delivery path, etc. Hence, the environmental impact is unclear for many users. Our aim is thus to contribute to overcoming this issue by raising awareness on this matter, starting with simplified models and visualizations.
[Gna21] also found that users indicate a certain willingness to make compromises between their digital habits and the environmental footprint. Given global climate changes and increased environmental awareness among the general population, such a trend in willingness to make compromises may be expected to further increase in the near future. Hence, it may be interesting for service providers to empower users to decide their environmental footprint at the cost of lower (yet still satisfactory) quality. This will also reduce the costs for operators and seems to be a win-win situation if properly implemented in Internet services and user interfaces.
Nevertheless, tremendous efforts are also currently being undertaken by Internet companies to become CO₂ neutral in the future. For example, Netflix claims in [Netflix2021] that they plan to achieve net-zero greenhouse gas emissions by the close of 2022. Similarly, also economic, societal, and environmental sustainability is seen as a key driver for 6G research and development [Mat21]. However, the time horizon is on a longer scope, e.g., a German provider claims they will reach climate neutrality for in-house emissions by 2025 at the latest and net-zero from production to the customer by 2040 at the latest [DT21]. Hence, given the urgency of the matter, end-users and all stakeholders along the service delivery chain can significantly contribute to speeding up the process of ultimately achieving net-zero greenhouse gas emissions.
References
[TSP19] The Shift Project, “Lean ict: Towards digital sobriety,” directed by Hugues Ferreboeuf, Tech. Rep., 2019, last accessed: March 2022. Available online (last accessed: March 2022)
[Yan19] M. Yan, C. A. Chan, A. F. Gygax, J. Yan, L. Campbell,A. Nirmalathas, and C. Leckie, “Modeling the total energy consumption of mobile network services and applications,” Energies, vol. 12, no. 1, p. 184, 2019.
[TSP20] Maxime Efoui Hess and Jean-Noël Geist, “Did The Shift Project really overestimate the carbon footprint of online video? Our analysis of the IEA and Carbonbrief articles”, The Shift Project website, June 2020, available online (last accessed: March 2022) PDF
[Kam20a] George Kamiya, “Factcheck: What is the carbon footprint of streaming video on Netflix?”, CarbonBrief website, February 2020. Available online (last accessed: March 2022)
[Kam20b] George Kamiya, “The carbon footprint of streaming video: fact-checking the headlines”, IEA website, December 2020. Available online (last accessed: March 2022)
[Feh11] Fehske, A., Fettweis, G., Malmodin, J., & Biczok, G. (2011). The global footprint of mobile communications: The ecological and economic perspective. IEEE communications magazine, 49(8), 55-62.
[Lop18] J. P. López, D. Martín, D. Jiménez, and J. M. Menéndez, “Prediction and modeling for no-reference video quality assessment based on machine learning,” in 2018 14th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), IEEE, 2018, pp. 56–63.
[Gna21] Gnanasekaran, V., Fridtun, H. T., Hatlen, H., Langøy, M. M., Syrstad, A., Subramanian, S., & De Moor, K. (2021, November). Digital carbon footprint awareness among digital natives: an exploratory study. In Norsk IKT-konferanse for forskning og utdanning (No. 1, pp. 99-112).
[Rei10] Reichl, P., Egger, S., Schatz, R., & D’Alconzo, A. (2010, May). The logarithmic nature of QoE and the role of the Weber-Fechner law in QoE assessment. In 2010 IEEE International Conference on Communications (pp. 1-5). IEEE.
[Netflix21] Netflix: “Environmental Social Governance 2020”, Sustainability Accounting Standards Board (SASB) Report, (2021, March). Available online (last accessed: March 2022)
[Mat21] Matinmikko-Blue, M., Yrjölä, S., Ahokangas, P., Ojutkangas, K., & Rossi, E. (2021). 6G and the UN SDGs: Where is the Connection?. Wireless Personal Communications, 121(2), 1339-1360.
[DT21] Hannah Schauff. Deutsche Telekom tightens its climate targets (2021, January). Available online (last accessed: March 2022)