


1. Introduction and Background
SIGMM is the Association for Computing Machinery’s (ACM) Special Interest Group (SIG) in Multimedia, one of 36 SIGs in the ACM family. ACM itself was founded in 1947 and is the world’s largest educational and scientific society for computing, uniting computing educators, researchers and professionals. With almost 100,000 members worldwide, ACM is a strong force in the computing world and is dedicated to advancing the art, science, engineering, and application of information technology.
SIGMM has been operating for nearly 30 years and sponsors 5, soon to be 6, major international conferences each year as well as dozens of workshops and an ACM Transactions Journal. SIGMM sponsors several Excellence and Achievement Awards each year, including awards for Technical Achievement, Rising Star, Outstanding PhD Thesis, TOMM best paper, and Best TOMM Associate Editor award. SIGMM funds student travel scholarships to almost all our conferences with nearly 50 such student travel grants at the flagship MULTIMEDIA conference in Seoul, Korea, in 2018. SIGMM has two active chapters, one in the Bay Area of San Francisco and one in China. It has a very active online activity with social media reporters at our conferences, a regular SIGMM Records newsletter, and a weekly news digest. At our flagship conference, SIGMM sponsors Women and diversity lunches, Doctoral Symposiums, and a newcomers’ welcome breakfast. SIGMM also funds special initiatives based on suggestions/proposals from the community as well as a newly-launched conference ambassador program to reach out to other ACM SIGs for collaborations across our conferences.
It is generally accepted that SIGMM has a diversity and inclusion problem which exists at all levels, but we have now realized this and have started to take action. In September 2017 ACM SIGARCH produced the first of a series of articles on gender diversity in the field of Computer Architecture. SIGARCH members looked at their numbers of representation of women in SIGARCH conferences over the previous 2 years and produced the first of a set of reports entitled “Gender Diversity in Computer Architecture: We’re Just Going to Leave This Here”.

This report generated much online debate and commentary, including at the ACM SIG Governing Board (SGB) meetings in 2017 and in 2018.
At a SIGMM Executive Committee meeting in Mountain View, California in October 2017, SIGMM agreed to replicate the SIGARCH study to examine and measure, the (lack of) gender diversity at SIGMM-sponsored Conferences. We issued a call offering funding support to do this, but there were no takers, so I did this myself, from within my own research lab.
2. Baselines for Performance Comparison
Before jumping into the numbers it is worth establishing a baseline to measure against. As an industry-wide figure, 17-24% of Computer Science undergrads at US R1 institutions are female as are 17% of those with technical roles at large high-tech companies that report diversity. I also looked at the female representation within some of the other ACM SIGs. While we must accept that inclusiveness and diversity is not just about gender but also about race, ethnicity, nationality, even about institution, we don’t have data on these other aspects so I focus just on gender diversity.
So how does SIGMM compare to other SIGs? Let’s look at SIG memberships using data provided by ACM.
The best (most balanced or least imbalanced) SIGs are CSE (Computer Science Education) with 25% female, Computer Human Interaction (CHI) also with 25% female from among those declaring a gender, though CHI is probably better because it has a greater percentage of undeclared gender, thus a lower proportion of males. The worst SIGs (most imbalanced or least balanced) are PLAN (Programming Languages) with 4% female, and OPS (operating systems) with 5% female.

The figures for SIGMM show 9% female membership with 17% unknown or not declaring which means that among the declared members it is just below 11%. Among the other SIGs this makes us closest to AI (Artificial Intelligence) and to IR (Information Retrieval), though SIGIR has a larger number of members with gender undeclared.

Measuring this against overall ACM memberships we find that ACM members are 68% male, 12% female and 20% undeclared. This makes SIGMM quite mid-table compared to other SIGs, but we’re all doing badly and we all have an imbalance. Interestingly, the MULTMEDIA Conference in 2018 in Seoul, Korea had 81% male, 18% female and 1% other/undeclared attendees, slightly better than our memberships ratio but still not good.
3. Gender Balance at SIGMM Conferences
We [1] carried out a desk study for the 3 major SIGMM conferences, namely MULTIMEDIA with an average attendance of almost 800, the International Conference on Multimedia Retrieval (ICMR) with 230 attendees at the last conference and Multimedia Systems (MMSys) with about 130 attendees. For each of the last 5 years we trawled through the conference websites, extracting the names/affiliations of the organizing committees, the technical program committees and the invited keynote speakers. We did likewise for the SIGMM award winners. This required us determining gender for over 2,700 people and although there were duplicates as the same people can recur on the program committees for multiple years and over multiple conferences. Some of these were easy like “John” and “Susanne”, but these were few so for the others we searched for them on the web. If we were still searching after 5 minutes, we gave up. [2]
[1] This work was carried out by Agata Wolski, a Summer intern student, and I, during Summer 2018.
[2] The data gathered from this activity is available on request from alan.smeaton@dcu.ie
The figures for each of these annual conferences for a 5-year period for MULTIMEDIA, for a 4-year period for ICMR and for a 3-year period for MMSys, are shown in the following sequence of charts, first showing the percentages and then the raw numbers, for each conference.
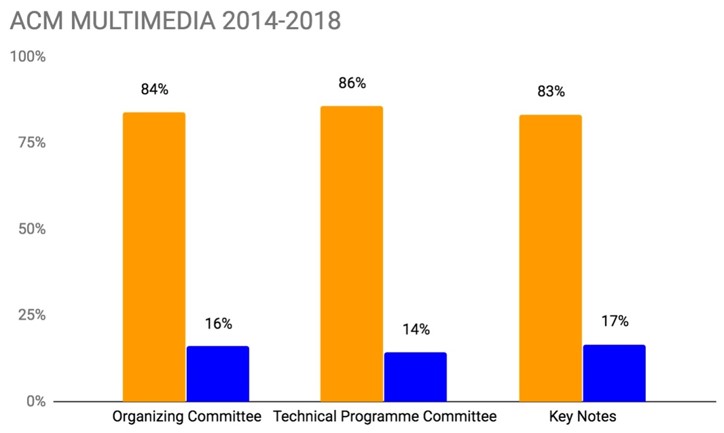

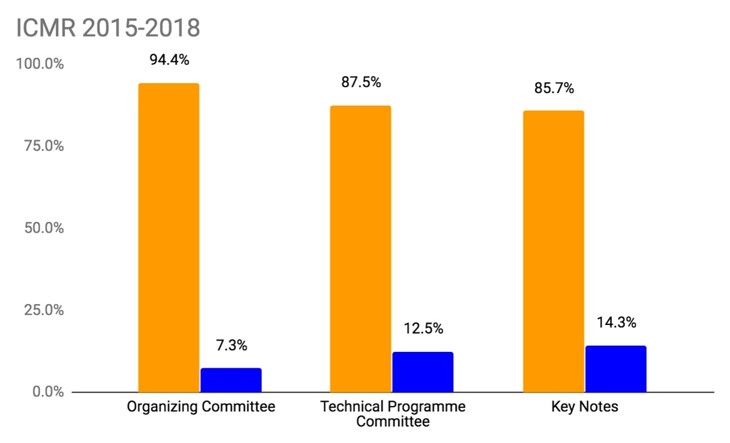

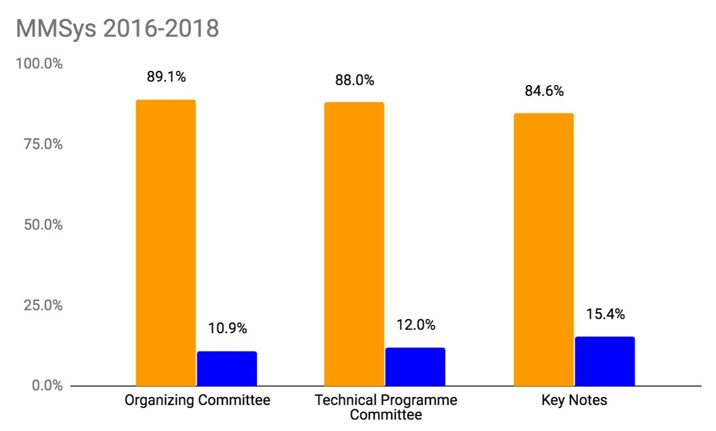

So what do the figures mean in comparison to each other and to our baseline?
The results tell us the following:
- Almost all the percentages for female participation in the organisation of all SIGMM conferences are above the SIGMM membership figure of 9% which is really closer to 11% when discounting those SIGMM members with gender unassigned yet we know the number of female SIGMM members is much already smaller compared to the 17% female in technology companies and the almost 18% female ACM members when discounting unassigned genders.
- Even if we were to use 17% to 18% figures as our baseline, our female participation in SIGMM conference organisation is less than that baseline, meaning our female SIGMM members are not appearing in organisational and committee roles as per our membership pro rates would indicate they should.
- While each of our conferences fall below these pro rata figures, none of the three conferences are particularly worse than the others.
4. Initiatives Elsewhere to Redress Gender Imbalance
I then examined some of the actions that are carried out elsewhere and that SIGMM could implement, and started by looking at other ACM SIGs. There I found that some of the other SIGs do some of the following:
- women and diversity events at conferences (breakfasts or lunches, like SIGMM does)
- Women-only networking pre-conference meals at conferences
- Women-only technical programme events like N2Women
- Formation of mentoring group (using Slack) for informal mentoring
- Highlighting the roles and achievements of women on social media and in newsletters
- Childcare and companion travel grants for conference attendance
I then looked more broadly at other initiatives and found the following:
- gender quotas
- accelerator programs like Athena Swan
- female-only events like workshops
- reports like this which act as spotlights
When we put these all together there are three recurring themes which appear across various initiatives:
- Networking .. encouraging us to be part of a smaller group within a larger group. This is a natural human trait of us being tribal, we like to belong to groups starting with our family but also the people we have lunch with, go to yoga classes with, go on holidays with, we each have multiple sometimes non-overlapping groups or tribes that we like to be part of. One such group is the network of minority/women that gets formed as a result of some of the activities.
- Peer-to-peer buddying .. again there is a natural human trait whereby older siblings (sisters) tend to help younger ones throughout life, from when we are very young and right throughout life. The buddying activity reflects this and gives a form of satisfaction to the older or senior buddy, as well as practical benefit to the younger or more junior buddy.
- Role models .. there are several initiatives which try to promote role models as those kinds of people that we ourselves can try to aspire to be. More often that not, it is the very successful people and the high flyers who are put into these positions of role models whereas in practice not everyone actually wants to aspire to be a high flyer. For many people success in their lives means something different, something less lofty and aspirational and when we see high flying successful people promoted as role models our reaction can be the opposite. We can reject them because we don’t want to be in their league and as a result we can feel depressed and regard ourselves as under-achievers, thus defeating the purpose of having role models in the first place.
5. SIGMM Women’s / Diversity Lunch at MULTIMEDIA 2018
At the ACM MULTIMEDIA Conference in Seoul, Korea in October 2018 SIGMM once again organised a women’s / diversity lunch and about 60 people attended, mostly women.

At the event I gave a high level overview of the statistics presented earlier in this report, and then in order to gather feedback from the audience we held a moderated discussion with PadLet used to gather feedback. PadLet is an online bulletin board used to display information (text, images or links) which can be contributed anonymously from an audience. Attendees at the lunch scanned a QR code on their smartphones which opened a browser and allowed them to post comments on the big screen in response to a topic being discussed during the meeting.
The first topic discussed was “What brings you to the MULTMEDIA Conference?”
- The answers (anonymous comments) posted included that many are here because they are presenting papers or posters, many want to do networking and to share ideas, to help build the community of like-minded researchers, some are attending in order to meet old friends .. and these are the usual reasons for attending a conference.
For the second topic we asked “What excites you about multimedia as a topic, how did you get into the area?”
- The answers included the interaction between computer vision and language, the novel applications around multimodality, the multidisciplinary nature and the practical nature of the subject, and the diversity of topics and the people attending.
The third topic was “What is more/less important for you … networking, role models or peer buddies?”
- From the answers to this, networking was almost universally identified as the most important, and as a follow-on from that, interacting with peers
Finally we asked “Do you know of an initiative that works, or that you would like to see at SIGMM event(s)?”
- A variety of suggestions were put forward including holding hackathons, funding undergraduate students from local schools to attend the conference, an ACM award for women only, ring-fenced funding for supporting women only, training for reviewing, and a lot of people wanted mentoring and mentor matching.
6. SIGMM Initiatives
So what will we do in SIGMM?
- We will continue to encourage networking at SIGMM sponsored conferences. We will fund lunches like the ones at the MULTIMEDIA Conference. We also started a newcomers breakfast at the MULTIMEDIA Conference in 2018 and we will continue with this.
- We will ensure that all our conference delegates can attend all conference events at all SIGMM conferences without extra fees. This was a SIGMM policy identified in a review of SIGMM conference some years ago but it has slipped.
- We will not force but we will facilitate peer-to-peer buddying through the networking events at our conferences and through this we will indirectly help you identify your own role models.
- We will appoint a diversity coordinator to oversee the women / diversity activities across our SIGMM events and this appointee will be a full member of the SIGMM Executive Committee.
- We will offer an opportunity for all members of our SIGMM community attending our sponsored conferences, as part of their conference registration, to indicate their availability and interest in taking on an organisational role in SIGMM activities, including conference organisation and/or reviewing. This will provide for us a reserve of people from whom we can draw on their expertise and their services and we can do so in a way which promotes diversity.
These may appear to be small-scale and relatively minor because we are not getting to the roots of what causes the bias and we are not inducing change to counter the causes of the bias. However these are positive steps, steps in the right direction, and we will now have the gender and other bias issues permanently on our radars.











{kind=link}
{kind=link}